时间序列预测是一个重要的领域,这里介绍最新的M5 Accuracy Competition的总结分析。
M competitions
M Competitions迄今共举办了5界,主要目的是通过真实数据评估现有算法和最新算法。比赛相关文章主要发表在International Journal of Forecasting杂志上。
数据集
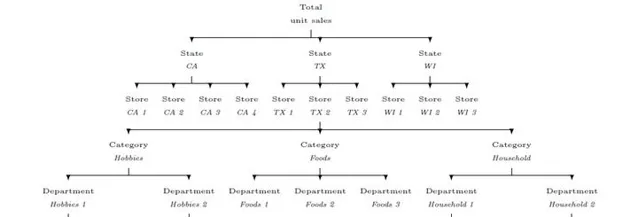
M5 Accuracy Competition数据集来自于沃尔玛的三个州,共涉及10个门店、3大类商品、3049个产品,总共42840条时间序列。
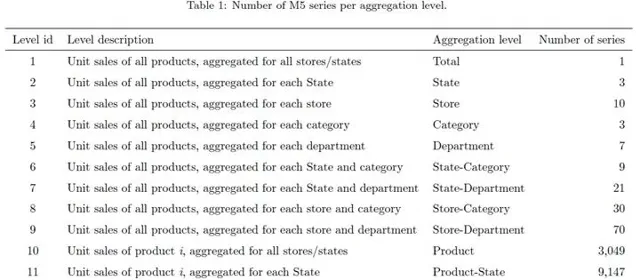
时间序列根据对象类别等级的不同,可以细分成12个层级。
时间序列数据从2011-01-29到2016-06-19,约5年半的天粒度数据,预测任务是未来28天的销量。
除了基础的天粒度销量数据外,还有额外的辅助信息,如日历信息、价格信息、节假日信息、促销信息。
Baseline
Baseline算法包括Naive算法、sNaive算法、Exponential Smoothing算法等。
在基准算法中,Exponential Smoothing算法的预测性能最好。
Results
算法优化的提升天花板
相比Exponential Smoothing基准算法,Winner算法的预测性能提升了 22.4% ,而在M3和M4中,Winner算法的预测性能提升不到10%
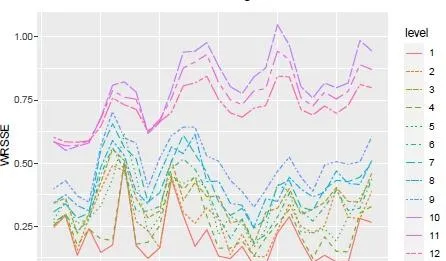
粒度越细,预测误差越大,预测性能的提升越少:最粗粒度的预测提升达40%,而最细粒度的预测提升仅3%
exogenous/explanatory variables可以提升预测性能:ESX算法相比ES算法,性能提升了6%,ARIMAX算法相比ARIMA算法,性能提升了13%
时间序列预测任务中,相比基准算法,可提升的空间约在3%~20%之间
尺有所短,寸有所长( Horses For Courses )
Winner算法并未在所有level上都取得最佳性能
预测性能的天花板与数据的粒度有关、与日历有关(工作日、周末等)
Top算法解决方案的特点
机器学习/深度学习算法,其中lightGBM是利器
集成预测,多种算法的集成(如算术平均等)
充分利用exogenous/explanatory variables
Cross-learning提升对序列之间的信息的利用能力
交叉验证(CV)可以提高算法的鲁棒性,指导算法策略的选择。在Winner解决方案中,通过交叉验证发现recursive model的整体准确率要高于non-recursive model。
The bene cial effect of external adjustments(未理解)
参考文献
- The M5 Accuracy competition: Results, findings and conclusions
![[表皮永生] 996违法,表皮干细胞也需要休息](http://img.jasve.com/2024-2/3e9ab2f59687e990984c214c63554720.webp)










