先直接回答這個問題,下面再分析AlphaGo和人工智慧的未來。我認為AlphaGo這次的比賽打敗李世乭比較懸,但是1-2年之內必然完勝人類。
-
按照兩者的Elo(圍棋等級分),可以算出去年年底的AlphaGo打敗李世乭的機率相當低。
如何算出的呢?AlphaGo去年年底的頂級分布式版本的Elo是3168(見下面第一張圖),而李世乭的Elo大約是3532(全球圍棋手Elo: Go Ratings ,見下面第二張圖)。
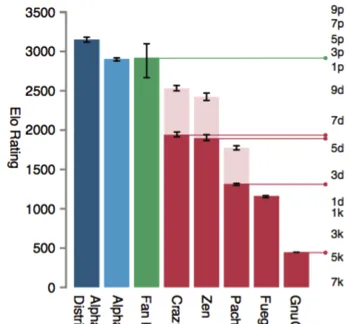
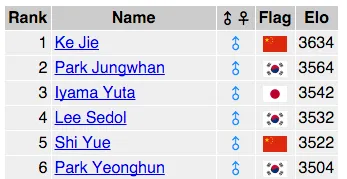
按照這兩個等級分的兩個棋手對弈,李世乭每盤的勝算為89%(\frac{1}{(1+10^{((3168-3532)/400))} )} ,公式見:How to Guide: Converting Elo Differences To Winning Probabilities : chess)。如果對弈一盤,AlphaGo尚有11%的獲勝的可能性,而整個比賽五盤勝出三盤或更多,AlphaGo就只有1.1%的可能性了。(當然,這是幾個月前的AlphaGo,也許今天已經超越了:見下面第三點)。
-
AlphaGo不是打敗了歐洲冠軍嗎?有些
人認為AlphaGo去年底擊敗了歐洲冠軍樊麾,所以挑戰(前)世界冠軍應有希望。但是,樊麾只是職業二段(Elo 3000左右),而李世乭是職業九段(ELO 3532)。這兩位的差別是巨大的,完全不能混為一談。就比如說一個人桌球打敗了非洲冠軍,並不代表他就可以成功挑戰中國冠軍。
- AlphaGo有可能在這幾個月突飛猛進,進而擊敗李世乭嗎? AlphaGo的負責人說:」外界不知道我們這幾個月進步了非常多「。(來自:Odds favor machine over human in big Go showdown )。這點確實有可能。AlphaGo進步的方法有兩個:(1)增加硬體:我們從Nature的文章可以看到:從1202個CPU到1920個CPU,AlphaGo的ELO只增加了28,而且線性地增加CPU,不會看到線性的ELO成長。若要達到364 ELO積分的提升,需要的CPU將達到天文數位(有篇文章估計至少要10萬個CPU:AlphaGo and AI Progress)。當然,谷歌有錢有機器,但是純粹加機器將會碰到平行計算互相協調的瓶頸(就是說假設有十萬萬台機器,它們的總計算能力很強,但是彼此的協調將成為瓶頸)。在幾個月之內增加兩個數量級的CPU並調節演算法,降低瓶頸,應該不容易。(2)增加學習功能:AlphaGo有兩種學習功能,第一種是根據高手棋譜的學習,第二種是自我對弈,自我學習。前者已經使用了16萬次高手比賽,而後者也在巨大機組上訓練了8天。這方面肯定會有進步,但是要超越世界冠軍可能不容易。最後,換一種分析方式:如果從過去深藍擊敗世界冠軍的「成長過程」來看,深藍大約1993年達到職業大師水平,4年後才在一場六盤的比賽中擊敗世界冠軍(大約500Elo積分點的提升)。今天的AlphaGo應該和1993年的深藍相似,剛進入職業大師水平。若要擊敗世界冠軍,雖然未必需要4年的時間,但是幾個月似乎不夠。
- 還有什麽以上未考慮的因素,導致AlphaGo獲勝嗎? 如果谷歌刻意未出全力和樊麾對抗,或者有其它學習或平行計算方面超越了Nature裏面的描述,那AlphaGo完全有可能獲勝。
既然寫了這麽多,就對這個題目再發表一些看法:
- AlphaGo 是什麽? 在今年一月的Nature (http://www. nature.com/nature/journ al/v529/n7587/full/nature16961.html )有AlphaGo的詳細介紹,AlphaGo是一套為了圍棋最佳化的設計周密的深度學習引擎,使用了神經網路加上MCTS (Monte Carlo tree search),並且用上了巨大的谷歌雲端運算資源,結合CPU+GPU,加上從高手棋譜和自我學習的功能。這套系統比以前的圍棋系統提高了接近1000分的Elo,從業余5段提升到可以擊敗職業2段的水平,超越了前人對圍棋領域的預測,更達到了人工智慧領域的重大裏程碑。
-
AlphaGo 是科學的創新突破嗎?
