2018圖靈獎獲得者Yoshua Bengio, Yann LeCun和Geoffrey Hinton再次受ACM邀請共聚一堂,共同回顧了深度學習的基本概念和一些突破性成果,講述了深度學習的起源、發展及未來的發展面臨的挑戰。
2018年,ACM(國際電腦學會)決定將電腦領域的最高獎項圖靈獎頒給Yoshua Bengio、Yann LeCun 和 Geoffrey Hinton,以表彰他們在電腦深度學習領域的貢獻。

這也是圖靈獎第三次同時頒給三位獲獎者。
用於電腦深度學習的人工神經網路在上世紀80年代就已經被提出,但是在當時科研界由於其缺乏理論支撐,且計算力算力有限,導致其一直沒有得到相應的重視。
是這三巨頭一直在堅持使用深度學習的方法,並在相關領域進行了深入研究。透過實驗發現了許多驚人的成果,並為證明深度神經網路的實際優勢做出了貢獻。
所以說他們是 深度學習之父 毫不誇張。
在AI界,當Yoshua Bengio、Yann LeCun 和 Geoffrey Hinton 這三位大神同時出場的時候,一定會有什麽大事發生。
最近,深度學習三巨頭受ACM通訊雜誌之邀,共同針對深度學習的話題進行了一次深度專訪,提綱挈領地回顧了深度學習的 基本概念、最新的進展,以及未來的挑戰。
廣大的AI開發者們,看了高人指點之後是不是對於未來之路更加明晰了?下面我們來看看他們都聊了些什麽。
深度學習的興起
在2000年代早期,深度學習引入的一些元素,讓更深層的網路的訓練變得更加容易,也因此重新激發了神經網路的研究。

GPU和大型數據集的可用性是深度學習的關鍵因素,也得到了具有自動區分功能、開源、靈活的軟體平台(如Theano、Torch、Caffe、TensorFlow等)的增強作用。訓練復雜的深度網路、重新使用最新模型及其構建塊也變得更加容易。而更多層網路的組合允許更復雜的非線性,在感知任務中取得了意料之外的結果。

深度學習深在哪裏?有人認為,更深層次的神經網路可能更加強大,而這種想法在現代深度學習技術出現之前就有了。但是,這樣的想法其實是由架構和訓練程式的不斷進步而得來的,並帶來了與深度學習興起相關的顯著進步。
更深層的網路能夠更好地概括「輸入-輸出關系型別」,而這不僅只是因為參數變多了。深度網路通常比具有相同參數數量的淺層網路具有更好的泛化能力。例如,時下流行的電腦視覺摺積網路架構類別是ResNet系列,其中最常見的是ResNet-50,有50層。
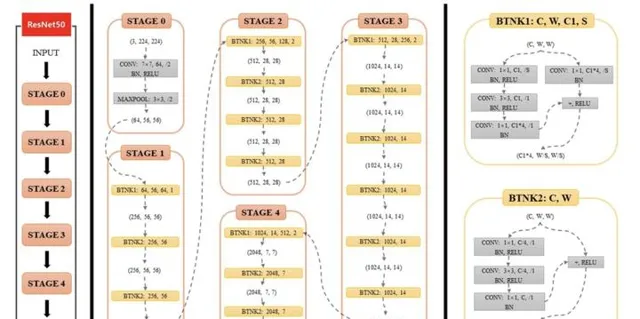
圖源:知乎@臭鹹魚
深度網路之所以能夠脫穎而出,是因為它利用了一種特定形式的組合性,其中一層的特征以多種不同的方式組合,這樣在下一層就能夠建立更多的抽象特征。
無監督的預訓練。 當標記訓練範例的數量較小,執行任務所需的神經網路的復雜性也較小時,能夠使用一些其他資訊源來建立特征檢測器層,再對這些具有有限標簽的特征檢測器進行微調。在遷移學習中,資訊源是另一種監督學習任務,具有大量標簽。但是也可以透過堆疊自動編碼器來建立多層特征檢測器,無需使用任何標簽。

