在工程上,任何一個步驟都需要仔細再仔細,數據校驗,流程測試需要貫穿在每個步驟上,任何的疏忽和不小心都會導致錯誤的出現。
引言
自新年尹始,筆者就忙於領導給筆者提出的一個新課題,新課題需要使用機器學習進行實踐,很多細節之前筆者都沒有趟過,導致中間 過程磕磕碰碰。還好有其他同事的建議與指導,已經先前一版比較成熟的實踐方案珠玉在前,筆者為此也少走了很多彎路。即便如此, 中間的一些坎坷與經驗,還是挺有記錄與分享意義的。
正好之前在行業交流群內看到有朋友在問機器學習如何實踐,而在類似知乎等平台上也有挺多愛好者的各種嘗試,但是似乎挺多細節並 沒有做到比較好的思考與體驗,筆者這裏按照自己的實踐步驟,給出一些經驗與建議。
基於場景的步驟劃分
筆者所做課題屬於演算法交易的一塊,領導給出了一個遠期需要達成的目標,剩下的就需要筆者去規劃研究路徑,實作途徑等內容。在演算法 交易這一塊經驗的缺失,著實困擾了比這兒一段時間,很多想當然的內容後來也統統被證偽了。現在回頭來看,其實做類似課題的時候, 千萬不能被學術的一些思維禁錮住, 基於場景 的規劃與實踐可能才是更有意義的。
明確目標
所謂 基於場景 , 其實最重要的是,一開始就需要把問題描述清楚,明確自己需要達成的目標是什麽?然後去思考目標的邏輯性與 可行性。舉例而言,筆者這前遇到過有位老師,他雖然說要做金融 AI,但是並不知道自己到底需要達成的什麽目標。因為他最開始的 想讓筆者實作多項式擬合股價,然後去預測股價!!!姑且不論這中間的 「過擬合」 「欠擬合」 等問題,這個課題從邏輯上就有悖論之 處,簡單想一下,股價的形成是市場的合力,這個合力包括了保險資管,公募資金,散戶,私募資金等多方合力,沒有任何理由可以認 為這些分開的個體能將股價維持成某個函式形式。邏輯上有問題的目標,我們何必去費那力氣。
這個問題引申開來,筆者認為,任何試圖對未來股價進行預測在場景描述上都是有問題的,因此,有些對股價預測的分享和嘗試,其實 在實踐上都應該會面臨這樣那樣的問題。之前看知乎上有量化愛好者用這樣那樣的方案去進行股價預測,本質上,筆者認為和多項式 擬合股價沒有什麽區別。
但是,如果換一個角度思考股價預測的問題,為什麽我們要去預測股價?其實是為了獲取價差之間的收益,這個收益有多有少,反應在 股價上,就是時序上兩個股價之差,這個差具體多大也許挺難預測,但是 T+1 時刻股價相比 T 時刻股價漲還是跌,漲多高的振幅,跌 多少的振幅,其實有個機率上的判斷就足夠了,於是,問題也就變得簡單了,不是去預測股價的回歸問題,而是去評估股價在指定時間 內漲,跌的機率,漲多少,跌多少的機率的分類問題。於是 基於場景 的問題就可以很明確了,即在指定時間內,股價的變動範圍 會落到哪個區間的分類問題。
目標確定下的步驟劃分
資料搜尋與儲備
其實這一塊筆者一直都是采用的偷懶的做法,首先中文搜尋引擎,類似知乎等內容聚合平台上去搜尋類似問題有沒有人有做過,他們的 經驗教訓是怎樣的;如果還是覺得不夠,英文搜尋引擎, QUORA 等國外內容聚合平台;然後是 google 學術等按照之前他們讀過的覺 的好的文章找到,sci-hub 去搞到文章內容。此外,筆者的個人經驗,其實很多券商的金工研報還是相當有借鑒意義的,不過直接套用 往往會碰到這樣那樣的問題,不過研報有些思考其實是可以沿襲的,譬如之前看到某研報說是做的高頻因子研究,但是最終卻還是日線 級別的收益分析,可能有些人會覺得這樣的研報在日內高頻研究上用不上,但是如何換個思路,將研報中對高頻因子的定義的思想搞 清楚了,完全可以形成自己的高頻因子。
