編輯:編輯部 HYZ
【新智元導讀】 國產第一個AI模型登頂Hugging Face月榜冠軍!釋出短短一年, BGE 模型總下載量破數億,位居國產TOP 1。如今,它在開源社群廣受歡迎,被譽為RAG生態中的「瑞士軍刀」。
近日,Hugging Face更新了月度榜單,智源研究院的BGE模型登頂榜首,這是中國國產AI模型首次成為Hugging Face月榜冠軍。
BGE在短短一年時間內,總下載量已達數億次,是目前下載量最多的國產AI系列模型。

BGE,全稱BAAI General Embedding,是北京智源人工智慧研究院研發的開源通用向量模型,該系列模型專為各類資訊檢索及大語言模型檢索增強套用而打造。
自2023年8月釋出首款模型BGE v1,歷經數次叠代,BGE已發展為全面支持「多場景」、「多語言」、「多功能」、「多模態」的技術生態體系。
BGE不僅效能綜合卓越,多次大幅重新整理BEIR、MTEB、C-MTEB等領域內主流評測榜單,而且始終秉持徹底的開源開放的精神,「模型、程式碼、數據」向社群完全公開。
BGE在開源社群廣受歡迎,許多RAG開發者將其比作資訊檢索的「瑞士軍刀」。

除了個人使用者,BGE亦被國內外各主流雲服務和AI廠商普遍整合,形成了很高的社會商業價值。

左右滑動檢視
通用向量模型:為RAG提供一站式資訊檢索服務
時代背景
檢索增強(RAG: retrieval-augmented generation)是自然語言處理與人工智慧領域的一項重要技術:透過借助搜尋引擎等資訊檢索工具,語言模型得以與外部資料庫連通,從而實作推理能力與世界知識的整合。
早在2019年至2020年,谷歌與Meta的研究人員就在多項獨立的研究工作中提出了該項技術。此後數年間,RAG被逐漸套用於問答、對話、語言模型預訓練等許多場景。
然而,RAG技術真正得到廣泛認知則是源於2022年11月ChatGPT的釋出:大語言模型為社會大眾帶來了前所未有的智慧互動體驗。由此,行業開始思考如何套用該項技術以更好的促進生產力的發展。
在眾多思路中,RAG技術是大語言模型最為成功套用範式之一。
借助RAG這一工作模式,大語言模型可以幫助人們以非常自然的方式與數據進行互動,從而極大提升獲取知識的效率。
與此同時,RAG還可以幫助大語言模型拓展知識邊界、獲取即時資訊、處理過載上下文、獲取事實依據,從而最佳化事實性、時效性、成本效益、可解釋性等關鍵問題。

向量檢索
經典的RAG系統由檢索與生成兩個環節所構成。大語言模型已經為生成環節提供了有力的支撐,然而檢索環節在技術層面尚有諸多不確定性。
相較與其他技術方案,向量檢索(vector search)因其使用的便捷性而廣受開發者歡迎:借助向量模型(embedding model)與 向量資料庫 ,使用者可以構建在地化的搜尋服務,從而便捷的支撐包括RAG在內的諸多下遊套用。
在RAG興起的2023年初,向量模型作為技術社群首選的資訊檢索工具被廣泛使用,一時間風光無兩。然而空前的熱度背後,向量模型的發展卻較為滯後。
