上一篇博文详细介绍了AlphaGo的核心算法蒙特卡洛搜索树 ,但是还是没有说明AlphaGo的超强棋力是如何练成的。
我们还是从原文开始,第一代AlphaGo使用了两个独立的深度网络:策略网络Policy Net和价值网络Value Net,两个网络需要独立训练。第二代的AlphaGo Zero以及AlphaZero则使用了更加简化优雅的网络架构:统一了深度神经网络 部分,只是将网络输出修改为Policy和Value两个头。
对比AlphaGo Lee和AlphaGo Zero两个版本,只能用一句话来形容:「大道至简 」。
一、和AlphaGo Lee的区别
| 训练数据集 | 输入数据 | 网络结构 | MCTS搜索 | |
|---|---|---|---|---|
| AlphaGo Lee | KGS上的16万个高手棋谱(2940万手棋)+自我对弈 |
19x19x48个特征面
Feature planes(落子、提子、征子等) |
策略网络和价值网络独立 | 通过MCTS rollout来评估每一步价值 |
| AlphaGo Zero | 490万局自我对弈 | 19x19x17只使用黑方和白方的落子作为输入数据 | 统一的策略+价值网络 | 不需要rollout,只用策略网络的价值 |

二、网络架构
AlphaGo Zero的策略网络分为三个部分:输入层、多个残差网络 block、双头输出层()
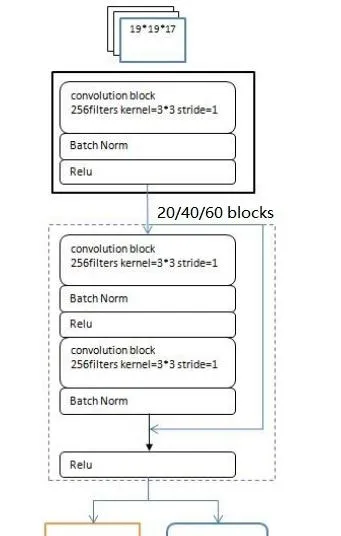
1、输入层
AlphaZero策略网络 的输入数据包含了黑白双方过去8手的落子,以及当前落子的颜色。数据格式为19x19x17: s_{t}=[X_{t}, Y_{t}, X_{t-1}, Y_{t-1}, ..., X_{t-7}, Y_{t-7}, C]
其中C是当前棋手X的落子颜色(黑色为1,白色为2), X_{t} 是当前棋手X的所有落子, Y_{t} 是对方棋手Y的所有落子。 X_{t-1} 是棋手X在上一手时的所有落子,以此类推。
2、卷积Blocks
为了学会非常复杂的围棋棋形,需要相当深度的神经网络,AlphaGo Zero设计了基于CNN和Residual残差网络的Residual blocks结构,每个block的组成为:
(1)卷积网络Conv2D( filters=256, kernel_size=(3,3), stride=1, padding=0);
(2)正则化层Batch normalisztion;
(3)relu非线性激活函数
(4)卷积网络Conv2D( filters=256, kernel_size=(3,3), stride=1, padding=0);
(5)正则化层Batch normalisztion;
(6)残差连接 (skip connection)
(7)relu
3、输出头
网络有两个输出头:
Policy Output:
(1)Conv2D(filters=2, kernel_size=(1,1), stride=1, padding=0);
(2)正则化层Batch normalisztion;
(3)relu
(4)全连接输出层 size=362,19*19 + 1,表示361种落子以及pass的概率
Value O