線性整流單元的成功之謎。 早期,深度網路的成功,是因為使用了邏輯sigmoid非線性函式或與之密切相關的雙曲正切函式,對隱藏層進行無監督的預訓練。
長期以來,神經科學一直假設線性整流單元,並且已經在 RBM 和摺積神經網路的某些變體中使用。讓人意想不到的是,人們驚喜地發現,非線性整流透過反向傳播和隨機梯度下降,讓訓練深度網路變得更加便捷,無需進行逐層預訓練。這是深度學習優於以往物件辨識方法的技術進步之一。
語音和物體辨識方面的突破。 聲學模型將聲波轉換為音素片段的機率分布。Robinson、Morgan 等人分別使用了晶片機和DSP芯片,他們的嘗試均表明,如果有足夠的處理能力,神經網路可以與最先進的聲學建模技術相媲美。

2009年,兩位研究生使用 NVIDIA GPU ,證明了預訓練的深度神經網路在 TIMIT 數據集上的表現略優於 SOTA。這一結果重新激起了神經網路中幾個主要語音辨識小組的興趣。2010 年,在不需要依賴說話者訓練的情況下,基本一致的深度網路能在大量詞匯語音辨識方面擊敗了 SOTA 。2012 年,谷歌顯著改善了 Android 上的語音搜尋。這是深度學習顛覆性力量的早期證明。
大約在同一時間,深度學習在 2012 年 ImageNet 競賽中取得了戲劇性的勝利,在辨識自然影像中的一千種不同類別的物體時,其錯誤率幾乎減半。這場勝利的關鍵在於,李飛飛及其合作者為訓練集收集了超過一百萬張帶標簽的影像,以及Alex Krizhevsky 對多個 GPU 的高效使用。

深度摺積神經網路具有新穎性,例如,ReLU能加快學習,dropout能防止過度擬合,但它基本上只是一種前饋摺積神經網路,Yann LeCun 和合作者多年來一直都在研究。
電腦視覺社群對這一突破的反應令人欽佩。證明摺積神經網路優越性的證據無可爭議,社群很快就放棄了以前的手工設計方法,轉而使用深度學習。
深度學習近期的主要成就
三位大神選擇性地討論了深度學習的一些最新進展,如 軟註意力(soft attention) 和 Transformer 架構。
深度學習的一個重大發展,尤其是在順序處理方面,是 乘法互動 的使用,尤其是軟註意力的形式。這是對神經網路工具箱的變革性補充,因為它將神經網路從純粹的向量轉換機器,轉變為能夠動態選擇對哪些輸入進行操作的架構,並且將資訊儲存在關聯記憶體中。這種架構的關鍵特性是,它們能有效地對不同型別的數據結構進行操作。
軟註意力可用於某一層的模組,可以動態選擇它們來自前一層的哪些向量,從而組合,計算輸出。這可以使輸出獨立於輸入的呈現順序(將它們視為一組),或者利用不同輸入之間的關系(將它們視為圖形)。

Transformer 架構已經成為許多套用中的主導架構,它堆疊了許多層「self-attention」模組。同一層中對每個模組使用純量積來計算其查詢向量與該層中其他模組的關鍵向量之間的匹配。匹配被歸一化為總和1,然後使用產生的純量系數來形成前一層中其他模組產生的值向量的凸組合。結果向量形成下一計算階段的模組的輸入。

模組可以是多向的,以便每個模組計算幾個不同的查詢、鍵和值向量,從而使每個模組有可能有幾個不同的輸入,每個輸入都以不同的方式從前一階段的模組中選擇。在此操作中,模組的順序和數量無關緊要,因此可以對向量集進行操作,而不是像傳統神經網路中那樣對單個向量進行操作。例如,語言轉譯系統在輸出的句子中生成一個單詞時,可以選擇關註輸入句子中對應的一組單詞,與其在文本中的位置無關。
未來的挑戰
深度學習的重要性以及適用性在不斷地被驗證,並且正在被越來越多的領域采用。對於深度學習而言,提升它的效能表現有簡單直接的辦法——提升模型規模。
透過更多的數據和計算,它通常就會變得更聰明。比如有1750億參數的GPT-3大模型(但相比人腦中的神經元突觸而言仍是一個小數目)相比只有15億參數的GPT-2而言就取得了顯著的提升。