傳統的向量模型多是針對特定的使用場景、以點對點的方式開發得到的。在面對RAG復雜多樣的任務訴求時,這些專屬的向量模型由於缺乏足夠的泛化能力,檢索品質往往差強人意。
此外,與許多其他領域的問題類似,傳統向量模型的研發多圍繞英文場景,包括中文在內的非英文社群更加缺乏合適的向量模型以及必要的訓練資源。
通用模型
針對上述問題,智源提出「通用向量模型」這一技術構想。目標是實作適應於不同下遊任務、不同工作語言、不同數據模態的模型體系,從而為RAG提供一站式的資訊檢索服務。
實作上述構想在演算法、數據、規模層面存在諸多挑戰,因此,智源規劃了多步走的策略。
首先,著眼於「任務統一性」這一可實作性最強同時需求度最高的能力維度,即打造適用於中英文兩種最重要語種、全面支持不同下遊任務的向量模型。
該系列模型被命名為 BGE v1 ,於2023年8月份完成訓練並對外釋出。BGE v1經由數億規模的中英文關聯數據訓練得到,可以準確表征不同場景下數據之間的語意相關性。
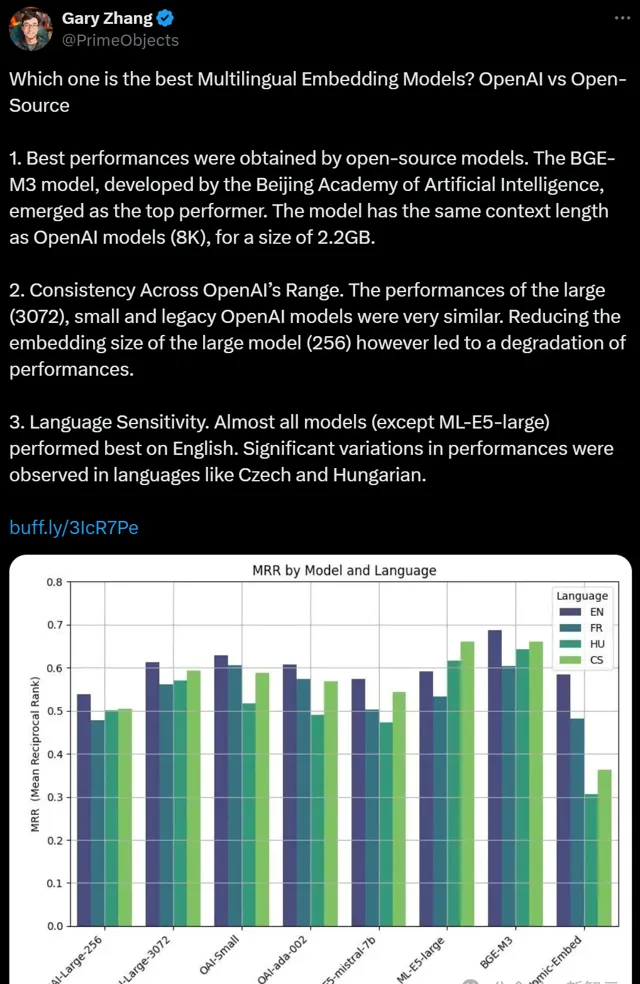
主流基準MTEB(英文)、C-MTEB(中文)的評測結果顯示,BGE v1的綜合能力與各主要子任務能力均達到當時SOTA,超過了包括OpenAI Text-Embedding-002在內的眾多高水平基線。
其中,BGE v1在中文領域的優勢尤為顯著。這在很大程度上填補了中文向量模型的空白,極大的幫助了中文社群的技術開發人員。
第二,在實作任務層面的統一之後,新一版模型的叠代著眼於實作「語言統一性」。
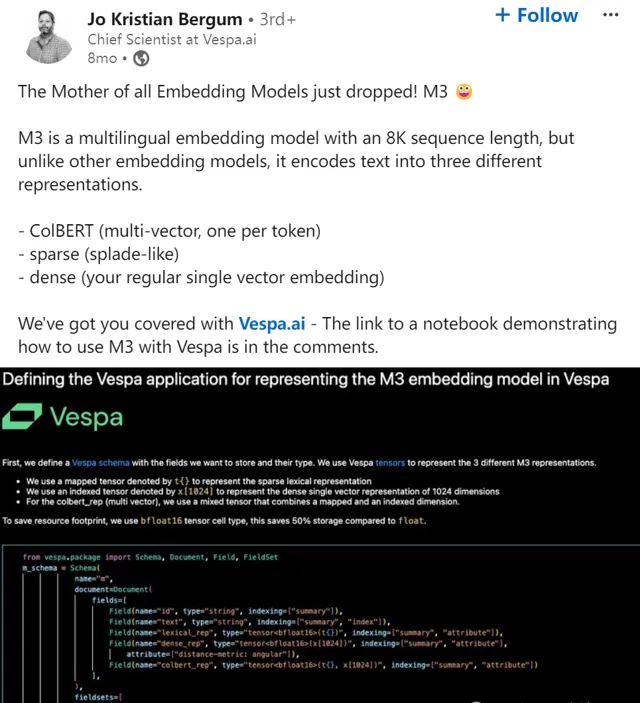
為此,智源推出了 BGE M3 模型,可支持100多種世界語言的統一表征,並實作各語言內部(多語言能力)及不同語種之間(跨語言能力)的精準語意匹配。
為了充分學習不同語言中的隱含資訊,BGE M3模型使用了超過10億條的多語言訓練數據,並利用了大量機器轉譯數據。這一訓練數據的規模、品質、多樣性都明顯超過了此前提出的多語言向量模型。
除了多語言能力,BGE M3模型還創造性的整合了向量檢索、稀疏檢索、多向量檢索,首次實作了單一模型對三種主要檢索能力的統一。
同時借助位置編碼及訓練效率的最佳化,BGE M3的最大輸入長度得以拓展至8192個詞元(token),有效的支持了句子、篇章、以至超長文件等諸多不同粒度的檢索物件。
BGE M3模型在2024年2月完成訓練並對外釋出。其檢索品質顯著超越了同一時期釋出的OpenAI Text-Embedding-003模型,在MIRACL、MKQA等主流評測基準的效果均達到業內最佳。
與此同時,其支持的語種範圍也遠超其他同類模型,對於很多語言,BGE M3的能力甚至超越了該語言此前的專屬向量模型。
