我從工程師的角度來聊聊自動駕駛背後的效能最佳化。
使用深度學習技術來攻克自動駕駛是業界的共識。我們知道深度學習分為訓練(training)和推理(inferencing)兩部份,在自動駕駛中訓練在伺服器中完成,推理則在車子裏進行。隨著自動駕駛的模型越來越復雜,訓練過程中的計算量和數據量都越來越多,單張 GPU 已經無法勝任,多 GPU、甚至多節點分布式訓練,已經成為了行業標準。
在這個背景下,自動駕駛的 GPU 分布式訓練,成為了端到端解決方案中非常重要的一環,而通訊瓶頸是一個必須解決的效能關鍵點。
自動駕駛訓練帶來的挑戰
訓練一個自動駕駛方案依賴大量的真實數據。數據采集車配備多個傳感器,主要包括網路攝影機、雷達和雷射雷達。所采集的數據被用於構建輔助汽車駕駛以及駕駛員監控和協助的AI。數據采集車通常使用6-10個網路攝影機、4-6個雷達和2-4個雷射雷達,它們都有不同的分辨率和距離範圍。整個數據采集量由網路攝影機占主要,保守估算,一輛測試車每天產生的數據量可達 10 TB 。
更大規模的數據集與更短的訓練時間的訴求, 僅依靠單張 GPU、甚至單台 GPU 伺服器已經無法滿足自動駕駛 AI 訓練的要求,多機多卡 GPU 分布式訓練成為必然選擇。NVIDIA 使用 1400 張 V100 GPU 集群訓練 BERT-Large,不到 1 個小時就可以完成訓練。
AI 模型越龐大,模型參數越多,訓練過程中的通訊消耗也越大。一些大型 AI 模型的訓練過程中,通訊時間消耗占比已經超過 50%。在最佳化端到端的效能時,我們既需要考慮伺服器內部的通訊,也需要最佳化伺服器外部的通訊。
最佳化伺服器內部的通訊瓶頸
伺服器內部的通訊主要有
在高效的伺服器架構中,CPU、GPU 和 IO 之間需要盡量做到兩兩直連。
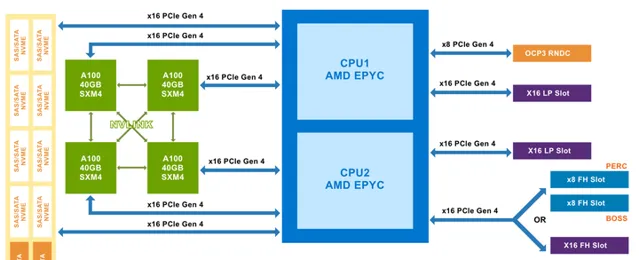
我們先看下 NVIDIA 官方的 DGX Station A100 的外觀圖和硬體架構圖,單路 AMD 羅馬 CPU 加四塊透過 NVLink 全互聯的 A100 GPU,任何一塊 GPU 都可以高速存取其他 GPU 的視訊記憶體。CPU 和 GPU、CPU 和 IO 之間透過 x16 PCIe Gen4 進行直連,頻寬是上一代 PCIe Gen3 的兩倍。由於追求辦公環境的全靜音設計,效能方面有一定的妥協。

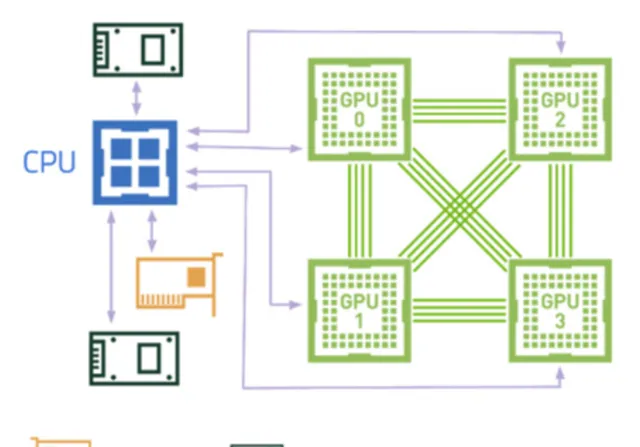
