JUST团队-隋远
一、问题背景
近些年,网购已经成为人们一种重要的生活方式。据中国互联网络信息中心第45次中国互联网络发展状况统计报告显示,截止到2020年3月,我国网民规模为9.04亿,互联网普及率达64.5%,网络购物用户规模达7.1亿,2020年网络购物交易规模达11.76万亿元 [1] 。618和双十一这种购物狂欢节,更是各大电商的必争之地,如何通过有趣的应用吸引用户并成功引流成为每个电商平台这一阶段的重要任务。在此背景下,希望有一款基于订单数据的APP,可以让用户快速查看附近人的商品购买排行,以及自己在其中的购买力排名,这对于区域经济分析来说很重要,也能够有很大的趣味性。由于每个订单数据都带有空间位置信息,如:GPS报点信息或地名地址信息。同时,订单又天然包含下单时间。因此订单数据的分析是典型的时空数据挖掘问题。那么,如何快速地在数以亿计的订单数据中找到空间邻近、时间也邻近的订单数据,同时保障C端用户高并发的操作是此应用要解决的关键问题。
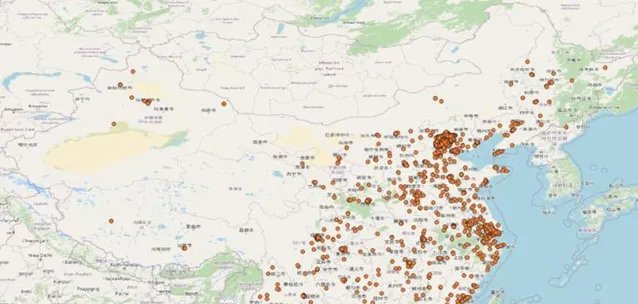
经过对数据的探查发现,全国的订单数据分布很不均匀。比如:某个比较繁华的社区在近7天可能有几万个订单数据,各种商品类目及画像数据都很丰富,不同排名都可得到top10数据。但有些人口比较稀少的地区7天内可能只有几个订单,甚至没有订单,这样会导致排名结果为空,影响用户体验。通过从历史库里对7天内的全国订单进行随机采样,可以看到这种分布情况。如图1北京及东部沿海地区的订单量非常密集,中部地区相对较少,西部地区则非常稀少。
二、现有方案
针对上述场景,我们需要找到一种对时间和空间维度都能高效过滤的查询方案,以保障用户能快速获取近期「附近」的购物数据。同时为了确保每次查询返回的数据足够进行分析排名,「附近」变成了一个可变的参数。能否合理的定义「附近」的大小也将影响产品的体验。基于已有技术我们尝试了如下两种方案。
2.1基于关系型空间数据库的KNN查询方案
以最流行的开源空间数据库PostGIS为例,需要进行两个步骤。首先通过KNN查询出给定位置周围足够数量的订单(比如5000个)。这个过程可以称为一级过滤。然后,对查询结果进行时间过滤。将KNN查询出的5000条数据根据时间字段进行过滤,得到最近7天的最终订单。这个过程可以称为二次过滤。
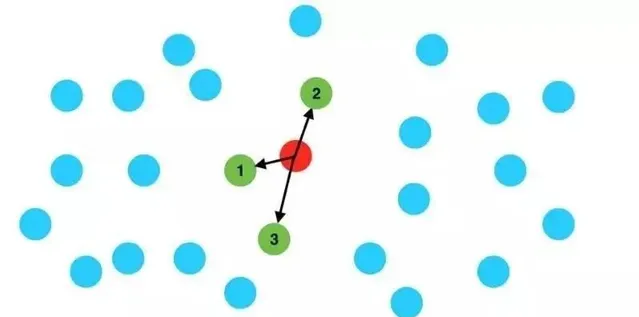
图2KNN查询示意图
以上过程通过实践分析后,发现存在两个缺陷:
