23年6月26号,ETH在arxiv挂出了他们最新的论文,视频暂时还没有放出来。推测这篇应该是投了science robotics。
我们趁热打铁来分析一波这篇论文。
原论文链接:ANYMAL Parkour
前言
ETH连续三年在science robotics 上发表论文,内容从blind locomotion 到perceptive locomotion。终于,在和Nvidia 强强联手,淘汰Raisim用上isaac gym, 再到发表了几篇perception和3D重建相关的论文之后,结合perception 的multi skill locomotion + high-level planning 的问题被汇总集合成了一整个成熟的系统。
总结来说这篇文章 约等于 前三篇locomotion skill 加一些agile skill 再加上 感知和规划部分, 即加入了 [1] [2] 的部分。
个人认为其中最大的贡献还是在于新加入的 感知和三维重建 部分。但同时文中展示的跳跃,攀爬等动作的确十分惊艳(跳过1.2m的沟,爬上1m高的箱子等)

硬件
配有12个峰值扭矩85Nm的SEA的55kgANYmal-D。其上搭载6个深度相机(前2后2左1右1)+ velodyne Puck LIDAR + NVIDIA Jetson Orin。整个系统依赖于ROS操作系统。
在执行某些极高难度的动作时,关节力矩输出瞬间直接拉满,同时关节位置也接近极限位置。可以看出来对硬件稳定性要求极高。
总体框架
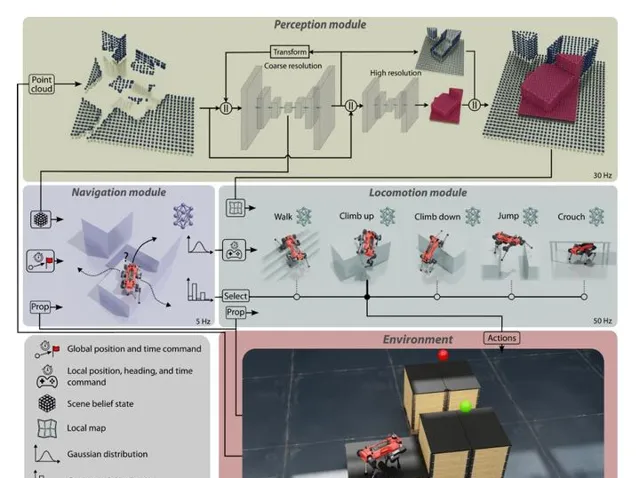
如文中Fig2所示,整个系统分为三个大模块:感知(perception),导航(navigation) 和行走(locomotion)。总共由8个神经网络完成。其中感知2个,导航1个,行走5个(walking, climb up, climb down, jump, crouch)。整个系统能够让四足机器人完成自主的Multi-skill 自适应行走和goal-conditioned 导航。
navigation 模块和locomotion 模块使用hierachical(层次连接) 的方式进行,即navigation 模块只负责输出high-level 指令,并由locomotion 模块接受高层次指令,并输出关节空间的控制指令。
perception 获取雷达和深度相机提供的点云信息,进行环境重建,在 [2] 的基础上提出了 「多分辨率」重建 ,以降低大地图对硬件资源的消耗。具体来讲,机器人周围的地图分辨率高,较远的地图分辨率低,高分辨率地图方便locomotion做精确的足端规划,低分辨率地图提供「远景」,方便navigation 进行规划,同时降低存储负担。
Locomotion
locomotion 基本沿用之前 [2] 的perceptive locomotion 框架,但加入了position input,做一个position-based goal tracking.
总体上讲与 [4] 区别不大,但已经属于比较hard 的动作,调reward和解决sim2real 问题应该很费时间。
与常见的速度跟踪policy 不同,这里直接以位置作为输入,policy去跟踪一个全局位置 [1]
Navigation
该模块接收来自感知的结构化数据,并完成选择动作类型,和确定waypoint position的工作。
本质上是一个local planner。
navigation 直接通过reward信号来鉴别在各个场景下最适合的locomotion skill, 如下图,不同高度平台,navigation framework会给出不一样的规划路线。

Perception
上述两个模块都需要perception 提供的信息。

主要成果
从论文内容上看,整个ANYmal四足系统现在已经趋于完善,系统性很强,工作量巨大,是在大量子工作积累的基础上汇总,改进形成的完整框架。就好比之前已经盖了100层的楼上再封个顶。期待视频最近能放出来。
个人认为这种工作复现难度极大,要想调到每一个模块都像文中这样稳定和鲁棒十分困难。同时也对硬件平台的稳定性要求很高,需要解决的工程问题相当多。
参考
- ^ a b N. Rudin, D. Hoeller, M. Bjelonic, and M. Hutter, 「Advanced skills by learning locomotion and local navigation end-to-end,」 in 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2022, pp. 2497–2503.
- ^ a b c d D. Hoeller, N. Rudin, C. Choy, A. Anandkumar, and M. Hutter, 「Neural scene representation for locomotion on structured terrain,」 IEEE Robotics and Automation Letters, vol. 7, no. 4, pp. 8667–8674, 2022.
- ^ F. Abdolhosseini, H. Y. Ling, Z. Xie, X. B. Peng, and M. Van de Panne, 「On learning symmetric locomotion,」 in Proceedings of the 12th ACM SIGGRAPH Conference on Motion, Interaction and Games, 2019, pp. 1–10.
- ^ N. Rudin, D. Hoeller, P. Reist, and M. Hutter, 「Learning to walk in minutes using massively parallel deep reinforcement learning,」 in Proceedings of the 5th Conference on Robot Learning, ser. Proceedings of Machine Learning Research, A. Faust, D. Hsu, and G. Neumann, Eds., vol. 164. PMLR, 08–11 Nov 2022, pp. 91–100. [Online]. Available: https://proceedings.mlr.press/v164/rudin22a.htm











