今天上午被alphacode刷屏了,都在說以後找不到工作了,被激起了好奇心。粗略看一下這個工作。
論文的preprint在這兒:https:// storage.googleapis.com/ deepmind-media/AlphaCode/competition_level_code_generation_with_alphacode.pdf
背景
alphacode 這個工作主要是提出一個方法,可以生成程式碼用於 codeforce 的題目。類似的工作近幾年有不少,比如 Evaluating large language models trained on code,Program synthesis with large language models。alphacode 的區別在於它是在競賽任務上做的,並且精度不錯。
方法
方法不復雜,paper裏面這張圖概括得很好,分為4個步驟
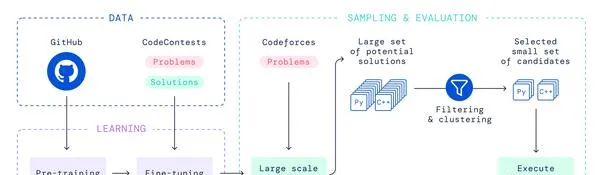
- pretrain:在github的數據集上做pretrain。模型就是BERT,pretrain方法也差不多。
- fine-tune:在 codeforce 數據集上做 fine-tune,這個模型是標準的基於 transformer 的 encoder-decoder 結構,encoder輸入是題目的描述(也包括:題目的tags、solution使用的語言、題目中的樣例),decoder的輸出對應的ground-truth是一個solution,可以是對的,也可以是錯的。
- 用訓練完的模型 sample 大量的 solution 出來,並且做過濾和聚類。過濾是為了去掉無法透過樣例的程式碼(會幹掉絕大部份),聚類是為了讓實作不同但輸出相同的程式碼只送出一次(節約送出的budget)。聚類中,還需要一個獨立訓練的生成測試數據的模型。這個步驟是針對競賽題設計的,從這個步驟看,直接用生成的程式碼直接run錯誤的機率很高。
- 從聚類最大的類開始挑選,選出10個solution來送出。
註意 :alphacode 並不像 alphazero/master 一樣在environment(對於alphacode來說是 codeforce 平台)上反復試錯,它只是收集歷史比賽數據做訓練。
幾個重要技巧
- Tempering:訓練的時候在 logit 之後調整 temperature,它是往小於1去調,具體方法如下。
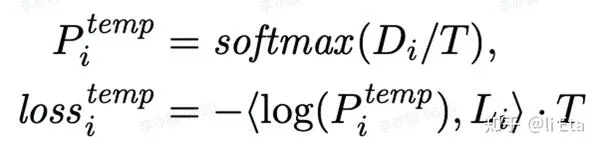
2. Value conditioning & prediction:在 encoder 的輸入中,補充很多資訊,比如:RATING、TAGS、solution的語言、solution是否是正確的。註意:在 sample 環節的時候TAGS、語言可以用於提升多樣性,solution 則都填「正確」。例子如下圖所示。

3. GOLD:loss 選擇 policy gradient 的 loss,物理意義上是希望一個 solution 能從否到尾都是正確的,而不是前一半對後一半錯(競賽中對一半其實就是錯),也就是為了讓模型更加focus在準確(precision)而非召回(recall)。
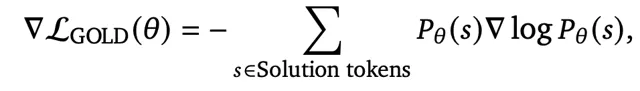
實驗可以看原文,而且很多公眾號上來就貼了實驗結果,不再贅述。
總結
- 總體來看,方法並不驚艷,甚至沒有用 codeforce 平台離線反復送出獲取更多訓練數據的環節,只是用了歷史數據。
- 這個實驗結果,不確定和 codeforce 本身會有一些重復題目有沒有關系(論文裏面做了一些對比來觀察模型是否是復制貼上訓練集,但不能完全回答這個問題)。
- 非常針對 codeforce 競賽題的機制來做了獨特設計(尤其是采樣和選擇子集的部份),距離通用程式碼生成還比較遠(比如1-2年?)。
- 套用場景:簡單的程式碼任務,取代一部份人工。但有個疑問,如果 ML 方法可以生成正確執行的程式碼了,那為什麽不用這個方案直接解決問題,完全可以跳過程式碼生成的步驟。