1、一次过滤是纯空间过滤,得到的候选订单极有可能并不在目标时间内。比如,我们通过KNN查询得到了附近5000个订单,这些订单可能全部或大部分产生于7天前,这样会导致我们二次过滤后剩下的结果非常少。当然,针对这种情况,有两个改进方案。第一种,可以将一次过滤的K值放大,比如查询50000个附近的订单,这样二次过滤剩余的数据量很可能会增加,但是,这种方案仍然不能保证一定能查询到足够的数据。同时,增加K值还会造成性能的降低。第二种方案,先进行时间过滤,再进行KNN。我们的订单数据在7天内可能有上千万或者更多数据,时间过滤后的结果,在内存中进行KNN会有非常大的性能开销和效率问题。这种方案一级过滤的效果太差导致难以实现。
2、PostGIS作为关系型数据库水平扩展性天生比较有限,虽然有pgpool和pg-xl这种外部组件支持集群模式。但是,每天千万级数据量的写入,还是会让PostGIS有些力不从心。
2.2 基于分布式数据库和时空索引的查询方案
利用GeoMesa引擎,将订单数据导入之后,建立时空Z3索引,通过一步查询即可实现时空过滤。但是,此方案存在比较明显的缺陷,我们无法确定查询的空间范围。因为,GeoMesa的时空查询必须指定查询的空间与时间范围。时间范围可以预先设定比如最近7天,而空间范围因为第一节讲过每个区域的订单分布极不均匀,如果使用固定的空间范围,非常有可能出现两种情况,第一是某些区域查询到非常多的数据比如10w个订单,这会导致回传到客户端的数据量很大,增加客户端压力,最终导致整体性能的下降;另一种情况是某些区域因为订单量很少,导致无法获取足够的订单。因此,固定空间范围的方案是不可行的。
三、解决方案
我们的方案基于分布式时空引擎JUST [2] 来实现海量数据的存储,并在此基础上建立时空索引,与GeoMesa的Z3索引不同的是我们使用优化的Z2T索引 [3] 。另一方面,为了解决2.2节中无法固定空间范围的问题,本方案通过动态统计的手段,建立每天全国范围的查询区域索引,每次用户查询会根据区域索引获得合理的空间检索范围,保障最终查询结果数据的合理性。
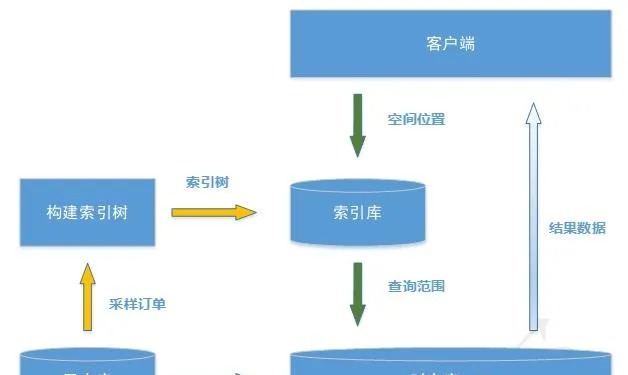
本方案分为两个流程,索引建立流程和数据检索流程。架构如图4所示。其中黄色箭头代表我们建立空间索引的数据流,绿色箭头为查询检索数据流。
3.2.3 索引建立流程
索引的建立流程可以看成是原始数据的预处理过程。一般情况下,订单数据是T+1模式,即每天凌晨导入前一天的所有订单数据,白天查询到的数据是昨天及昨天以前的数据。我们的索引建立就是在数据导入之后进行,整个过程如图5所示。下面详细介绍一下里面几个关键流程。
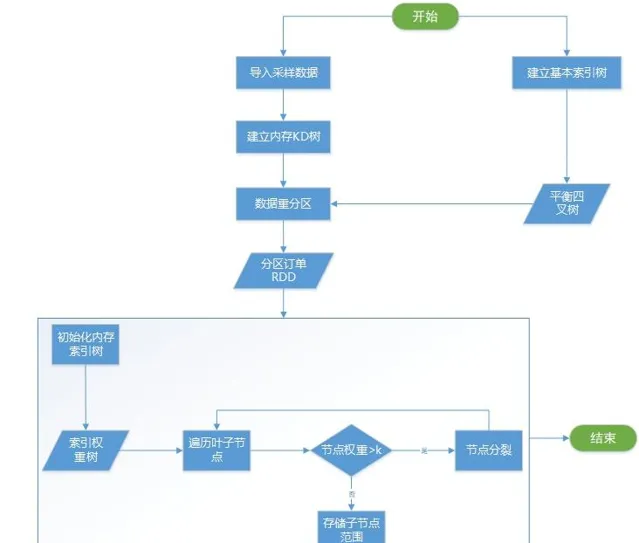
1、数据采样并建立KD树索引。
因为应用需求里时间范围固定为7天。因此,为了得到合理的索引树,我们需要根据前7天数据的分布进行构建。但是,7天的数据量可以达到数亿,全部放到内存计算会非常耗时。为了可以快速完成索引构建,同时避免过多损失精度。最终使用随机抽样1%作为输入数据。获取到所有抽样订单后,建立一棵内存KD树,用于后面索引建立。
