「大清早我還沒睡醒,無人車就把我送到了公司,然後它自己去跑滴滴了」——啊,一切渾然天成,我們都過上了告別996的幸福生活,關鍵是無人車還能幫我搞錢(手動狗頭)~

說實話,自動駕駛的藍圖很美好,但自動駕駛不是某類單點突破的技術,要實作真正意義上的自動駕駛,那可不是一般的難——難就難在它的不確定性和復雜度。
自動駕駛從L1到L5,有個簡單粗暴的說法——L1:不用腳,L2:不用手,L3:不用眼,L4:不用腦;L5:不用人。每一個級別的提升,背後都是一大堆的黑科技,不過,要說到自動駕駛的最黑的黑科技,得從它的核心技術說起——
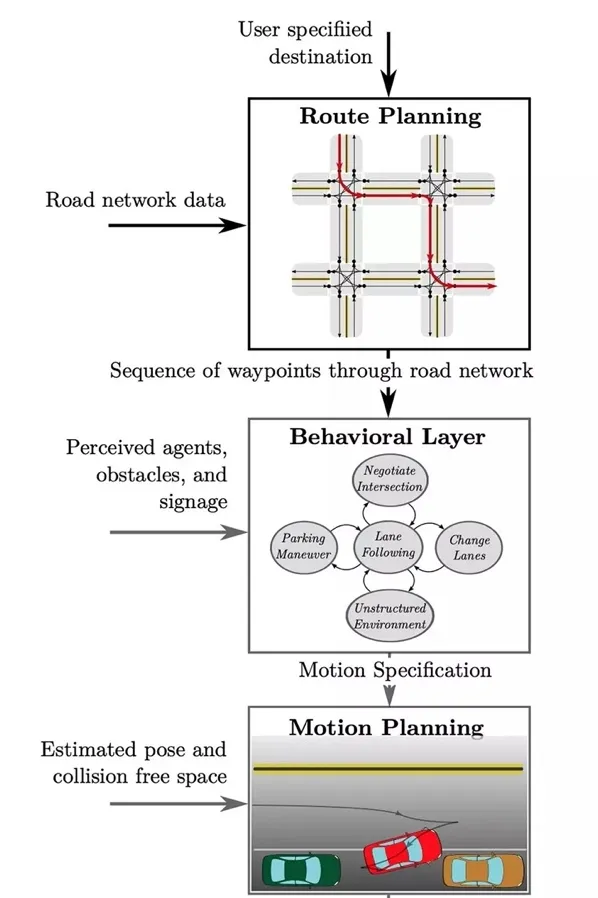
一、自動駕駛中的硬核科技:感知和規劃
自動駕駛作為一個交叉學科領域,和人工智慧技術緊密相聯,你想在自動駕駛上「快樂地吃著火鍋」,那就需要你的車能在邏輯、感知、融合、預測、規控方面形成一個完整的行為閉環。

同時,由於自動駕駛需要確保100%的安全性,又無形中推高了傳統汽車的固有標準,比如自動駕駛中的「感知」和「規劃」,就是兩個有著非常多「黑科技」的核心技術模組:
1.智慧感知:
自動駕駛能成為「智慧的車」,靠的就是傳感器這一雙雙眼睛。
自動駕駛汽車的感知分為環境感知和狀態感知,既要看清楚周圍有什麽——這兒是車道,紅燈還是綠燈,右邊突然來了輛車,還要對自己的狀態心裏有數——我在哪裏,車速多快。傳感器「眼睛」感受外部環境,采集到足夠的資訊,再去上報給「大腦」。這是實作自動駕駛最關鍵的一步,是最重要的環節。
透過「單車智慧」,也就是依靠車載傳感器可以做到對道路的「平視」,獲取自動駕駛汽車行駛過程中的車速、輪速、檔位等資訊,探測到汽車周圍的障礙物資訊,比如車輛、行人以及路肩的情況,這就有了」智慧的車「。
然而僅僅依靠「平視」所搜集的有限資訊,顯然是不足以應對一些意料之外的道路情況,比如令無數老司機聞風喪膽的「鬼探頭」,和前方大車帶來的視野盲區,都會成為道路上的不穩定因素。