BGE M3一經釋出便廣受好評,一度位居Hugging Face Trending前三位、Github Trending前五位。 Zilliz 、Vespa等業內主要的向量資料庫第一時間便對BGE M3進行了整合及商業化套用。
第三,基於初步的階段性成果,BGE模型進一步發展出多個衍生版本。
BGE-re-ranker、BGE-re-ranker-m3旨在實作精準排序功能,以支持多階段、細粒度的語意檢索任務。
BGE visualized在文本模型之上進一步拓展視覺數據處理能力,從而實作多模態混合檢索能力。
BGE-ICL則首次使得向量模型具備了上下文學習能力,使之可以依照使用者意圖靈活適配下遊任務。
相關模型不僅持續重新整理MTEB在內的多個主要基準的最高記錄,同時帶來了演算法層面的諸多創新,在海內技術社群引起廣泛討論。
社群套用
開源是智源研究院大模型研發的一貫立場。本著這一原則,BGE的模型權重、推理及訓練程式碼、訓練數據均面向社群開放。
與此同時,研發團隊致力於不斷推動創新研究,並積極透過技術講座、研討會、hands-on tutorial等形式與社群互動,幫助向量檢索、RAG等技術的不斷發展。
BGE系列模型遵循開放的MIT授權合約,社群使用者可以對其自由的使用、修改、並進一步分發。除了眾多個人使用者,BGE的另一大使用群體來自於社群中熱門的向量資料庫(如Milvus、Vespa、Pinecone)以及RAG開發框架(如 Langchain 、Llama Index、RAGFlow)。
國內外各大雲服務廠商也紛紛提供BGE的商業化服務API,這不僅進一步促進使用者使用,同時創造了較高的社會商業價值。
自2024年初至今,BGE系列模型的累計下載量已超過數億次,成為下載量最多的國產開源AI模型。
未來演進:從通用向量模型到通用搜尋智慧
在過去一年時間裏,包括智源在內的多家機構都在致力於開發「好用且易用」的檢索工具,以推動相關領域的學術研究與產業套用。
隨著BGE等模型的不斷發展,這一目標在2024年底已初步實作:對於大多數套用場景、工作語言、數據模態,開發者都可以比較容易的獲取相應的開源檢索工具。
與此同時,RAG產業的發展也方興未艾:各個大模型廠商都將RAG作為主要商業模式賦能千行百業,Perplexity、 New Bing 等基於檢索增強的AI搜尋引擎也為人們帶來了全新的搜尋體驗。
然而套用側繁榮的背後隱藏著技術層面的發展陷入相對停滯。相較於基礎大模型、多模態等領域,資訊檢索在近期內鮮有激動人心的技術進展。
幾朵烏雲
在套用於RAG任務時,有三個關於檢索工具的「小問題」常被提及。
-
領域適配問題:通用的向量模型在處理某些特定領域的問題時效果不佳,需要經過進一步微調方可達到可用的狀態。
-
切片問題:過長的上下文需要經過切片、並獨立編碼,方可在RAG過程中進行使用;但是,最佳的切片尺寸往往難以選擇。
-
控制機制問題:什麽時候需要做檢索,拿什麽內容去做檢索。
這幾個小問題常在工程層面進行被討論,但其背後暗含著傳統檢索工具(向量模型、排序模型)本質性的技術限制。
