
作者/幂律法律部 张丽峰
ChatGPT是由OpenAI在2022年11月30日发布的对话式通用人工智能工具,甫一问世即成为史上用户增长速度最快的消费级应用程序,上线仅五天,就突破了百万用户;在推出后短短两个月的时间内,月活用户就已经突破了一亿。今年2月份以来,国内多款大模型产品相继发布:MOSS、ChatGLM、文心一言、日日新、通义千问、知海图AI、天宫3.5、星火……更多的大模型产品也将陆续面世。
当前市面上的大模型产品以「通用大模型」为主,此外也有许多厂商瞄准垂直领域开发大模型产品,如自动驾驶领域的雪湖·海若、金融领域的BloombergGPT等, 幂律也在紧锣密鼓地研发法律领域的大模型产品。 那么为什么有了通用大模型,还需要研发法律大模型呢?本文从法律领域的特殊性出发, 向读者解释法律大模型的研发必要性,并探讨法律大模型产品研发过程中面临的挑战。
一、有了通用大模型为什么还需要法律大模型?
通用大模型在语言翻译、文本生成、数学计算等领域都有着不俗的表现,但从法律从业者的试用反馈来看,通用大模型对法律问题的回答效果却并不理想。究其原因,是由于法律要求高度的专业性和准确性、法律语言具有特殊性、法律存在文化和地域差异,法律行业对大模型产品提出了更高的要求,训练法律领域的大模型势在必行。
1.法律的专业性和准确性
大模型通常采用Transformer架构,在此架构下模型被要求根据前面的信息来预测后面的内容,模型通过计算接下来备选内容的概率选择后续的输出。在法律问答任务中,大模型给出的答案实际上是根据用户的提问推算得出, 故而它可能生成离题、不够专业或不准确的答案,而法律工作对此类错误的容忍度是很低的。
一方面,法律问答通常涉及法律的解释和适用,法律条文的内容是精准的,需原文引用;基于对法律规范的准确理解,才能提供正确的法律指导。另一方面,法律问题的处理常常关涉人身财产权益, 不准确的回答容易产生误导,对当事人的决策和行为产生重大影响。
普通民众的法律知识有限,难以鉴别大模型回答中可能存在的问题,如果每一个回答都需要用户自行验证,将与大模型在法律领域提供更加便捷法律服务的初衷相悖。
法律大模型通过高质量的法律数据库保证专业性,并根据法律领域的特点进行针对性的模型训练,同时加入提示词工程,以此提高法律问答的准确性,在常见法律问题上法律大模型通常能给出更准确的回答。
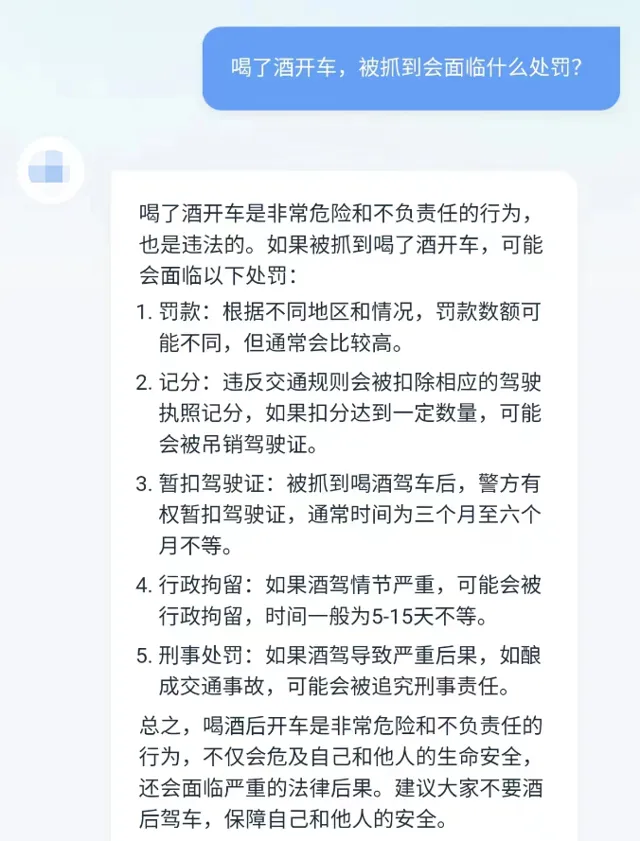

如上图例是国内某通用聊天机器人和幂律大模型对酒后驾车这一问题的回答。喝了酒开车在法律上区分为酒驾与醉驾两种情形,法律规定包括【道路交通安全法】第九十一条和【刑法】第一百三十三条之一。酒驾和醉驾面临的处罚包括暂扣驾驶证、吊销驾驶证、罚款、拘留以及可能承担的刑事责任,根据情节不同行为人面临的具体处罚也会有所不同。
由图可知,通用聊天机器人虽然能回答出面临的处罚种类,但答案比较笼统模糊,且未对酒驾与醉驾两种情节作区分,也未能给出法律依据; 而幂律大模型则区分了酒驾与醉驾两种情形,针对二者分别列明了具体处罚标准,并给出了准确的法律依据。
2.法律语言的特殊性
法律语言的精确性、特定性和逻辑性使得它与日常生活语言有明显区别。
法律语言要求准确和专业,需要使用准确的词汇及特定的表达方式来减少歧义。在法律领域,公民与自然人、居所和住所、营利和盈利、批准与核准、欺诈和诈骗等相似词汇的适用范围有着严格的界定,以保证准确传达法律含义。以居所和住所为例,居所指自然人的居住地点,可以是一时的居住地点也可以是长期的居住地点;而住所则指民事主体进行民事活动的中心场所或者主要场所,一般是长期居住、较为固定的居所。
