本篇文章是 OpenAI ChatGPT 系列文章的第三篇,在之前的文章中,我們已經介紹了基礎模組 Transformer 的結構和程式碼實作。
GPT 系列是 OpenAI 的一系列預訓練模型,GPT 的全稱是 Generative Pre-Trained Transformer,顧名思義,GPT 的目標是透過 Transformer,使用預訓練技術得到通用的語言模型。目前已經公布論文的有 GPT-1、GPT-2、GPT-3。
最近非常火的 ChatGPT 也是 GPT 系列模型,主要基於 GPT-3.5 進行微調。OpenAI 團隊在 GPT3.5 基礎上,使用人類反饋強化學習 (RLHF) 訓練。首先使用了人類標註師撰寫約1.2w-1.5w條問答數據,並用其作為基礎數據預訓練。隨後讓預訓練好的模型(SFT)針對新問題列表生成若幹條回答,並讓人類標註師對這些回答進行排序。這些回答的排名內容將以配對比較的方式生成一個新的獎勵模型(RM)。最後讓獎勵模型在更大的數據集上重新訓練SFT,並將最後兩個步驟反復叠代以獲得最終的模型。
ChatGPT 本質上是基於 Transformer 的語言模型,在之前的文章中,我們已經詳細介紹了 Transformer 的原理和程式碼實作,這篇文章文章開始,我們將逐一介紹 GPT 系列模型的技術。
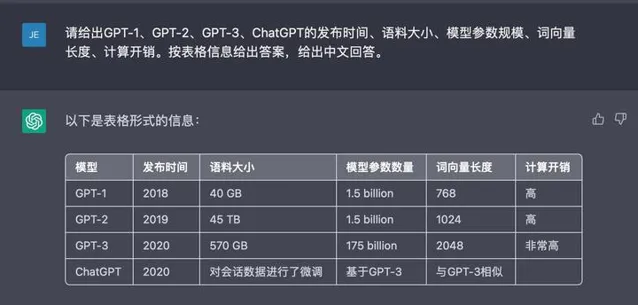
在介紹 GPT-1 之前,我們先讓 ChatGPT 幫我們回答下 GPT 系列模型的基礎資訊,如下圖所示。
前言
GPT-1 是 OpenAI 在論文 Improving Language Understanding by Generative Pre-Training 中提出的生成式預訓練語言模型。該模型的核心思想:透過二段式的訓練,第一個階段是利用語言模型進行預訓練(無監督形式),第二階段透過 Fine-tuning 的模式解決下遊任務(監督模式下)。GPT-1 可以很好地完成若幹下遊任務,包括文本分類、文本蘊含、語意相似度、問答。在多個下遊任務中,微調後的 GPT-1 系列模型的效能均超過了當時針對特定任務訓練的 SOTA 模型。
備註: 文本蘊含(Textual entailment)是指兩個文本片段有指向關系。給定一個前提文本,根據這個前提去推斷假說文本與前提文本的關系,一般分為蘊含關系(entailment)和矛盾關系(contradiction),蘊含關系表示從前提文本中可以推斷出假說文本;矛盾關系即前提文本與假說文本矛盾。
1. GPT-1 模型結構
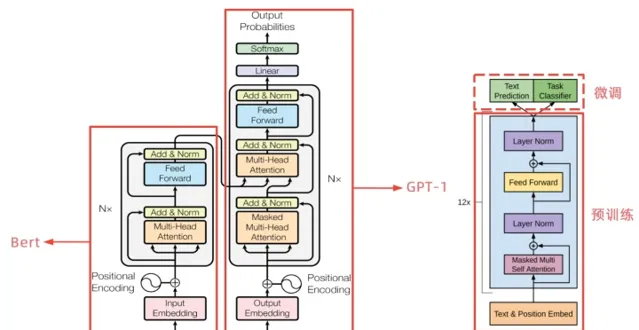
從上圖可以看出,GPT-1 只使用了 Transformer 的 Decoder 結構,而且只是用了 Mask Multi-Head Attention。
Transformer 結構提出是用於機器轉譯任務,機器轉譯是一個序列到序列的任務,因此 Transformer 設計了Encoder 用於提取源端語言的語意特征,而用 Decoder 提取目標端語言的語意特征,並生成相對應的譯文。GPT-1 目標是服務於單序列文本的生成式任務,所以舍棄了關於 Encoder 部份以及包括 Decoder 的 Encoder-Dcoder Attention 層(也就是 Decoder中 的 Multi-Head Atteion)。
GPT-1 保留了 Decoder 的Masked Multi-Attention 層和 Feed Forward 層,並擴大了網路的規模。將層數擴充套件到12層,GPT-1 還將Attention 的維數擴大到768(原來為512),將 Attention 的頭數增加到12層(原來為8層),將 Feed Forward 層的隱層維數增加到3072(原來為2048),總參數達到1.5億。
將預訓練和 Fine-tuning 結合起來,GPT-1 的結構可以用下面的圖表示:
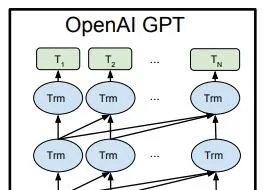
圖中最下層 E 表示輸入句子單詞的 Embedding,中間的 Trm 表示 GPT 的單層 Transformer,最上層的 T 表示預測輸出。
除了上面提到的,GPT-1 的 Transformer 結構還有哪些差異?