但是三巨頭在討論中也透露到,對於深度學習而言仍然存在著靠提升參數模型和計算無法解決的缺陷。
比如說與人類的學習過程而言,如今的機器學習仍然需要在以下幾個方向取得突破:
1、監督學習需要 太多的數據標註 ,而無模型強化學習又需要太多試錯。對於人類而言,像要學習某項技能肯定不需要這麽多的練習。

2、如今的系統對於分布變化適應的 魯棒性比人類差的太遠 ,人類只需要幾個範例,就能夠快速適應類似的變化。
3、如今的深度學習對於感知而言無疑是最為成功的,也就是所謂的系統1類任務,如何透過 深度學習進行系統2類任務 ,則需要審慎的通用步驟。在這方面的研究令人期待。
在早期,機器學習的理論學家們始終關註於獨立相似分布假設,也就是說測試模型與訓練模型服從相同的分布。而不幸的是,在現實世界中這種假設並不成立:比如說由於各種代理的行為給世界帶來的變化,就會引發不平穩性;又比如說總要有新事物去學習和發現的學習代理,其智力的界限就在不斷提升。
所以現實往往是即便如今最厲害的人工智慧,從實驗室投入到實際套用中時,其 效能仍然會大打折扣 。
所以三位大神對於深度學習未來的重要期待之一,就是當分布發生變化時能夠迅速適應並提升魯棒性(所謂的不依賴於分布的泛化學習),從而在面對新的學習任務時能夠降低樣本數量。
如今的監督式學習系統相比人類而言,在學習新事物的時候需要更多的事例,而對於無模型強化學習而言,這樣的情況更加糟糕——因為相比標註的數據而言,獎勵機制能夠反饋的資訊太少了。
所以,我們該如何設計一套全新的機械學習系統,能夠面對分布變化時具備更好的適應力呢?
從同質層到代表實體的神經元組
如今的證據顯示,相鄰的神經元組可能代表了更高級別的向量單元,不僅能夠傳遞純量,而且能夠傳遞一組座標值。這樣的想法正是膠囊架構的核心,在單元中的元素與一個向量相關聯,從中可以讀取關鍵向量、數值向量(有時也可能是一個查詢向量)。

適應多個時間尺度
大多數神經網路只有兩個時間尺度:權重在許多範例中適應得非常慢,而行為卻在每個新輸入中對於變化適應得非常快速。透過添加快速適應和快速衰減的「快速權重」的疊加層,則會讓電腦具備非常有趣的新能力。
尤其是它建立了一個高容量的短期儲存,可以允許神經網路執行真正的遞迴,,其中相同的神經元可以在遞迴呼叫中重復使用,因為它們在更高級別呼叫中的活動向量可以重建稍後使用快速權重中的資訊。
多時間尺度適應的功能在元學習(meta-learning)中正在逐漸被采納。

更高層次的認知
在考慮新的任務時,例如在具有不一樣的交通規則的城市中駕駛,甚至想象在月球上駕駛車輛時,我們可以利用我們已經掌握的知識和通用技能,並以新的方式動態地重新組合它們。
但是當我們采用已知的知識來適應一個新的設定時,如何避免已知知識對於新任務帶來的噪音幹擾?開始步驟可以采用Transformer架構和復發獨立機制。
對於系統1的處理能力允許我們在計劃或者推測時猜測潛在的好處或者危險。但是在更高級的系統級別上,可能就需要AlphaGo的蒙特卡羅樹搜尋的價值函式了。
機械學習依賴於歸納偏差或者先驗經驗,以鼓勵在關於世界假設的相容方向上學習。系統2處理處理的性質和他們認知的神經科學理論,提出了幾個這樣的歸納偏差和架構,可以來設計更加新穎的深度學習系統。那麽如何訓練神經網路,能夠讓它們發現這個世界潛在的一些因果內容呢?
在20世紀提出的幾個代表性的AI研究計畫為我們指出了哪些研究方向?顯然,這些AI計畫都想要實作系統2的能力,比如推理能力、將知識能夠迅速分解為簡單的電腦運算步驟,並且能夠控制抽象變量或者範例。這也是未來AI技術前進的重要方向。
聽完三位的探討,大家是不是覺得在AI之路上,光明無限呢?