法律语言通常使用专门的术语,如民法上的无因管理、不当得利、刑法上的紧急避险等。专门的术语有助于确保法律条款的一致性和可靠性,并为法律行为和事实提供明确的定义,以便法官、律师和其他法律从业人员准确理解和应用。
此外,法律语言强调逻辑性,通常要求特定的语言结构。法律论证往往通过法律规则、案件事实和法律判断的司法三段论展开,重视对权利义务的分析,结合法律法规以及相关案例来加强论证的合理性和权威性;法律文件通常采用特定的结构和格式以保证条文清晰、易于解释和正确理解。
由于法律语言的上述特点,需要有专门的法律数据库,并且训练法律大模型。 通过法律文本训练而成的法律大模型才能具备对法律术语及复杂语言结构的理解和应用能力。
3.法律的文化和地域差异
幂律法律团队选择了数百个高频法律问题,由法律专家整理出答案,之后根据人工解答对比了ChatGPT和幂律大模型在这些问题上的表现。
以下是ChatGPT和幂律大模型对彩礼问题的回答:


关于彩礼的返还,法律规定在双方未办理结婚登记手续、双方办理结婚登记手续但确未共同生活、婚前给付并导致给付人生活困难这三种情形下返还彩礼的请求通常会被人民法院支持。
在此法律问题上,ChatGPT没有对能否请求对方返还彩礼进行正面解答,也没有对彩礼问题从法律角度进行分析并给出相关法律依据; 而幂律法律大模型则对此问题进行了明确回答,对题目进行分析并给出了相关法律依据。
最高人民法院关于适用【中华人民共和国民法典】婚姻家庭编的解释(一)第五条
当事人请求返还按照习俗给付的彩礼的,如果查明属于以下情形,人民法院应当予以支持:
(一)双方未办理结婚登记手续;
(二)双方办理结婚登记手续但确未共同生活;
(三)婚前给付并导致给付人生活困难。
适用前款第二项、第三项的规定,应当以双方离婚为条件。
ChatGPT通常无法给出具体、直接的法律回答,甚至在一些法律问题上给出「作为AI语言模型,我无法判断这种情况对你的具体影响……」、「具体情况会因为不同地区和文化背景差异而有所不同」这样的答案;同时, ChatGPT在回答法律问题时也较少提供准确的中国法律依据。
这种情况可以理解,据Open AI公布,用于训练ChatGPT的中文语料仅占全部语料的0.09905%,而其中中文法律语料就更少了。此外,国外大模型产品由于所属法律体系不同、语言翻译上的误差等也加剧了ChatGPT对中国法律问题作出准确回答的困难。
因此,为了向用户提供更优质、更高效的智能法律问答服务,不仅需要研发垂直领域的法律大模型, 更需要研发契合中国法律体系与国情的专业法律大模型。
二、研发法律大模型面临的具体挑战
我们期待体验在法律领域具有强劲实力的法律大模型,但是研发法律大模型面临着多重挑战, 这些挑战涉及模型训练、法律遵循、数据处理等方面。
1.对模型理解和推理能力的更高要求
法律具有高度的抽象性,法律人需要从生活事实中抽象出法律事实,从日常行为中抽象出法律行为,然后通过推理、论证等方式分析不同的事实和行为对应的法律后果及应对方式。
然而,日常生活中的行为是纷繁复杂的,一种法律行为在生活中可能有多种表现形式。例如,刑法上诈骗指以非法占有为目的,使用欺骗方法,骗取数额较大的公私财物的行为。而在日常生活中,诈骗可能以刷单、杀猪盘、传销、兼职、微商代理、裸聊等多种形式出现。以「杀猪盘」为例,这是一种新型网络电信诈骗方式,当用户提问涉及遭遇「杀猪盘」时, 模型需要根据「杀猪盘」及其他相关信息推理出用户实际是遭遇了诈骗。 之后,模型应根据关于诈骗的法律规定以及用户的具体情况进行法律推理与论证,最终给出处理结论并提供相关的法律依据。