路徑規劃
它山之石可以攻玉。相當多的問題在網路上都可以找到前輩的經驗,按照自己明確的需要達到的目標,對自己需要做的事情有個大體的 把握。在這一塊可以盡可能的發散,但是需要註意的是,每個發散與調研的環節,也需要明確截止時間,不然太發散了,很容易就偏離 主線了。來自筆者同事的建議確實很有道理,盡快聚焦主線,當一路環節都趟平了,其他之前自己覺得做的不好的環節,完全可以到時 後回來改善。
- 資料搜集與挑選 按照筆者的經驗,一般一到兩周的資料搜集與挑選,對挑選出值得精讀的文獻進行一周的仔細閱讀,然後用一到兩周對文獻中重要 的內容進行實作,基本上夠用,當然某些文獻內容比較艱深,復現起來難度也足夠大,這時候就需要讀者自行進行取舍了。
- 內容復現與大體判斷 在大體調研與實作後,需要對自己選定的內容有效和可靠性進行大體判斷。以筆者做的高頻研究舉例,首先是自己選定的高頻因子 邏輯上是否符合條件,然後是高頻因子是否在時序上有自回歸的特性,接著判斷高頻因子與短期股價的收益率是否能夠保持在比較 長時間 IC 或 IR 為正的情況,筆者這裏直接偷懶,用因子與收益率做一個累計線性相依性判斷,一般平穩向上的就認為該因子可 以納入候選。下圖來自海通證券的馮佳睿 【高頻因子的現實與幻想】,讀者們感興趣完全可以去用馮首席他們對高頻因子的評價手段,
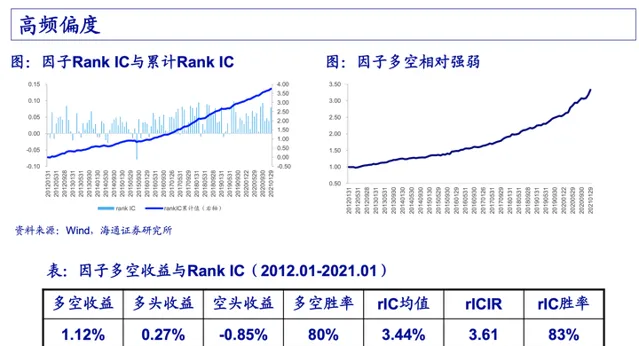
- 工程預實作 這塊內容比較復雜而且耗時持久,筆者這裏特意寫了 "預實作", 是因為這塊內容下半部份,即由客戶采用,並被上規模的資金驗證 尚未達到。這塊內容再下個章節中進行闡述。
工程預實作
這一塊內容,筆者大體分了幾大部份進行實作。
數據清洗與處理
這一塊是重中之重,數據的好壞往往能決定研究結論的對錯。筆者現在某 TOP 券商任職,來自公司層面的數據支持還不錯,因此筆者 有幸拿到了交易所原始數據進行研究。但是,即便是交易所的數據,一樣埋藏了各種暗坑,使用時也得小心再小心。
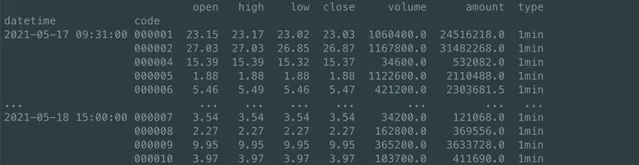
- 數據重復問題:量價數據在表現形式上其實是一張表格,如下圖,是來自 QUANTAXIS 已經處理好的分鐘數據表,QUANTAXIS 已經 設定好了索引和列名,但是很多時候,原始數據會面臨重復數據問題,此時,可以參照 QA 的做法,設定好索引,然後 DROP 掉 重復數據
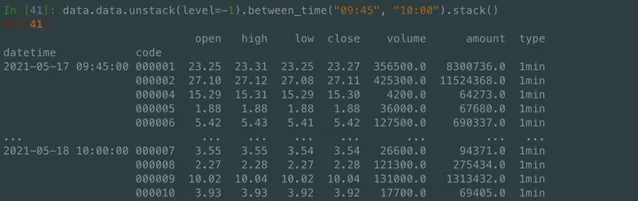
- 非交易時段數據過濾: 有點坑的是,來自交易所數據會有非交易時段的數據,不註意可能在非交易時間去模擬交易了,這裏如果讀者 使用 pandas 進行數據分析時,對時間過濾有個小技巧,對於多個日期跨度下,進行小時和分鐘的時間戳的過濾,可以使用 between_time, 對於 pd.MultiIndex, 則可以先 unstack(level=-1) 然後在進行 between_time 的時間篩選