1. 靜態內容
以傳統的向量模型為例:輸入數據會被單向性、一次到位地對映為高維向量。
無論是使用者還是模型自身並不能自主依據不同任務、不同場景對模型功能進行自適應的調整。
雖然此前曾有也學者提出使用提示指令(instruction)對模型進行個人化調整,但後來的實驗證明,傳統模型僅是機械性的記住了訓練時見到過的指令,並不能像GPT那樣泛化出一般性的指令遵循能力,唯有不斷微調模型參數方可使之適應於新的任務場景。
因此,當前一眾的通用向量模型處處都可用、但效果並非最佳。從搜尋的全域視角看,他們更應該作為一種局部性的技術手段。
2. 機構化限制
當代的資訊檢索技術多發展自互聯網的場景,因此都隱含著對數據的結構化或者半結構化的建設。
比如:一個網頁、一條新聞或者一個維基段落就是一個獨立的資訊單元。數據天然就是可切分的,或者說數據存在平凡的切分最優解(trivial solution for optimal chunking)。
因此,傳統的資訊檢索手段能夠比較容易對數據進行編碼與索引。但是這一假設在RAG場景中完全不適用。
數據會是一個超長的詞元序列(如pdf檔、長視訊、程式碼倉庫、歷史互動記錄),而非按照某種結構定義好的知識。數據不存在所謂最優的切片策略:人們固然可以遵循某種歸納偏執對非結構化數據進行切片,但是對於某個問題有利的上下文切片策略,換做另一個問題就可能是一個非常糟糕的策略。
3. 僵化的工作機制
傳統的資訊檢索主要針對「一問一答」這一固定的工作模式。使用者需要較為清晰地表述「自己需要獲取資訊」以及「需要獲取什麽樣的資訊」。
也正是由於這樣的限制,當前的RAG套用依然局限於簡單的問答場景(quesiton-answering),在更加普遍的任務中尚不能獲得取得令人滿意的結果(如程式碼倉庫的上下文管理、長期記憶、長視訊理解)。
通用搜尋智慧
通用搜尋的終極目標是能夠在「任何場景、任何任務中,精準獲取所需的各種形態的資訊」。因此,理想的資訊檢索工具應具備主動發掘任務需求的能力,並能根據不同的套用場景進行自適應調整。同時,還要能夠高效處理自然狀態下的數據——無論是非結構化還是多模態的數據。
如何構建通用搜尋智慧仍然是一個未解的難題,而有效地改造和利用大模型將是實作這一目標的關鍵。
大模型的套用將為資訊檢索帶來顯著優勢。與傳統靜態檢索模型不同,大模型具有動態性:它們能夠根據具體任務的輸入進行調整,甚至透過自我提示和反思等機制進一步最佳化,進而更好地適應任務需求。此外,大模型能夠自然處理非結構化和多模態數據,並具備主動發起資訊需求的能力。
值得註意的是,2024年初曾爆發過關於RAG(檢索增強生成)與長上下文大模型的討論,表面上這兩者似乎存在沖突,但實際上並無矛盾:語言模型直接處理海量資訊的效率較低,必須借助有效的資訊檢索工具;而傳統的資訊檢索工具智慧化不足,需要更智慧的中樞來加以驅動。
因此,未來通用搜尋智慧的實作,依賴於大模型與檢索工具的深度融合。