Q1:GPT-1 采用的是單向的語言模型?
A1:在 GPT 中采用了 Masked Multi-Head Attention,而 Masked Multi-Head Attention 只利用上文對當前位置的值預測,所以 GPT-1 被認為是單向的語言模型。
Q2:GPT-1 中 Position Encoding 的操作有何不同?
A2:在 Transformer 中,由於 Self-Attention 無法捕獲文本的位置資訊,因此需要對輸入的詞 Embedding 加入Position Encoding,在 Transformer 中采用了 sin 和 cos 的計算方法,而在 GPT-1 中,不再使用正弦和余弦的位置編碼,而是采用與詞向量相似的隨機初始化,並在訓練中進行更新。
從圖1的最右側可以看到,GPT-1 的訓練包含兩階段,第一階段是 GPT-1 模型的預訓練過程,得到文本的語意向量;第二階段是在具體任務上 Fine-tuning,以解決具體的下遊任務。
2. 第一階段:無監督預訓練
對於 GPT-1 模型的預訓練,同樣采用標準語言模型,即透過上文預測當前的詞,目標函式表示如下:
L_1\left( \mathcal{U} \right)=\sum_{i}\text{log}P\left( u_i|u_{i-k},...,u_{i-1};\theta \right)\tag1 其中 k 是視窗大小。
GPT-1 使用了12個 Transformer 模組,這裏的 Transformer 模組是圖1經過變體後的結構,只包含 Decoder 中的Mask Multi-Head Attention 以及後面的 Feed Forward,表示如下:
\begin{align} h_0 & = UW_e+W_p\\ h_l & = \text{transformer_block}\left( h_{l-1} \right) \forall i\in\left[ 1,n \right]\\ P\left( u \right) & = \text{softmax}\left( h_nW_e^T \right) \end{align} \tag2 其中 U=\left( u_{-k},...,u_{-1} \right) 是當前單詞 u 的上文單詞向量(比如[3222, 439, 150, 7345, 3222, 439, 6514, 7945],其中數位3222是詞在此表中的索引), W_e 是詞向量矩陣 (詞的 Embedding 矩陣), W_P 是 position embedding, n 是 Transformer 層數。
3. 第二階段:有監督 Fine-tuning
在 GPT-1 模型的下遊任務中,需要根據 GPT-1 的網路結構,對下遊任務做適當的修改,具體如下圖所示:
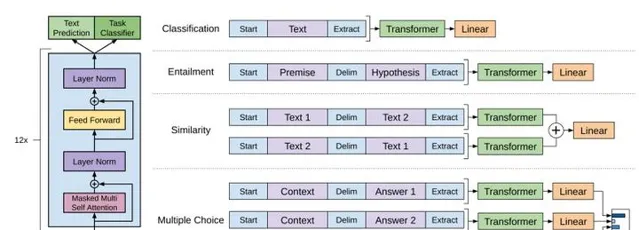
假設帶有標簽的數據集為 \mathcal{C} ,其中,詞的序列為 x^1,\cdots ,x^m ,標簽為 y 。詞序列輸入到預訓練好的 GPT-1 模型中,經過最後一層 Transformer block 得到輸出 h_l^m ,然後輸入到下遊任務的線性層中,得到最終的預測輸出:
P\left( y|x^1,...,x^m \right)=\text{softmax}\left( h_l^mW_y \right)\tag3 此是目標函式為:
L_2\left( \mathcal{C} \right)=\sum_{\left( x,y \right)}\text{log}P\left( y|x^1,...,x^m \right)\tag4 合並之前的預訓練目標函式,最終的目標函式表示如下:
L_3\left( \mathcal{C} \right)=L_2\left( \mathcal{C} \right)+\lambda L_1\left( \mathcal{C} \right)\tag5
4. 不同下遊任務的輸入轉換
針對不同的下遊任務,需要對輸入進行轉換,從而能夠適應 GPT-1 模型結構,比如:




5. 程式碼實作
在之前的一篇文章中,我們已經完整的實作了 Transformer,有了這個基礎後,實作 GPT-1 就容易很多,大家可以去看一下 Transformer 的程式碼實作。
我們看一下ChatGPT是怎麽實作的:
有個大致的流程,但是這裏面沒有體現出 GPT-1 的核心部份:Mask Multi-Head Attention,下一篇文章我們介紹具體的程式碼實作,並給一個具體的例子,方便大家理解。
總結
GPT-1 是2018年6月提出的模型,比 Bert 還早幾個月,當時在9個NLP任務上取得了 SOTA 的效果,但 GPT-1 使用的模型規模和數據量都比較小,這也就促使了 GPT-2 的誕生。
參考
絕密伏擊:OPenAI ChatGPT(一):Tensorflow實作Transformer
絕密伏擊:OPenAI ChatGPT(一):十分鐘讀懂Transformer
大師兄:ChatGPT/InstructGPT詳解
felixzhao:GPT:Generative Pre-Training
難賦:論文筆記:Improving Language Understanding by Generative Pre-Training
loomstar:GPT1--【Improving Language Understanding by Generative Pre-Training】
Ph0en1x:Transformer結構及其套用詳解--GPT、BERT、MT-DNN、GPT-2
https://www. cs.ubc.ca/~amuham01/LIN G530/papers/radford2018improving.pdf
書籍推薦