- 降采樣的問題: 來自交易所的數據並沒有分鐘數據,一個方案是對交易所數據進行降采樣,但是,當你降采樣之後,你會發現,不同 的資料來源的分鐘數據都不相同,來自行業內的交流,甚至快照數據,不同資料來源都不一樣,很多機構只能自己采集 Level2 數據後 自行進行降采樣處理。註意, 降采樣還有一個不註意就很容易引入未來數據的大坑 , 使用 pandas 的降采樣預設是左對齊 的,於是,同樣的 9:30 ~ 9:31 分降采樣的分鐘數據,其時間戳對應的是 9:30 分,從理解上,可能設定為 9:31 分才更合理, 多個資料來源對此貌似都沒有加以說明,直接就用的 9:30 作為這個分鐘的分鐘 bar 了,這一塊,得表揚下金塊量化的數據,他們 的分鐘數據是包括了 'bob' (BAR 數據的起始時間) 和 'eob' (BAR 數據結束時間)。對降采樣,其實只要特征與標簽設定一致即可, 筆者這裏是用 9:25 ~ 11:30, 13:00 ~ 15:00 的逐筆數據進行分鐘降采樣後,丟棄 NaN 值,然後再進行 Resample, 最後 統一 shift(1), 這樣,既考略了集合競價的數據,有將非交易時間的數據丟棄,同時還保證了數據是以分鐘結束的時間戳作為 這個分鐘 bar 的時間戳。
因子合成
高頻因子這裏,筆者覺得挺多人也有誤區,覺得只要我有數據了,隨便亂造,亂七八糟組合起來就可以上高大上模型了,就可以有很好的 效果。其實,從筆者的經驗來說,很多簡單的價量數據拼接,已經沒有什麽價值了,從邏輯上我們也判斷出來,這麽多家大型電腦構,又是 遺傳規劃, 又是超算等硬體加入,如果有簡單的因子,機構間同類競爭已經把湯都吃幹抹凈了,對於其他量化研究而言,在高頻因子構成 上,尋找一些更有邏輯價值和意義的方式,也許才更有意義。不然那麽多大機構招聘各類手工挖因子的人意義何在呢?對吧。
高頻因子的合成其實在技術上也會有個困難。隨著時間頻率降到快照,逐筆的時候,數據量會達到幾十上百 GB, 如果還用 pandas 去進行 數據分析很容易碰到效能瓶頸。但是 pandas 有著這麽多優秀的介面,直接放棄還是挺可惜的,這裏筆者推薦讀者們試試 dask 進行 多行程的數據處理分析,至少在價量數據這一塊,單機還足夠。這裏介紹一個小技巧,其實可以按股票進行分別設定 delayed task, 最後將這些 delayed task 拼接成 dask.dataframe 進行處理,速度還可以。
之前在行業群裏有人問過一個問題,他想拿過去 100 根 bar 的數據合成各種亂七八糟的技術指標,不太懂如何去匹配到機器學習模型上, 其實,想明白了也挺簡單的,假設當前時刻為 2021-05-28 10:00:00, 前 10 分鐘的數據拼接成的不管什麽因子,在表現形式上是一行, 這一行的時間戳就應該是 '2021-05-28 10:00:00', 然後這些因子對應的未來的價格漲跌幅,其即時間戳也應該是 "2021-05-28 10:00:00", 這樣,輸入的 features 與 labels 形式上就統一了,可以隨便套用到不管是 scikit-learn 還是 pytorch 等各類機器學習庫上了。
