在這篇論文中,Yang Liu 等幾位研究者全面回顧了用於三個基本 CV 任務(分類、檢測和分割)的 100 多個視覺 Transfomer。
這段時間,電腦視覺圈有點熱鬧。先是何愷明等人用簡單的掩蔽自編碼器(MAE)證明了 Transformer 擴充套件到 CV 大模型的光明前景;緊接著,字節跳動又推出了部份指標超過 MAE 的新方法——iBOT,將十幾項視覺任務的 SOTA 又往前推了一步。這些進展給該領域的研究者帶來了很大的鼓舞。
在這樣一個節點,我們有必要梳理一下 CV 領域 Transformer 模型的現有進展,挖掘其中有價值的經驗。因此,我們找到了中國科學院計算技術研究所等機構剛剛釋出的一篇綜述論文。在這篇論文中,Yang Liu 等幾位研究者全面回顧了用於三個基本 CV 任務(分類、檢測和分割)的 100 多個視覺 Transfomer,並討論了有關視覺 Transformer 的一些關鍵問題以及有潛力的研究方向,是一份研究視覺 Transformer 的詳盡資料。

論文連結:https:// arxiv.org/pdf/2111.0609 1.pdf
本文是對該綜述的簡要介紹。
論文概覽
Transformer 是一種基於註意力的架構,在序列建模和機器轉譯等任務上表現出了驚人的潛力。如下圖 1 所示,Transformer 已經逐漸成為 NLP 領域主要的深度學習模型。最近流行的 Transformer 模型是一些自監督預訓練模型,它們利用充足的數據進行預訓練,然後在特定的下遊任務中進行微調 [2]–[9]。生成預訓練 Transformer(GPT)家族 [2]– [4] 利用 Transformer 解碼器來執行自回歸語言建模任務;而使用雙向編碼器的 Transformer(BERT)[5]及其變體 [6], [7] 是在 Transformer 編碼器上構建的自編碼器語言模型。

在電腦視覺領域,摺積神經網路(CNN)一直占據主導地位。受 NLP 領域自註意力機制成功的啟示,一些基於 CNN 的模型開始嘗試透過空間 [14]–[16] 或通道 [17]–[19]層面的額外自註意力層來捕獲長程依賴,而另一些模型則試圖用全域 [20] 或局部自註意塊[21]–[25] 來徹底替代傳統的摺積。雖然 Cordonnier 等人在理論上證明了自註意力塊的有效性[26],但在主流基準上,這些純註意力模型仍然比不上當前的 SOTA CNN 模型。
如上所述,在 vanilla Transformer 於 NLP 領域取得巨大成功之際,基於註意力的模型在視覺辨識領域也得到了很多關註。最近,有大量研究將 Transformer 移植到 CV 任務中並取得了非常有競爭力的結果。例如,Dosovitskiy et al. [27]提出了一種使用影像 patch 作為影像分類輸入的純 Transformer,在許多影像分類基準上都實作了 SOTA。此外,視覺 Transformer 在其他 CV 任務中也實作了良好的效能,如檢測 [28]、分割[29]、跟蹤[30]、影像生成[31]、增強[32] 等。