這個時候就需要依靠車路協同系統,做到對整個街區路況的「俯視」,這是」智慧的路「。

舉個例子,自動駕駛汽車之所以能夠超絲滑地完成自動泊車,或是在環島中完成一些列的動作,是因為無人車在研發階段,對道路進行過N多次的測試,生成了毫厘不差的高精地圖,再加以車路協同系統準確定位地形、物體和道路輪廓,才能讓自動駕駛汽車做到許多駕考人做不到的完美動作。
2. 智慧決策
自動駕駛汽車采集到的上文說的這些數據之後,需要經過它的「大腦」——計算單元,才能轉化為控制訊號,實作智慧行駛。簡單來說,計算單元就是「下任務」的——保持車距、車道偏離預警、有障礙物、該轉向了……大腦給出決策,交由下一環節執行。
說實話,在L2及以下的時代,這個「大腦」的存在感並不是很強,但是L3及以上,智慧決策模組是衡量和評價自動駕駛能力的最核心指標之一。
比如在極其復雜的真實駕駛場景中,如何基於歷史資訊和傳感器收集的即時數據的態勢,進行判斷和預警,比駕駛員快一步做出決策;如何做到對行車路徑的整體和局部規劃,並肩負著「副機長」的角色,根據即時預測做出動態決策和瞬時響應。
所以嚴格地說,今天自動駕駛的關鍵技術已經發展得相當不錯了(已經不是這個行業的最大挑戰),要說 自動駕駛面臨的最主要的挑戰,還是來自於自動駕駛研發的核心——在智慧決策的過程中,無人車的「大腦」需要對數據進行快速的計算分析、處理,由此帶來的算力、儲存、網路以及工具鏈環境等方面的問題。
特別是隨著視覺感知的技術突破,推動了其他傳感器(比如雷射雷達和公釐波雷達)的感知演算法以及多傳感器融合演算法的進步,同時也加速了自動駕駛數據湖的形成,自動駕駛等級和算力需求也隨著數據量的提高逐漸增加。
二、自動駕駛研發過程中的挑戰——「四座大山」
如上文所說,數據以及基於數據的AI計算和AI算力,是決定自動駕駛量產能力的勝負手。自動駕駛所形成的海量數據池帶來的計算能力、數據儲存、網路頻寬和工具鏈環境的挑戰,成為壓在自動駕駛研發過程中的「四座大山」。
眾所周知,AI計算是一個軟硬體高度繫結的套用,對於車路協同的自動駕駛汽車來說,車載網路傳感器和高精度地圖的緊密配合,加之V2X車用無線通訊技術的加成,固然會極大拓展自動駕駛汽車的感知範圍,讓自動駕駛汽車站在「上帝視角「看路況,可以解決大部份的風險問題。
但是一個無可避免的問題就是邊緣裝置即時產生的大量數據的問題。眾所周知,自動駕駛汽車上搭載的傳感器和網路攝影機,大約每秒鐘就可以收集1GB左右的路況資訊,且如何解決數據泛化問題,也是自動駕駛業界一直在探索的課題。
事實上,不僅僅是自動駕駛,當前這一波AI商業化浪潮的主要技術推動力是深度學習,深度學習的最大優勢就是基於多層神經網路的自學習特征,它可以對像是語音、影像和文本這些非結構化數據有一個非常好的處理效果,但是這也意味著我們需要提供更高的芯片計算能力。
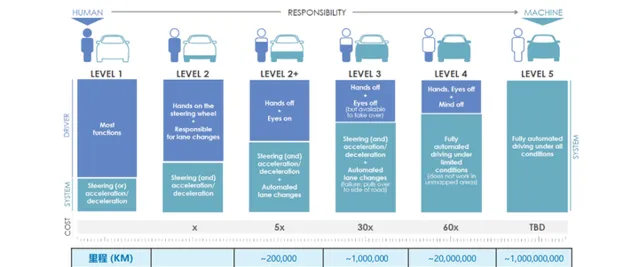
而對於自動駕駛而言,它本身就是一個天然的多模態,自動駕駛汽車搭載的多種傳感器收集了不同型別的數據,突破了以往單一模態模型的數據形式。與此同時,對算力的挑戰又上了一個台階。
對於需要車路協同的自動駕駛汽車來說,如果不能在毫秒間完成計算並將計算結果迅速反饋,很容易造成交通事故。而傳統的雲端運算模型,顯然不適合對低延時和高可靠性具有較高要求的套用場景。這也是為什麽像自動駕駛的車車、車路協同系統,往往都需要將計算推向網路邊緣,利用邊緣算力減少數據的傳輸延遲,從而保證數據的即時性和安全性。
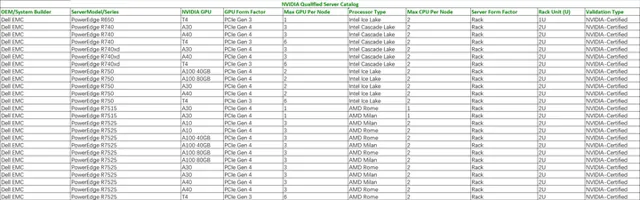
作為邊緣計算的典型場景,自動駕駛研發對於算力的要求,實際上是對於企業級邊緣伺服器的要求。 可以看到目前NVIDIA認證的企業級邊緣伺服器一共有51款,在這其中僅戴爾一家就占據了31款。 (更多資訊可點選: NVIDIA認證的企業級邊緣伺服器列表 )
隨著AI算力需求的快速增長,AI演算法模型越來越朝著大模型、多模態的方向發展,最初的單主機多行程和後來的CPU平行計算都顯得有些力不從心,AI計算需要更大規模並列性的計算技術。
2011年,Andrew Ng將GPU引入到谷歌大腦,GPU開始成為強化學習、深度學習的主流計算技術,也因此許多專門支持高密集GPU工作負載的伺服器就應運而生了,比如戴爾的PowerEdge R750xa 和XE8545。