標簽生成
標簽生成第一個容易讓人困惑的點是在時序場景下,未來價格漲跌對應的標簽怎麽對應到當前時刻上,筆者在因子合成中也分享了自己的 經驗。
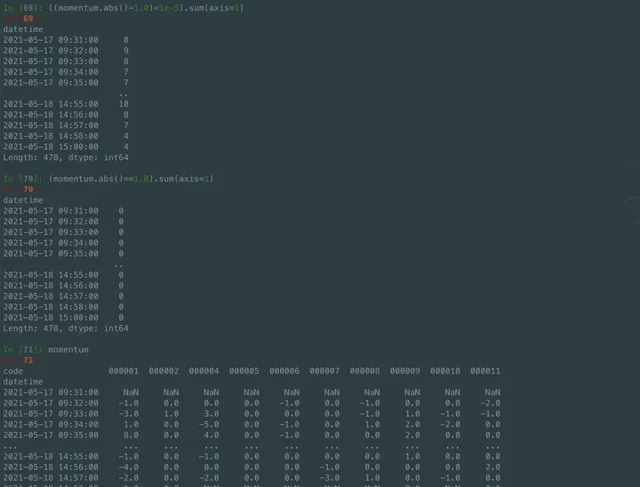
這裏筆者想特意著重強調在 pandas 中踩到的一個坑,即浮點型別的比較問題。讀者朋友們如果想要針對 pandas 中某個數據進行 比較的時候,如果對應列的數據型別是 float, 千萬千萬不要直接使用等於進行比較。特別感謝來自同事黃鈺的提醒,沒有他的仔細 核查,筆者也不會觀察到這麽細節的坑。所以啊,做事千萬千萬也認真仔細,不然一個小坑會把自己坑的特別慘。
模型選擇
學術上現在有著各種各樣的高大上模型,但是在實踐上,有些高大上模型其實落地會遇到這樣那樣的困難。尤其在某些特別註重安全的 場景下,神經網路一套,最後來個黑箱模型,有沒有過擬合,如何對有效性進行評價,有效原因是什麽無法解釋,如果碰到極端行情 的時候,但是模型又沒有很好地應對方式,很容易出問題。
這裏感謝同事的非常有經驗地提醒,先專註一個簡單模型,做精做透了,然後再去思考模型的缺點與可改進的方式,不要一開始就想著 各種復雜模型,自己都沒搞清楚模型細節,最後花了好多時間,卻沒有得到好的效果,時間就白費了。之前看到知乎有同學分享用 GDBT 然後加上 LR 進行模型構建,邏輯清楚明白。但是等筆者做完 LR 後,回過頭來加上 GDBT 後,卻並沒有達到提升績效的效果, 當然也可能是筆者用法不太對。
此外,筆者還想分享的一點是,工程上,上模型並不要求把對應模型論文看了,源碼看了,大處著手,了解模型原理,知道每個參數 意思,其實可以節省很多時間。最開始筆者直接套用 LR 的模型參數設定,也沒註意模型參數的意思,自己哼哧哼哧半天做了個樣本 均衡處理,最後發現原來模型自己就已經有樣本均衡的參數設定了,白費了不少功夫。
績效評價
績效評價不同的機構有不同的觀察維度,這裏筆者想分享的是,對績效評價,需要根據套用場景去找對應的指標。舉個例子,醫院檢查 的時候,更應該關註的是召回率 (Recall), 因為一旦某個疾病沒有被查出來,面臨的困境可比查錯了再復查更艱難。而在股票買賣 上,更多時候是寧錯過,勿做錯,因為買錯了面臨損失與不買沒失真失可是兩碼事,也因此,在金融場景下,很多時候,查準率 (Precision) 會更重要。在之後的模型最佳化上,也可以根據自己關註的指標,進行有針對性地閾值 cut.
樣本選擇
其實這一塊在筆者面臨的場景下,倒還好,畢竟高頻數據還比較足夠,可能更多的問題在於大量數據的處理耗時上。有一點需要註意的是, 在簡單評價模型時,可以用同一批數據來做,但是最終評價,最好還是在時序上做一個迴圈驗證。譬如,拿一周數據訓練,一周數據驗證, 然後在幾個月或者一年時間範圍內,按照一周一個時間視窗對訓練集,驗證集進行分割,得到時序上,樣本上的穩定可靠的結果,對同事 和領導才有說服力。
結語
筆者的一些淺薄經驗,可能很多讀者都已經趟過這些渾水了,如果有任何的建議和評價,歡迎留言,正好筆者還在緊張地開發改進計畫中, 可以白嫖大家的經驗,想必是非常好的。










