編輯:桃子 喬楊
【新智元導讀 】o1誕生,對於OpenAI團隊來說,是最具革命性的時刻。在22分鐘完整版采訪視訊中,他們分享了自己對新模型的思考,以及背後的開發故事。
OpenAI o1團隊采訪的完整版視訊,終於上線了!
全程22分鐘,o1研發團隊在計畫Bob McGrew組織下,一起分享了「啊哈」時刻。

有的人提到,全新o1模型相當於多個博士「合體」而成,往往比人類表現更好。還有的人稱,o1釋出之後,明顯感受到了AGI到來。
「當模型在數學、編碼、圍棋、西洋棋等領域的表現超過人類時,AGI的未來變得更加明朗」。
來自艾倫研究所的科學家Nathan Lambert對這個視訊,做了一個精彩亮點的總結。
一共有8點:
1 強化學習加持的o1,比人類更善於發現新的CoT推理步驟
2 自我批評的湧現,是o1最強有力的時刻
3 讓o1「超時」前完成回答,然後突然有了「啊哈」時刻
4 scaling參數規模的挑戰,以及繼續沿著強化學習演算法進步之路
5 許多人提到,相對於演算法而言,基礎設施顯得多麽重要
6 透過規劃、糾錯,o1能夠解決世界上的新問題
7 新的訓練範式是一種全新的方法,可以將更多的算力投入到模型中
8 o1編寫程式碼時,當其輸出要使用的程式碼時,需要透過單元測試
接下來,具體來看下o1模型背後的故事。
強化學習+思考,o1開啟新範式
o1作為OpenAI全新系列,與GPT模型最大不同,就在於推理。
它本質上,是一個推理模型,也就是會比以往「思考」得更多。
在OpenAI研究人員看來,「思考」就是推理的一種最直觀的方式。
有時候,當被問及義大利首都是什麽問題時,我們幾乎不用思考,即刻就能得出答案。但有時候,涉及商業企劃書、寫小說等人物時,便需要長時間的思考過程。

毋庸置疑,思考時間越久,結果就越好。
因此,推理是將思考時間,轉化為最優結果的能力。
用Mark Chen的話來說,推理是一種「原語」,是實作任何可靠思考過程的必經之路。
關於推理的研究,OpenAI內部其實很早就開始了。成立初期,他們看到了AlphaGo透過RL演算法戰勝人類的潛力,並進行了大量的研究。
比如,他們曾在2016年開放遊戲測試平台「Universe」,是一個訓練AI通用智慧水平的開源平台。
2018年打造出名為OpenAI Five的遊戲AI,成功擊敗了兩屆DOTA2國際邀請賽的世界冠軍OG戰隊。

與此同時,數據和機器人領域,取得了重大的scaling進展。
OpenAI團隊便開始思考:如何在通用領域做到強化學習,實作一個非常有力的AI?
那便是,GPT系列開啟的全新範式。它在擴充套件無監督學習方面,取得了驚人的成果。

而且,也就是從那時起,研究人員便開始探索,如何將這兩種範式相結合——強化學習和無監督學習。
研究人員稱,這項努力開始的確切時間點,很難說,但這件事已經進行了很長時間。
「啊哈」時刻
在視訊中,有人表示,自己覺得研究中最酷的就是那個「啊哈」時刻了。
在某個特定的時間點,研究發生了意想不到的突破,一切忽然就變得很明了,仿佛頓悟一般靈光乍現。
所以,團隊成員們分別經歷了怎樣的「啊哈」時刻呢?
有人說,他感覺到在訓練模型的過程中,有一個關鍵的時刻,就是當他們投入了比以前更多的算力,首次生成了非常連貫的CoT。
就在這一刻,所有人都驚喜交加:很明顯,這個模型跟以前的有著明顯的區別。

還有人表示,當考慮到訓練一個具備推理能力的模型時,首先會想到的,是讓人類記錄其思維過程,據此進行訓練。
對他來說,啊哈時刻就是當他發現透過強化學習訓練模型生成、最佳化CoT,效果甚至比人類寫的CoT還好的那一刻。
這一時刻表明,我們可以透過這種方式擴充套件和探索模型的推理能力。

這一位研究者說,自己一直在努力提升模型解決數學問題的能力。
讓他很沮喪的是,每次生成結果後,模型似乎從不質疑自己做錯了什麽。
然而,當訓練其中一個早期的o1模型時,他們驚奇地發現,模型在數學測試中的得分忽然有了顯著提升。
而且,研究者們可以看到模型的研究過程了——它開始自我反思、質疑自己。
他驚嘆道:我們終於做出了不一樣的東西!
這種感受極其強烈,那一瞬間,仿佛所有東西都匯聚到了一起。

還有一位研究人員表示,當你要求模型在「超時」前,完成思考,過程非常有趣。
這就像自己在參加數學競賽一樣,任何思考都是有時限的。
他表示,這也是自己進入AI領域主要原因,而現在,對於自己來說,也算是實作了「閉環」時刻。

