本篇文章是 ChatGPT 系列文章的最後一篇。在之前的文章中,依次介紹了 Transformer->GPT1->GPT2->GPT3 ,下面是參考連結:
如果你已經看過上面的文章,那麽理解 ChatGPT 的技術原理就簡單的多。
實際上 OpenAI 並沒有公布 ChatGPT 的技術細節,但是在2022年的時候,曾經放出過 InstructGPT 的論文(Training language models to follow instructions with human feedback),而根據 OpenAI 的說法,ChatGPT 是 InstructGPT 的兄弟模型。
我們透過下面的圖,也可以看出 ChatGPT 和 InstructGPT 之間的關系。
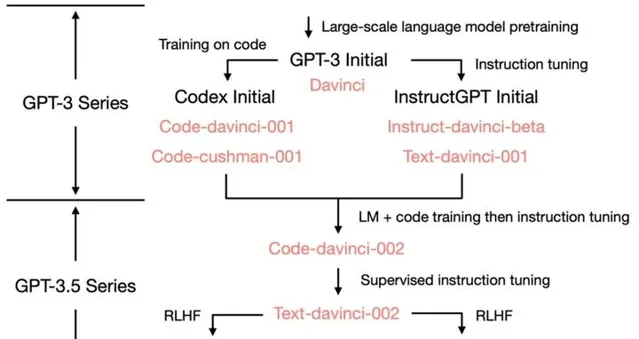
本篇文章,我們一起來了解一下 ChatGPT 背後的技術原理。
GPT-3有什麽問題?
既然 ChatGPT 是由 GPT-3 叠代過來的,那麽原有的 GPT-3 究竟有哪些問題?ChatGPT 又是如何做的改進?
如果你明白了上面兩個問題,那麽 ChatGPT 的核心你就算真正掌握了。
GPT-3 最大的問題就是訓練目標和使用者意圖不一致 。也就是 GPT-3 並沒有真正擬合使用者真實的問題(prompt)。
GPT-3 本質上是語言模型,最佳化目標也是標準語言模型的目標,即最大化下一個詞出現的機率。GPT-3 的核心技術是 Next-token-prediction 和 Masked-language-modeling。
在第一種方法中,模型被給定一個詞序列作為輸入,並被要求預測序列中的下一個詞。如果為模型提供輸入句子:
「貓坐在」它可能會將下一個單詞預測為「墊子」、「椅子」或「地板」,因為在前面的上下文中,這些單詞出現的機率很高。
Masked-language-modeling 方法是 Next-token-prediction 的變體,其中輸入句子中的一些詞被替換為特殊 token,例如 [MASK]。然後,模型被要求預測應該插入到 mask 位置的正確的詞。如果給模型一個句子:
「The [MASK] sat on the 」它可能會預測 MASK 位置應該填的詞是「cat」、「dog」。
這些目標函式的優點之一是,它允許模型學習語言的統計結構,例如常見的詞序列和詞使用模式。這通常有助於模型生成更自然、更流暢的文本,並且是每個語言模型預訓練階段的重要步驟。
然而這些目標函式也可能導致問題,這主要是因為模型無法區分重要錯誤和不重要錯誤。一個非常簡單的例子是,如果給模型輸入句子:
"羅馬帝國[MASK]奧古斯都的統治"它可能會預測 MASK 位置應該填入「開始於」或「結束於」,因為這兩個詞的出現機率都很高。
更一般地說,這些訓練策略可能會導致語言模型在某些更復雜的任務中出現偏差,因為僅經過訓練以預測文本序列中的下一個詞(或掩碼詞)的模型可能不一定會學習 一些其含義的更高層次的表示 。因此,該模型難以泛化到需要更深入地理解語言的任務或上下文。
這也導致了 GPT-3 這樣的語言模型, 很難理解使用者的真實意圖,經常出現答非所問的情況,一本正經的胡說八道 。
因此 ChatGPT 要解決的核心問題,就是怎麽讓模型和使用者對齊。
備註: 模型和使用者對齊。就是讓模型學會理解人類的命令指令的含義(比如給我寫一段小作文生成類問題、知識回答類問題、頭腦風暴類問題等不同型別的命令),以及讓模型學會判斷對於給定 prompt 輸入指令(使用者的問題),什麽樣的答案是優質的(富含資訊、內容豐富、對使用者有幫助、無害、不包含歧視資訊等多種標準)。
那麽 ChatGPT 又是如何做的改進?核心方法就是引入「人工標註數據+強化學習」(RLHF,Reinforcement Learning from Human Feedback ,這裏的人工反饋其實就是人工標註數據)來不斷Fine-tune預訓練語言模型。
在「人工標註數據+強化學習」框架下,訓練 ChatGPT 主要分為三個階段。
後面我們會詳細介紹上面的三個階段。
這裏有一個疑問,為啥不直接使用 SFT,而是又要引入強化學習?