这对法律大模型的语义理解和推理能力提出了更高的要求。推理能力是目前各种大模型着重提升的能力之一,而如何提高法律大模型在法律领域的理解和推理能力则是研发者必须直面的重要难题。
2.法律的时间效力对训练数据的影响
法律法规是解决各种法律问题的基础遵循,但法律是在不断变动的,社会需求、法律改革、司法实践的变化都可能会导致法律的新增、修正与废止。

上图是截至2023年3月13日十四届全国人大一次会议闭幕之时,我国现行有效部分法律目录。由图可知,诸如【商标法】、【专利法】、【公司法】等法律已经历了多轮修正,而【民法典】的生效更是导致【民法总则】、【合同法】、【婚姻法】等九部法律及相关立法、司法解释同时废止。
「立法者三句修改的话,全部藏书就会变成废纸。」从训练法律大模型的角度而言,法律的变动不仅会对作为训练语料的法律条文范围及版本产生影响,更深刻影响着作为训练语料重要组成部分的法学书籍、司法解释、法律文书以及庞大法律问答数据的准确度与适用性。
以法律问答数据为例,法律的变动会导致数据中存在法律关系变化、法律依据失效、条文序号与最新版法律无法对应等问题。
为了提高模型所需数据的准确性,研发团队应当密切关注法律法规的变动,及时更新语料,并将法律变动对模型生成法律回答的影响降到最低。
3.数据标注与模型训练问题
数据质量直接影响到模型的准确性与可靠性。由于法律数据具有复杂性和专业性, 因此法律大模型所需的训练数据必须由专业的法律人员进行标注。 为了保证标注数据的质量,需要专业、准确的知识架构,并遵循明确的标准及指南以减少标注错误和偏差的发生。
标注完成后,研发者应考虑进行多个标注者之间的相互审核、复审和质量评估,进而发现和纠正错误,以提高标注数据的准确性和一致性。
此外,由于法律的复杂性和专业性,法律大模型的训练将需要更高的时间和计算成本, 并需要通过持续的迭代优化以提升准确性。
法律大模型的研发需要 专业基础扎实的法律专业人士和实力强劲的研发人员通力配合,这是推动法律大模型研发的关键因素。 二者应共同致力于解决研发过程中的挑战和问题,相互交流学习,使法律大模型能够不断进步和发展。
4.非典型问题的处理
一些非典型问题,可能是法律尚未覆盖的新情况,或涉及到复杂的背景信息、具有行业特殊性、存在区域差异,模型数据难以涵盖此类特殊情形。例如在引起广泛讨论的「江歌案」中,在危急情形下被救助者是否对救助者负担安全保障义务这一问题曾被公众广泛讨论,实务领域、学术界对此问题尚且众说纷纭,法律大模型作为新事物能够给出权威结论的可能更是渺茫。
有鉴于此,对于非典型问题法律大模型当前难以提供非常具体、具有针对性的法律意见,此时可以提供一些初步的指导和建议并建议用户咨询专业律师。
未来,随着数据的积累,通过尝试新的技术方法, 法律大模型有望提高对各类问题的分析处理能力,为用户提供更智能、高效的法律建议和支持,推动智能法律服务的进一步发展和优化。 我们对法律大模型的潜能充满期待。
ChatGPT等通用大模型产品已经让我们看到大模型在所涉领域全面性上的惊艳表现,而研发法律大模型,则更让我们期待大模型在细分垂直领域的无限潜力。从2017年就深耕在「AI+法律」领域的幂律智能,联合国内新一代认知智能通用模型厂商智谱AI, 即将发布基于中文千亿大模型的「法律ChatGPT」,敬请期待!