再看下合作夥伴的設計,下圖是 Dell家的 PowerEdge R750xa 及 XE8545 伺服器的外觀圖及硬體架構圖。先看XE8545,NVlink全互聯的四路A100,與DGX Station A100 設計類似,但 XE8545 要早半年推向市場。CPU升級為雙路AMD米蘭,更大的機箱,更多的記憶體和IO,全風冷散熱。由於不用考慮辦公環境的靜音,在設計上毫無妥協,完全釋放硬體效能。同為4*A100的R750xa采用了 不同的設計:NVLINK Bridge 。盡管只能實作GPU之間的兩兩相連,但倆GPU之間的頻寬大大提升到了600GB/s(註:NVlink在4*GPU互聯情況下,GPU兩兩之間的頻寬只有200GB/s)。另x16 PCIe Gen4 的全面覆蓋使得 CPU、GPU 和 IO 之間盡量直連,保障資料通訊與 IO 傳輸效能。

訓練 AI 模型的過程中會反復讀取同一組數據集, 以提升模型精度。如果暴力地進行反復讀取,那麽很卡就會用光通訊頻寬。在 PowerEdge XE845架構中,最高支持 8 塊 NVME SSE 硬碟來緩存這部份數據,以實作高效能的本地儲存。
最佳化伺服器外部的通訊瓶頸
為解決 GPU 分布式訓練過程中的通訊瓶頸,硬體層面開啟 GPUDirect RDMA(簡稱 GDR),是非常有效的效能最佳化方案。透過 GPUDirect 技術呼叫 RDMA 通訊庫,一個伺服器節點上的 GPU 可以直接將數據從其視訊記憶體發送到目標伺服器節點上的 GPU 視訊記憶體,而不需要經過兩個節點上的系統記憶體。AI 訓練過程中的每一個數據字節,不需要繞路到系統記憶體進行嚴重拉低效能的記憶體拷貝,從而顯著提升機算效率。
沒有 GDR 時,CPU 必須將數據從 GPU 視訊記憶體拷貝到系統記憶體,再透過 InfiniBand 傳輸給另一台伺服器。開啟 GDR 後,不同伺服器中 GPU 間的通訊不再經過 CPU 和系統記憶體,即只經過下圖中綠色的路線。
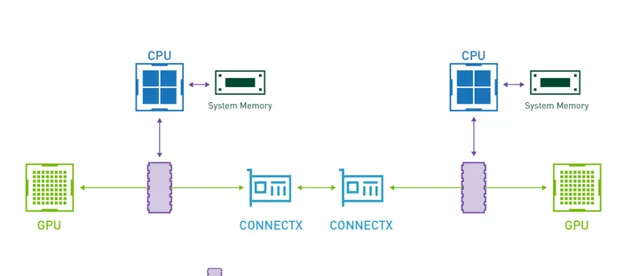
PowerEdge XE845伺服器基於 Mellanox 200Gb HDR / 10Gb EDR Infiniband 交換機實作原生 RDMA,Dell Networking 自研的 100Gb / 25Gb 網路交換機部署 RoCE,提供低於 TCP / IP 協定的參數同步通訊延遲。
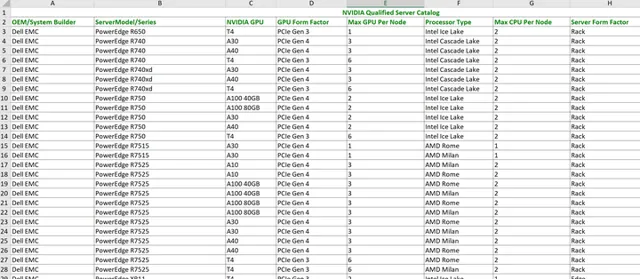
出於上述對效能、穩定性等重要因素的考慮,NVIDIA 會對合作夥伴的伺服器設計進行企業級認證。目前能透過 NVIDIA 認證的企業級邊緣伺服器一共有51款,其中僅戴爾一家就占據了31款,高居榜首。
更多閱讀資料