這個問題非常重要。強化學習的目的是讓模型的答案更接近人類意圖,本階段無需人工標註數據,而是利用上一階段學好的 RM 模型,靠 RM 打分結果來更新預訓練模型參數。
既然目標是讓模型能更好擬合<prompt, answer>,那為什麽不直接使用 SFT,這樣不是更直接嗎?或者為了擬合<prompt, answer1, answer2,...>這個序,再做一次 Fine-tuning。
之所以沒有這樣做,主要原因還是標註數據太少了,一共才3萬條標註數據。換句話說,如果標註數據足夠多,有可能 SFT 就足夠了。
那麽怎麽能獲取更多 prompt?就像 OpenAI 一樣,快速推出產品 ChatGPT,然後不斷收集使用者的 prompt,再把收集的數據用於 SFT。這也是為什麽 ChatGPT 越來越強,因為它在不斷的收集->訓練->收集...

ChatGPT 技術原理
在「人工標註數據+強化學習」框架下,具體而言,ChatGPT 的訓練過程分為以下三個階段:
階段一:有監督微調Supervised fine-tuning (SFT)
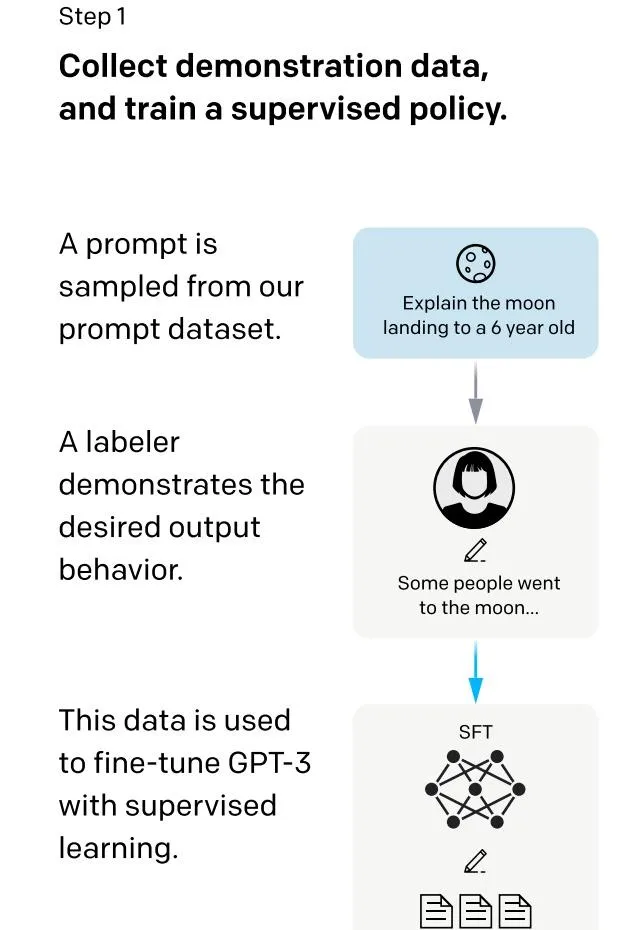
為了讓 ChatGPT 初步具備理解指令中(prompt)蘊含的意圖,首先會從測試使用者送出的 prompt (就是指令或問題)中隨機抽取一批,靠專業的標註人員,給出指定 prompt 的高品質答案,然後用這些人工標註好的<prompt, answer> 數據來 Fine-tune GPT-3 模型。經過這個過程,我們可以認為 ChatGPT 初步具備了理解人類 prompt 中所包含意圖,並根據這個意圖給出相對高品質回答的能力,但是由於樣本太少,很難達到理想效果。
我們來看一下這部份標註數據都有哪些問題:
| 問題型別 | 占比(%) |
|---|---|
| 生成任務(Generation) | 45.6% |
| 開放問答(Open QA) | 12.4% |
| 頭腦風暴(Brainstorming) | 11.2% |
| 聊天(Chat) | 8.4% |
| 重寫(Rewrite) | 6.6% |
| 摘要(Summarization) | 4.2% |