如圖 1 所示,繼 [27]、[28] 之後,研究者們又針對各個領域提出了數百種基於 Transformer 的視覺模型。因此,我們迫切地需要一篇系統性的文章來梳理一下這些模型,這便是這篇綜述誕生的背景。考慮到讀者可能來自很多不同的領域,綜述作者將分類、檢測和分割三種基本的視覺任務都納入了梳理範圍。
如下圖 2 所示,這篇綜述將用於三個基本 CV 任務(分類、檢測和分割)的 100 多種視覺 Transformer 方法按照任務、動機和結構特性分成了多個小組。當然,這些小組可能存在重疊。例如,其中一些進展可能不僅有助於增強影像分類骨幹的表現,還能在檢測、分割任務中取得不錯的結果。

圖 2 :視覺 Transformer 的分類
由於訓練設定和定向任務各不相同,研究者也在不同配置上對這些 Transforme 進行了評估,以進行方便和直觀的比較。此外,他們還揭示了一系列重要但仍需探索的特點,這些特點可能使 Transformer 從眾多架構中脫穎而出,例如彌合視覺和序列 Transformer 之間差距的松弛高級語意嵌入。最後,他們提出了幾個有前景的研究方向。
用於分類的視覺 Transformer
受 NLP 中 Transfomer 成功的啟發 [2]–[5], [8],不少研究者嘗試將 Transformer 引入影像分類任務。Vision Transformer(ViT)[27] 最先在主流分類基準上達到了可以媲美傳統 CNN 的效能。在論文的第 III 章,研究者對 2021 年 6 月之前釋出的 40 多個 Transformer 骨幹進行了全面回顧,並根據動機和實作情況將其分成了六類,如下圖 5 所示。
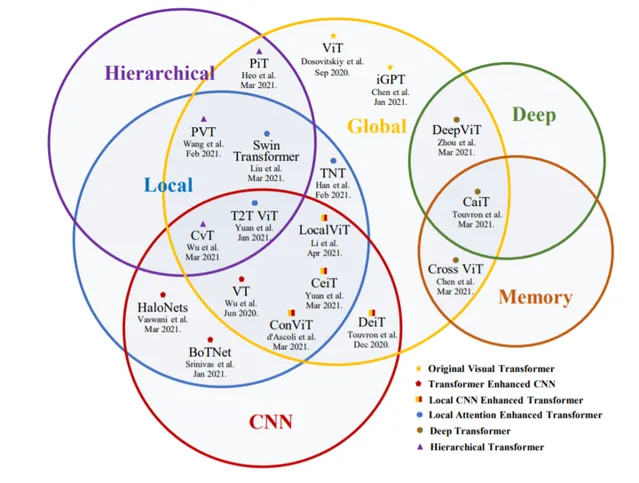
根據這一分類,研究者首先介紹了 ViT——用於影像分類的 Original Visual Transformer。接下來,他們討論了 Transformer Enhanced CNN 方法,這些方法利用 Transformer 增強 CNN 骨幹的長程依賴。Transformer 在全域建模方面能力突出,但在早期階段會忽略局部資訊。因此,CNN Enhanced Transformer 方法利用適當的摺積歸納偏置來增強 Transformer,而 Local Attention Enhanced Transformer 方法重新設計 patch 分區和註意力塊,以增強 Transformer 的局部性並維持一個無摺積的架構。
此外,CNN 在效能和計算效率方面都受益於分層和深度結構[93]。受此啟發,研究者們提出了 Hierarchical Transformer 和 Deep Transformer 方法。前者用一個金字塔 stem 代替分辨率固定的柱狀結構,後者可以防止註意力圖過於平滑,並在較深的層中增加其多樣性。此外,他們還回顧了目前可用的自監督方法。
下表 I 總結了以上 Transformer 模型在主流分類基準上的表現:

在梳理了這一部份的進展之後,研究者得出了以下結論:
對於分類任務,一個深度分層 Transformer 骨幹可以有效降低計算復雜度 [39],還能避免深層中的特征過於平滑[35], [40], [59], [60]。同時,早期摺積 [37] 足以捕獲低階特征,從而顯著增強淺層的穩健性,降低計算復雜度。此外,摺積投影[46], [47] 和局部註意力機制 [33], [42] 都可以提高 Transformer 的局部性。
用於檢測的視覺 Transformer
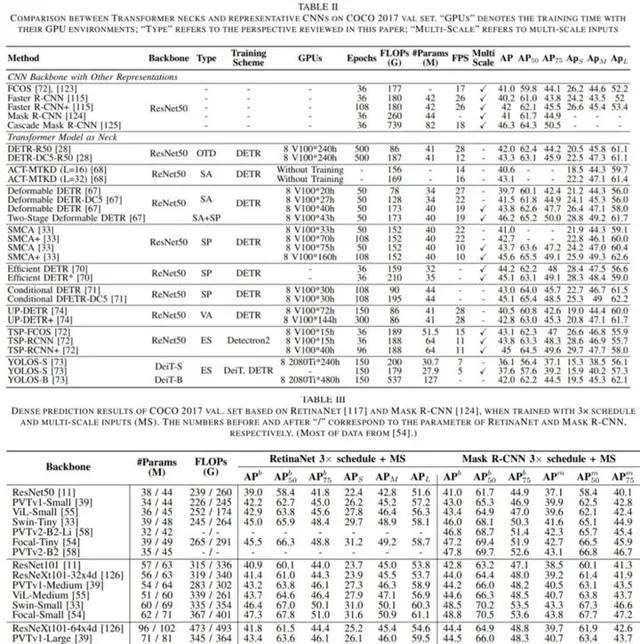
在第 IV 章中,研究者詳細介紹了用於目標檢測的視覺 Transformer。這些模型可以分為兩類:作為頸部的 Transformer 和作為骨幹的 Transformer。頸部檢測器主要基於為 Transformer 結構指定的一個新表示,稱為物件查詢,即一組學習到的同等地聚合全域特征的參數。它們試圖從加速收斂或提高效能的角度來解決最優融合範式。除了專門為檢測任務設計的各種頸部外,一定比例的主幹檢測器也會考慮到特定的策略。最後,作者在表 II 和表 III 中比較了它們的效能,並分析了 Transformer 檢測器的一些潛在改進。
在梳理了這一部份的進展之後,研究者得出了以下結論:
對於檢測任務,Transformer 頸部得益於編碼器 - 解碼器結構,比只使用編碼器的 Transformer 檢測器計算更少。因此,解碼器是必要的,但是由於收斂緩慢 [72],它需要的 stack 極少[70]。此外,稀疏註意力[67] 有利於降低計算復雜度,加速 Transformer 的收斂,而空間先驗 [67], [69], [71] 有利於提高 Transformer 的效能,稍微提高其收斂速度。
用於分割的視覺 Transformer
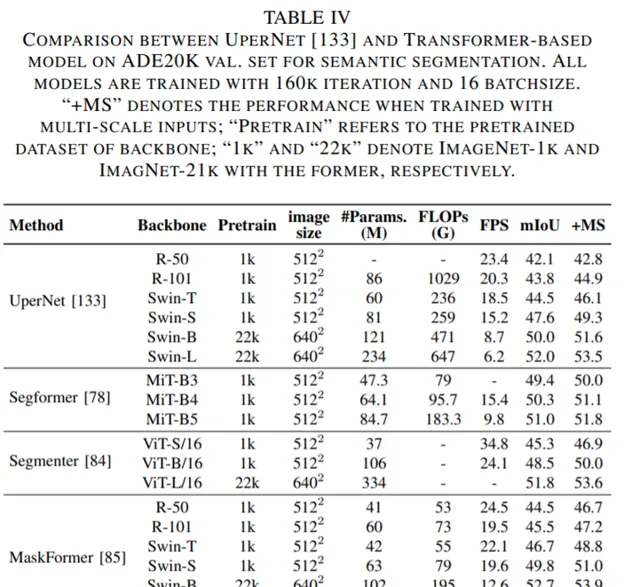
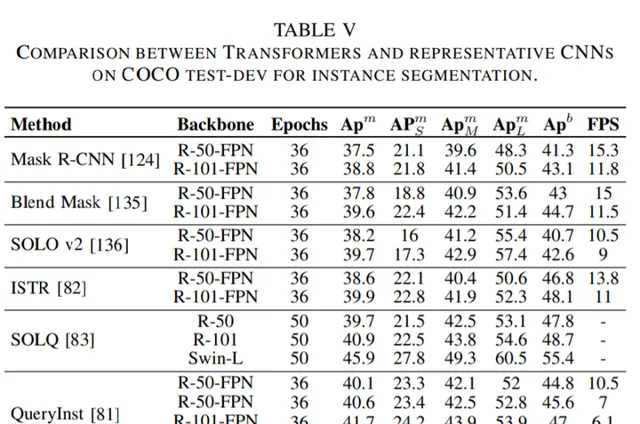
論文第 V 章主要介紹了用於分割的 Transformer。按照分割方式的不同,這些 Transformer 可以被分為兩類:基於 patch 的 Transformer 和基於查詢的 Transformer。後者可以進一步分解為帶物件查詢的 Transformer 和帶掩碼嵌入的 Transformer。下面這些表格展示了這些 Transformer 的效能數據。

在梳理了這一部份的進展之後,研究者得出了以下結論:
對於分割任務,編碼器 - 解碼器 Transformer 模型可以透過一系列可學習的掩碼嵌入將三個分割子任務統一為一個掩碼預測問題[29], [84], [137]。這種無框(box-free)方法在多個基準上實作了最新的 SOTA[137]。此外,基於 box 的 Transformer 的特定混合任務瀑布模式被證明在例項分割任務中達到了更高的效能。
關於視覺 Transformer 的幾個關鍵問題
Transformer 是如何打通語言和視覺的?