(連結奉上,感興趣可以進入官網了解):
在自動駕駛訓練過程中,數據呈現指數級增長。小到十萬級別,大到百萬、千萬甚至上億級別,給後設資料管理、儲存效率和存取效能帶來了巨大挑戰,以及儲存」IO墻「的出現。勢必會導致更長的AI模型開發周期,使GPU處於饑餓狀態,影響到數據采樣的範圍和精度,最終影響分析的準確性。
尤其是而對於數據處理模型的訓練,需要頻繁在儲存裝置中讀寫數據,因此,儲存的分布式檔案系統就極其關鍵,尤其是後設資料處理的能力。
隨著自動駕駛訓練時間、網路數據量和應用程式暴漲等情況,自動駕駛對網路頻寬的需求也開始水漲船高。原有儲存網路沒辦法支撐大規模、並行式的存取,因此效能問題頻繁發生。
除了上述幾點,自動駕駛開發中還有一個最大的痛點——工具鏈的相互分割和數據孤島現象。
在行業發展之初,可以說是各自為營的局面,傳統的工具鏈公司大都會聚焦於某一個環節,做到垂類發展。然而對於實際生產過程而言,工具鏈的使用並不是單一的,而是要打好配合。此時二者的弊端就開始顯現了。
三、自動駕駛研發背後的技術支持
AI領域的不斷突破,為自動駕駛發展提供了強有力的內生動力,但種種現實情況表明,自動駕駛若想達到L5以上級別,顯然不能脫離強大的IT基礎設施的支持,這就需要通訊方案提供商、終端服務商等眾多環節的共同參與,肩負起行業推動器的角色,發揮平台作用,將孤島資源串聯在一起。
比如在人工智慧方面,戴爾科技構建了面向自動駕駛汽車的基礎架構解決方案,這一方案基於采用了AMD EPYC處理器的PowerEdge伺服器構建,透過更高的計算資源整合度、更多的PCIe鏈路以及記憶體通道,能夠顯著提高數據密集型工作負載的計算能力,滿足人工智慧訓練苛刻的算力需求。
同時,針對AI GPU分布式訓練,從IT系統工程角度,結合計算、網路、儲存硬體最佳化及框架軟體層面最佳化,從端到端為使用者提供整體的AI GPU集群架構設計與分布式訓練最佳實踐。
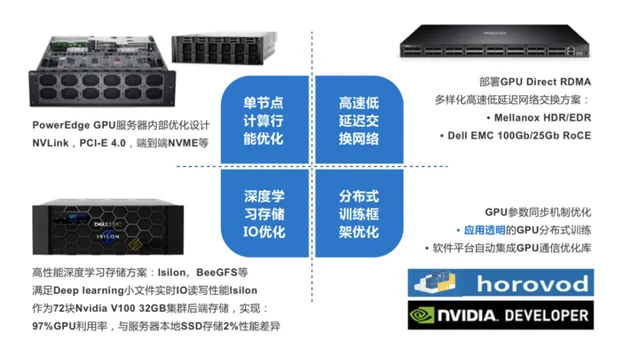
而在車路協同的落地方面,為了減少數據在「路上」的時間,給自動駕駛決策帶來影響,戴爾科技針對數據在跨邊緣、核心、雲之間的傳輸提供極高的I/O效能。
所謂「軟體決定自動駕駛的下限,而硬體則決定了自動駕駛的上限」。如果說在自動駕駛研發中真的有哪些「黑科技」,那應該就是非AI基礎設施的支持莫屬了,它的發展程度,決定了我們是否能真正實作「出行的樂趣」。
一步一步來吧。