| 分類( classification) | 3.5% |
| 其它(Other) | 3.5% |
| 封閉問答(Closed QA) | 2.6% |
| 抽取(Extract) | 1.9% |
這裏面最主要的問題是生成任務,然後是一些問答,頭腦風暴。下面看幾個例子:
| 問題型別 | Prompt |
|---|---|
| 頭腦風暴(Brainstorming) | 列出5個方法用於重新對職業充滿熱情 |
| 生成任務(Generation) | 編寫一個短篇故事,講述一只熊前往海灘,結識了一只海豹,然後返回家中的經歷。 |
| 重寫(Rewrite) |
將下面一段話轉譯成法語:
<English sentence> |
SFT 就是根據這些問題和答案,對 GPT-3 進行微調。
階段二:訓練報酬模型(Reward Model, RM)
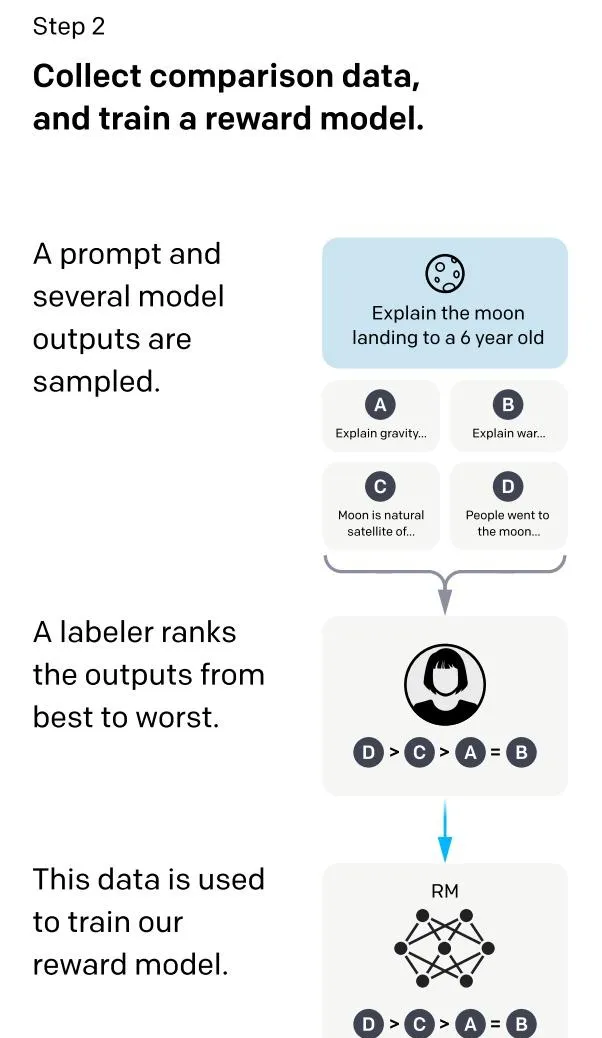
這個階段的主要目的是透過人工標註訓練數據,來訓練報酬模型。具體而言,隨機抽樣一批使用者送出的 prompt (大部份和第一階段的相同),使用第一階段 Fine-tune 好的模型,對於每個 prompt,由之前的 SFT 模型生成 K 個不同的回答,於是模型產生出了<prompt, answer1>, <prompt, answer2>….<prompt, answerK>數據(這裏面 K 是4到9之間)。之後,標註人員對 K 個結果按照很多標準(上面提到的相關性、富含資訊性、有害資訊等諸多標準)綜合考慮進行排序,給出 K 個結果的排名順序,這就是此階段人工標註的數據。
接下來,我們準備利用這個排序結果數據來訓練報酬模型,采取的訓練模式其實就是平常經常用到的 pair-wise learning to rank。對於K個排序結果,兩兩組合,形成\binom{k}{2} 個訓練數據對,ChatGPT 采取 pair-wise loss 來訓練報酬模型。RM 模型接受一個輸入<prompt, answer>,給出評價回答品質高低的報酬分數 Score。對於一對訓練數據<answer1, answer2>,我們假設人工排序中 answer1 排在 answer2 前面,那麽 Loss 函式則鼓勵 RM 模型對<prompt, answer1> 的打分要比 <prompt, answer2> 的打分要高。