另外,o1模型讓人驚艷的是,在推動科學發現和工程進步,有巨大的幫助。

對於很多人而言,AGI似乎是一個很抽象、很遙不可及的概念,直到親眼看見AI在人類擅長的事情上做得更好,才能相信AGI的到來。
對專業的西洋棋和圍棋手而言,IBM的Deep Blue,以及DeepMind AlphaGo和AlphaZero,讓他們早在幾年前就意識到了這一點。
而對OpenAI的這群擅長數學和編碼的科學家,o1模型就有類似的意義。更有趣的是,他們的工作相當於是親手制造了一個可以碾壓自己能力的AI。
計畫中,遇到哪些困難?
關於過程中遇到的障礙,研究人員們直接表示,訓練LLM從根本上來講就是一件非常困難的事情。
類似於從地球發射一枚飛往月球的火箭,成功的路只有很窄的一條,但有數不清的失敗之路,稍微偏離一個角度就無法到達目標。
訓練過程出問題的方式可以有上千種,即使在這群才華橫溢的研究科學家們手中,每輪訓練也會遇到數百個問題。
此外,隨著模型變得越來越智慧,比如像o1一樣相當於手握幾個phd學位的人類,評估也變得越發困難。
有時,他們需要花很長的時間來確定模型做的事情是否正確,而且最後很多常用的行業基準也趨於飽和,需要重新找到適合o1能力的基準測試。
除了模型的開發歷程,研究人員們還被問到了自己最喜歡的o1模型用例。
Hyung Won Chung表示,o1可以成為很好的編碼助手。
他自己在工作時通常遵循TDD(Test-Driven Development)的開發方式,有了o1的幫助可以免去自己編寫單元測試的工作,而是直接指定需求,讓模型自動編寫。
此外,遇到的報錯資訊也可以直接扔給o1,雖然有時不能直接解決問題,但它可以比編譯器提出一個更好的問題,幫助你解決錯誤。

Jason Wei則表示,自己經常把o1當成頭腦風暴的夥伴,而且可以討論的問題範圍相當之廣,大到如何解決一個機器學習問題,小到如何起草一篇部落格或推文。

他今年5月撰寫的一篇關於LLM評估的部落格,就借鑒了o1的意見,比如文章的結構、各種評估基準的優缺點以及行文風格等等方面。

在OpenAI工作是一種什麽樣的體驗?
關於這個問題,很多人都談到了大家的聰明才智,以及團隊氛圍的融洽。
比如自己吭哧吭哧偵錯了一周的程式碼,被路過的同事瞬間解決了;每天和極其聰明的同事共處,讓自己逐漸變得謙卑。
Mark Chen形容「草莓」計畫是一個非常「有機」(organic)的計畫,因為在專業問題上大家都有自己的看法和主見,都有滿懷熱情想要推動的想法。
當這些想法聚集在一起,就會迸發出火花,像滾雪球一樣越滾越大。
然而,有主見的另一面,就是所有人都很堅持自己的看法,但並不固執。如果看到反駁自己主張的客觀結果,他們也會隨之改變想法。
更值得贊嘆的是,這群絕頂聰明的人,同時也很nice,樂於幫助別人解決問題,同事之間一起吃飯、一起出去玩,讓采訪中的很多研究者都直言,「在這裏工作是非常好的經歷」。
o1-mini背後的故事
o1-mini釋出的動機是,為更多研究人員提供預算較低,但推理能力依舊很強的模型。
它可以稱得上是「推理專家」,比以往OpenAI最佳模型還要聰明。
而且,成本和延遲都非常低。

或許,它可能不一定知道一位名人,以其出生日期,但確具備了如何進行有效推理,和大量智慧的能力。
OpenAI研究人員表示,將進一步改進演算法,使之能夠媲美最好的小模型。
除此之外,全世界的研究人員一直以來,都在投入更多的計算和硬體,使得模型成本在很長一段時間內,呈指數級下降。
然而,一個缺陷是,我們沒有去花費更多時間,尋找一種新的方法扭轉局面。
o1新範式,便是我們的發現——推理scaling,也能很好最佳化算力效率。
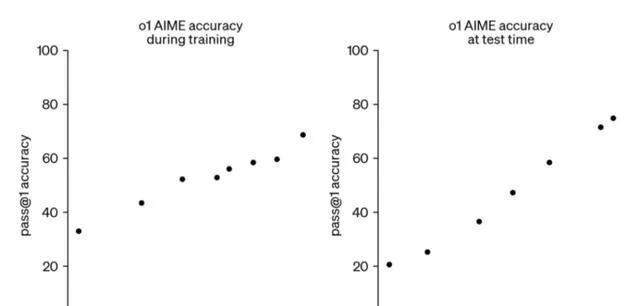
做研究的動力是什麽?
這批「智慧大腦」能夠聚在一起,究竟是什麽原因,激勵著他們去做研究?
一位研究人員稱,一想到自己透過不同方式,讓模型實作推理,這個過程簡直太迷人了。
還有人表示,「好事多磨」。
o1能夠回答如此神速,這是朝著能夠長時間思考問題的模型,邁出的第一步。未來,還將需要進行數月、甚至數年的研究,讓其邁向下一個征程。
「一想到我們少數人能夠產生改變世界的影響,就非常興奮,有意義」。

最抓人的一點是,新範式解鎖了模型以前無法完成的任務,這不僅僅是回答某些查詢,而實際上已經透過規劃、糾正錯誤,泛化出新的能力。
甚至,o1能夠產生新的知識,對於科學發現來說,這是最令人興奮的部份。
研究者表示,在短時間內,模型將成為自身發展,越來越強大的貢獻者。
最後,當o1負責人問道,「還有什麽其他觀察值得一提嗎」?
Jason Wei分享道,「一個有趣的觀察是,每個訓練出來的模型都略有不同,有自己的怪癖,就像一件手工藝品。這種獨特性為每個模型增添了一絲個性之處」。