AlphaGo是一套設計精密的卓越工程,也達到了歷史性的業界裏程碑,不過Nature文章中並沒有新的「發明」,AlphaGo的特點在於:不同機器學習技術的整合(例如:reinforcement learning, deep neural network, policy+value network, MCTS的整合可謂創新)、棋譜學習和自我學習的整合、相對非常可擴張的architecture(讓其充分利用谷歌的計算資源)、CPU+GPU並列發揮優勢的整合。這套「工程」不但有世界頂級的機器學習技術,也有非常高效的程式碼,並且充分發揮了谷歌世界最宏偉的計算資源(不僅僅是比賽使用,訓練AlphaGo時也同樣關鍵)。
AlphaGo的跳躍式成長來自幾個因素:1)15-20名世界頂級的電腦科學家和機器學習專家(這是圍棋領域從未有的豪華團隊:也許你覺得這不算什麽,但是要考慮到這類專家的稀缺性),2)前面一點提到的技術、創新、整合和最佳化。3)全世界最浩大的谷歌後台計算平台,供給團隊使用,4)整合CPU+GPU的計算能力。 - AlphaGo是個通用的大腦,可以用在任何領域嗎? AlphaGo裏面的深度學習、神經網路、MCTS,和AlphaGo的擴張能力計算能力都是通用的技術。AlphaGo的成功也驗證了這些技術的可延伸性。但是,AlphaGo其實做了相當多的圍棋領域的最佳化;除了上述的系統調整整合之外,裏面甚至還有人工設定和調節的一些參數。AlphaGo的團隊在Nature上也說:AlphaGo不是完全自我對弈end-to-end的學習(如之前同一個團隊做Atari AI,用end-to-end,沒有任何人工幹預學習打電動遊戲)。如果AlphaGo今天要進入一個新的套用領域,用AlphaGo的底層技術和AlphaGo的團隊,應該可以更快更有效地開發出解決方案。這也就是AlphaGo真正優於深藍的地方。但是上述的開發也要相當的時間,並且要世界上非常稀缺的深度計算科學家(現在年待遇行情已達250萬美金)。所以,AlphaGo還不能算是一個通用技術平台,不是一個工程師可以經過調動API可以使用的,而且還距離比較遠。
-
如果這次AlphaGo沒有打敗
李世乭,那還要多久呢?
IBM深藍從進入大師級別到比賽擊敗世界冠軍花了四年。AlphaGo應該會比深藍更快提升自己,因為深藍需要新版本的硬體,和針對Kasparov的人工調節最佳化,而AlphaGo是基於谷歌的硬體計算平台,和相對通用的深度學習演算法。所以,幾個月太短,4年太長,就預計1-2年之間吧。
- 從西洋棋到圍棋,到底是不是巨大的突破呢? 肯定是的,在這篇文章裏面(在西洋棋領域,電腦已經可以戰勝人腦,那麽圍棋領域電腦還差多遠? - 電腦 ),第一位回答者分析了圍棋的復雜度為10^{172} 而西洋棋則只有10^{46} 。在1997年深藍擊敗世界冠軍時,大家都認為:深藍使用的是人工調整的評估函式,而且是用特殊設計的硬體和」暴力「的搜尋 (brute-force) 地征服了西洋棋級別的復雜度,但是圍棋是不能靠窮舉的,因為它的搜尋太廣(每步的選擇有幾百而非幾十)也太深(一盤棋有幾百步而非幾十步)。而AlphaGo的發展讓我們看到了,過去二十年的發展,機器學習+平行計算+海量數據是可以克服這些數位上的挑戰的,至少足以超越最頂尖的人類。
- AlphaGo 若打敗了世界冠軍,就意味著電腦超越人腦?或者可以思考了嗎?我的回答:
P.S. - 也許有人好奇,為什麽這個話題我說了這麽多,因為在1986年,我在讀書時,曾經開發了一套黑白棋系統(復雜度10^{28} ),擊敗了黑白棋的世界團體冠軍,而當年的那套系統也有(非常粗淺的)自我學習的能力。有興趣的網友可以在這裏看到我當年的文章:
A pattern classification approach to evaluation function learning) 。