下面是報酬模型的損失函式:
\text{loss}\left( \theta \right)=-\frac{1}{\binom{k}{2}}E_{\left( x,y_w,y_l \right)\sim D}\left[ \text{log}\left( \sigma\left( r_{\theta}\left( x,y_w \right)-r_{\theta}\left( x,y_l \right) \right) \right) \right]\tag1 其中 r_{\theta}\left( x,y \right) 表示報酬模型的輸出, x 是給定的 prompt, y 表示對於的回答。 y_w 和 y_l 表示回答 w 排在回答 l 前面 ,類似上面的 answer1 排在 answer2 前面。
總結下:在這個階段裏,首先由 SFT 監督模型為每個 prompt 產生 K 個結果,人工根據結果品質由高到低排序,以此作為訓練數據,透過 pair-wise learning to rank 模式來訓練報酬模型。對於學好的 RM 模型來說,輸入<prompt, answer>,輸出結果的品質得分,得分越高說明產生的回答品質越高。
階段三:使用強化學習微調 SFT 模型
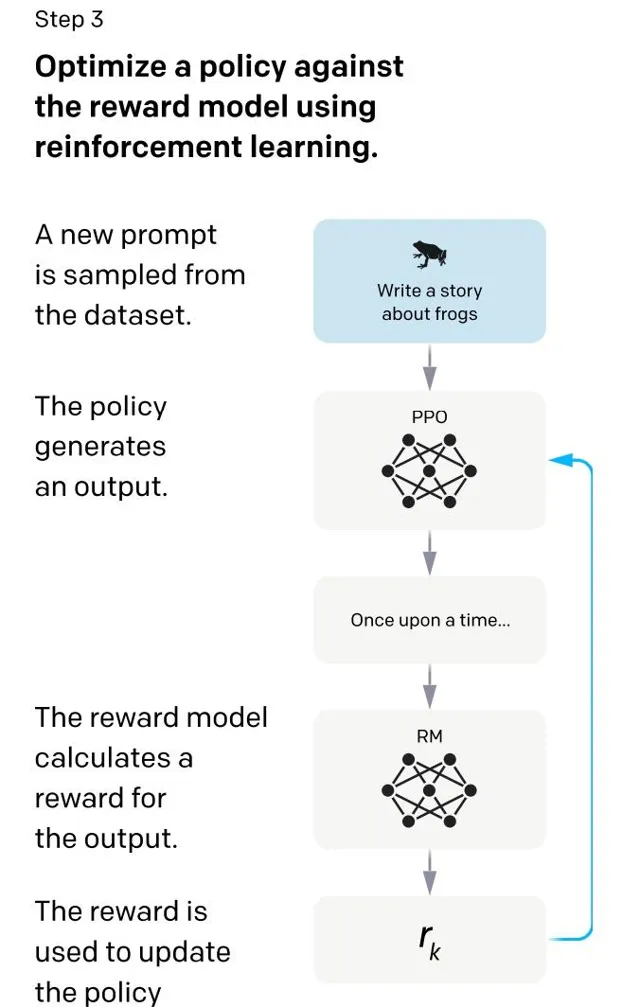
本階段無需人工標註數據,而是利用上一階段學好的 RM 模型,靠 RM 打分結果來更新預訓練模型參數。具體而言,首先,從使用者送出的 prompt 裏隨機采樣一批新的命令(指的是和第一第二階段不同的新的 prompt),且由一階段的 SFT 模型來初始化 PPO 模型的參數。然後,對於隨機抽取的 prompt,使用 PPO 模型生成回答answer, 並用上一階段訓練好的 RM 模型給出 answer 品質評估的報酬分數 score,這個報酬分數就是 RM 賦予給整個回答的整體 reward。
強化學習的目標函式如下:
\text{object}\left( \phi \right)=E_{\left( x,y\right)\sim D_{\pi _{\phi}^{RL}}}\left[ r_{\theta}\left( x,y \right)-\beta\space \text{log}\left( \pi _{\phi}^{RL}\left( y|x \right)/\pi^{SFT}\left( y|x \right) \right) \right]+\gamma E_{x\sim D_{\text{pretrain}}}\left[ \text{log}\left( \pi _{\phi}^{RL}\left( x \right) \right) \right]\tag2 這裏面第一項是最大化報酬 score,第二項是讓強化學習的輸出不要偏離 SFT 太多,最後一項是保證微調的同時,原有語言模型的效果不會變差。
效果評估
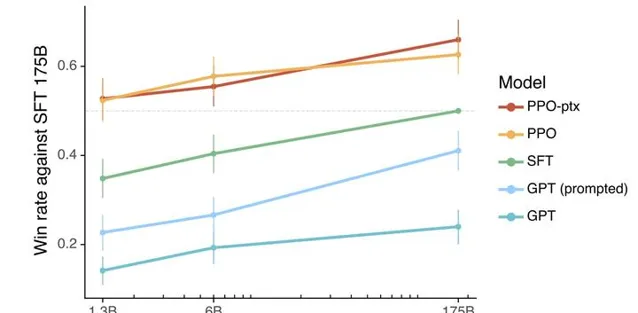
上圖是最終的效果對比。對比的是 SFT 175B 的GPT-3 模型。可以看到只做 SFT,1.3B 和 6B 都幹不過 175B,但是加入強化學習後,1.3B 的效果就比 175B 的效果還好。
總結
GPT 出來之後,基於 GPT 架構的大模型層出不窮,比較知名的有清華大學的 GLM ( General Language Model Pretraining )模型,百度的文心一言。而後面騰訊、阿裏、字節、知乎,都會推出自己的大模型,這些大模型用的數據可能不一樣,但是有一樣是共同的:都是基於 GPT 進行預訓練。

目前 ChatGPT 的相關技術已經介紹完了,而目前 OpenAI 已經推出了最新版本的 GPT-4,支持多模態,可以理解圖片,後面應該會加入視訊理解。
AI 的時代,真的來臨了。
參考
Introducing ChatGPT
https:// arxiv.org/pdf/2203.0215 5.pdf
張俊林:ChatGPT會取代搜尋引擎嗎
機器之心:深入淺出,解析ChatGPT背後的工作原理
數據科學人工智慧:ChatGPT 演算法原理
How ChatGPT actually works
JioNLP團隊:一文讀懂ChatGPT模型原理
書籍推薦