Transformer 最初是為機器轉譯任務而設計的。在語言模型中,句子中的每一個詞都被看作表示高級、高維語意資訊的一個基本單元。這些詞可以被嵌入到低維向量空間表示中,叫做詞嵌入。在視覺任務中,影像的每個像素都是低階、低維語意資訊,與嵌入特征不匹配。因此,將 Transformer 用到視覺任務中的關鍵是建立影像到向量的轉換,並保持影像的特點。例如,ViT[27]借助強松弛條件將影像轉換為包含多個低水平資訊的 patch 嵌入,Early Conv. [50] 和 CoAtNet [37] 利用摺積提取高級資訊,同時降低 patch 的冗余特征。
Transformer、自註意力和 CNN 之間的關系
從摺積的角度來看,其歸納偏置主要表現為局部性、平移不變性、權重共享和稀疏連線。這類簡單的摺積核可以有效地執行樣版匹配,但由於歸納偏置強,其上界要低於 Transformer。
從自註意力機制的角度來看,理論上,當給定足夠數量的頭時,它可以表示任何摺積層。這種 fully-attentional 操作可以交替地結合局部和全域層面的註意力,並根據特征之間的關系動態地生成註意力權重。盡管如此,它的實用性還是不如 SOTA CNN,因為其精度較低,計算復雜度較高。
從 Transformer 的角度來看,Dong 等人證明,當在沒有短連線或 FFN 的深層上訓練時,自註意力層表現出強大的「token uniformity」歸納偏置。結果表明,Transformer 由兩個關鍵部份組成:一個聚合 token 之間關系的自註意力層;一個提取輸入特征的 position-wise FFN。雖然 Transformer 具有強大的全域建模能力,摺積可以有效地處理低階特征[37],[50],增強 Transformer 的局部性[45],[70],並透過填充(padding)來附加位置特征[48],[49],[102]。
不同視覺任務中的可學習嵌入
Transformer 模型利用可學習嵌入來執行不同的視覺任務。從監督任務的視角來看,這些嵌入可以被分為類 token、物件、查詢和掩碼嵌入。從結構的角度來看,它們之間存在著內在的聯系。最近的 Transformer 方法主要采用兩種不同的模式:僅編碼器和編碼器 - 解碼器結構。每個結構由三個層次的嵌入套用組成,如下圖 16 所示。

從位置層面來看,在僅編碼器 Transformer 中學習的嵌入的套用被分解為初始 token 和後期 token,而學習的位置編碼和學習的解碼器輸入嵌入被用於編碼器 - 解碼器結構。從數量層面來看,僅編碼器的設計套用了不同數量的 token。例如,ViT [27],[38]系列和 YOLOS [73]在初始層中添加了不同的數位 token,而 CaiT [40]和 Segmenter [84]則利用這些 token 來表示不同任務中最後幾層的特征。在編碼器 - 解碼器結構中,所學習的解碼器的位置編碼 (物件查詢[28],[70] 或掩碼嵌入 [137]) 被顯式地 [28],[137] 或隱式地 [69],[70] 附加到解碼器輸入中。與恒定輸入不同,可變形 DETR [67]采用學到的嵌入作為輸入,並關註編碼器輸出。
受多頭註意力設計的啟發,多初始 token 策略被認為可以進一步提高分類效能。然而,DeiT [38]表明,這些額外的 token 將會向相同的結果收斂,這對 ViT 沒有好處。從另一個角度來看,YOLOS [73]提供了一個使用多個初始 token 來統一分類和檢測的範例,但這種僅編碼器的設計會導致計算復雜性很高。根據 CaiT [40]的觀察,後面的類 token 可以稍稍降低 Transformer 的 FLOPs,並略微提升效能(從 79.9% 到 80.5%)。Segmenter[84]也顯示了這種策略在分割任務中的效率。
與僅使用編碼器的 Transformer 的多個後期 token 相比,編碼器 - 解碼器結構節省了更多的計算。它透過使用一小組物件查詢(掩碼嵌入)來標準化檢測 [28] 和分割 [137] 領域中的 Transformer 方法。透過組合多個後期 token 和物件查詢(掩碼嵌入)的形式,像可變形 DETR [67]這樣的結構(以物件查詢和可學習解碼器嵌入為輸入),可以將基於不同任務的可學習嵌入統一到 Transformer 編碼器 - 解碼器中。
未來的研究方向
視覺 Transformer 方法取得了巨大的進展,並顯示出了有希望的結果,在多個基準上接近或超過了 SOTA CNN 方法的記錄。但該技術尚不成熟,無法撼動摺積在 CV 領域的主導地位。基於論文中的一些分析,作者指出了視覺 Transformer 的一些具有潛力的發展方向:
集合預測
正如論文中所提到的,由於損失函式的梯度相同,附加的類 token 將始終收斂 [38]。具有二分損失函式的集合預測策略已經在許多密集預測任務中廣泛套用於視覺 Transformer[28],[137]。如上所述,考慮分類任務的集合預測設計是很自然的,例如多類 token Transformer 借助集合預測來預測混合 patch 影像,這類似於 LVViT [41] 的數據增強策略。此外,集合預測策略中的一對一標簽分配導致早期過程中的訓練不穩定,這可能會降低最終結果的準確性。利用其他標簽分配和損失改進集合預測可能對新的檢測框架有所幫助。
自監督學習
自監督 Transformer 預訓練已經成為了 NLP 領域的標準,並在各種套用中取得了巨大成功[2],[5]。摺積孿生網路作為 CV 中的自監督範例,采用對比學習進行自監督預訓練,不同於 NLP 中的掩蔽自編碼器。最近,一些研究試圖設計一個自監督的視覺 Transformer 來彌補視覺和語言之間預處理方法的差距。它們大多繼承了 NLP 中的掩蔽自編碼器或 CV 中的對比學習方案。但是,目前還沒有用於視覺 Transformer 的監督方法能實作 NLP 中 GPT-3 那樣的革命性。如論文所述,編碼器 - 解碼器結構可能透過學習解碼器嵌入和位置編碼來統一視覺任務。自監督學習的編碼器 - 解碼器 Transformer 值得進一步研究。