2、建立基础索引树。
所谓基础索引树,是一棵平衡四叉树。它是我们内存范围索引的构建基础,他的最大最小级别可以配置,叶子节点的空间范围是索引构建的初始范围。假设初始级别为2,先把二级叶子节点全部建立好,并计算好每个叶子的空间范围。
3、构建缓存索引。
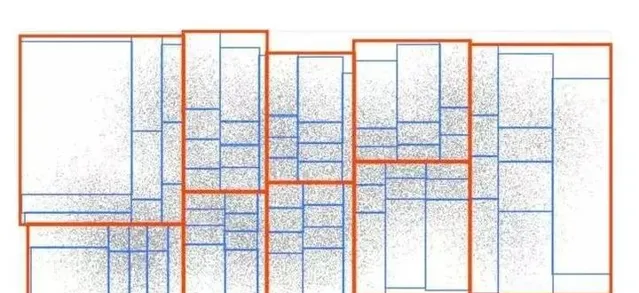
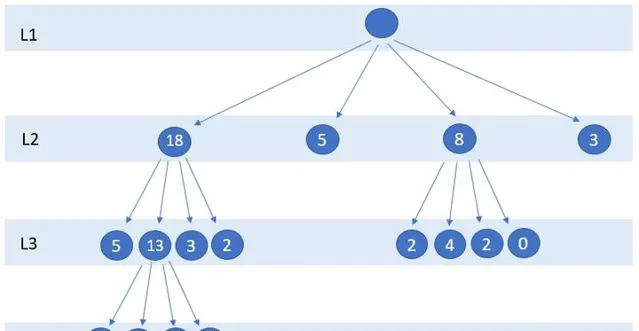
构建索引树分为两步;第一步,遍历所有基础索引树的叶子节点,将叶子空间范围作为查询范围搜索KD树获得范围内的订单个数orderNum,如果订单个数大于阈值k,则进行分裂,否则停止分裂。这一过程如图6所示,假设k为5,所有大于5的节点会继续分裂为4个子节点,直到不存在节点范围内订单数大于5为止。第二步,将索引树存储到Redis缓存中。
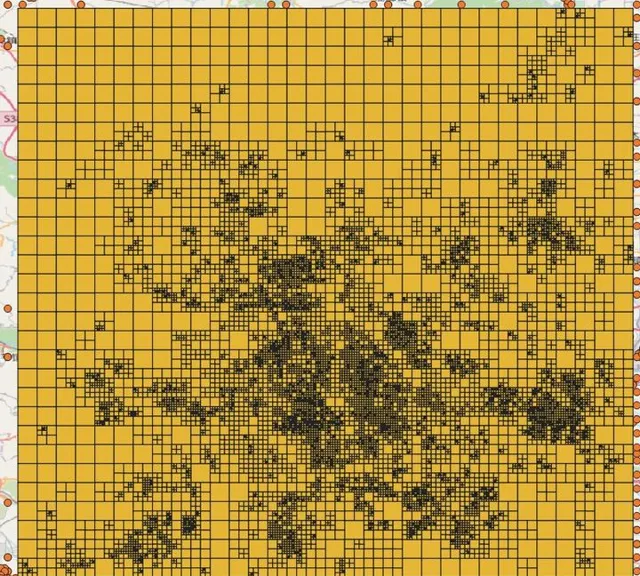
通过对某一天统计的北京地区索引树进行可视化分析如图7,并将索引树和订单采样数据进行分布叠加如图8,可以看到我们的索引树可以很好的模拟订单分布情况。

3.2.3 数据检索流程
数据检索流程相对简单,首先,从Redis内取出最新构建的索引树,利用输入的地理位置在构建好的索引树中获取到对应的叶子节点空间范围。然后,利用搜索范围去JUST内进行空间查询即可得到统计计算需要的订单数据。
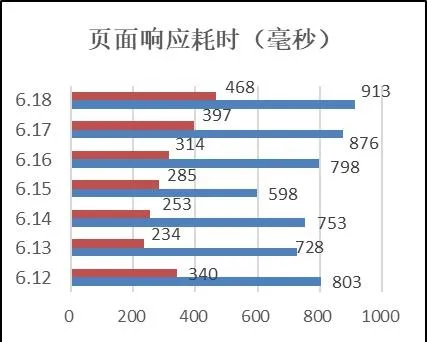
经过对一个星期的查询进行统计如图9,可以看到最长的查询响应也在1秒内。
四、总结
本文介绍了一种基于JUST时空数据引擎的时空筛选方案。适用于基于订单数据的时空邻近查询场景,既能保障查询的效率,同时可以返回合理数量的数据供服务端分析展示。除订单数据外,基于这种时空邻近查询方案,还可以扩展出非常丰富的应用场景,比如:最近n天在附近发生的重大事件查询,最近n小时,附近道路口车流量查询等。
参考
- ^ [1] http://www.cac.gov.cn/2020-04/27/c_1589535470378587.htm
- ^ [2] http://just.urban-computing.cn
- ^ Li R , He H , Wang R , et al. JUST: JD Urban Spatio-Temporal Data Engine[C]// 2020IEEE 36th International Conference on Data Engineering (ICDE). IEEE, 2020.











