#人员重识别##Transformer#
Self-Supervised Pre-Training for Transformer-Based Person Re-Identification
阿里
基于 Transformer 的监督预训练在人员重识别(ReID)方面取得了很好的性能。但由于 ImageNet 和 ReID 数据集之间的域差距,通常需要一个更大的预训练数据集(如ImageNet-21K)来提高性能,因为 Transformer 的数据拟合能力很强。
本次工作的目标是分别从数据和模型结构的角度缓解预训练和 ReID 数据集之间的差距。
首先研究用 Vision Transformer(ViT)在无标签的人物图像(LUPerson数据集)上进行预训练的自监督学习(SSL)方法,并根据经验发现它在 ReID 任务上明显超过了ImageNet的监督预训练模型。为进一步缩小域差距,加速预训练,提出灾难性遗忘分数(CFS)来评估预训练和微调数据之间的差距。基于 CFS,通过对接近 down-stream ReID 数据的相关数据进行抽样,并从预训练数据集中过滤不相关的数据,选择一个子集。对于模型结构,提出一个 ReID-specific 模块,IBN-based convolution stem (ICS),通过学习更多的不变特征来弥补域差距。
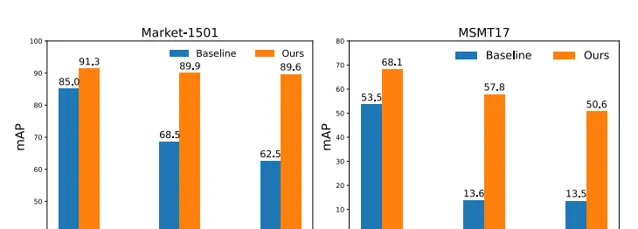
在监督学习、无监督域适应(UDA)和无监督学习(USL)的设置下,进行了大量的实验来微调预训练模型。并成功地将LUPerson数据集的规模缩小到50%,并且没有性能下降。最后,在Market-1501和MSMT17上实现了最先进的性能。例如,ViT-S/16在Market1501的有监督/UDA/USL ReID上实现了91.3%/89.9%/89.6%的mAP准确性。
将开源:https:// github.com/michuanhaoha o/TransReID-SSL
论文:https:// arxiv.org/abs/2111.1208 4
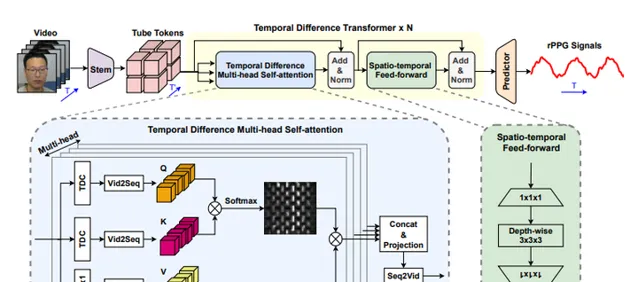
PhysFormer: Facial Video-based Physiological Measurement with Temporal Difference Transformer
芬兰奥卢大学&英国牛津大学&西安交通大学&西北大学(PRC)
PhysFormer,是一个基于端到端的视频 Transformer 的架构,以自适应地聚集局部和全局的时空特征来增强 rPPG 表示。作为 PhysFormer 的关键模块,时差transformers 首先通过时差引导全局注意力来增强准周期性的rPPG特征,然后针对干扰完善局部时空表示。此外,提出标签分布学习和受课程学习启发的频域动态约束,为 PhysFormer 提供详细的监督,并缓解过拟合现象。
在四个基准数据集上进行了综合实验,以证明它在数据集内部和跨数据集测试中的卓越表现。其中一个亮点是,与大多数需要从大规模数据集进行预训练的Transformer 网络不同,所提出的 PhysFormer 可以很容易地在 rPPG 数据集上从头开始训练,这使得它有希望成为rPPG社区的一个新型 Transformer 基线。
将开源:https:// github.com/ZitongYu/Phy sFormer
论文:https:// arxiv.org/abs/2111.1208 2
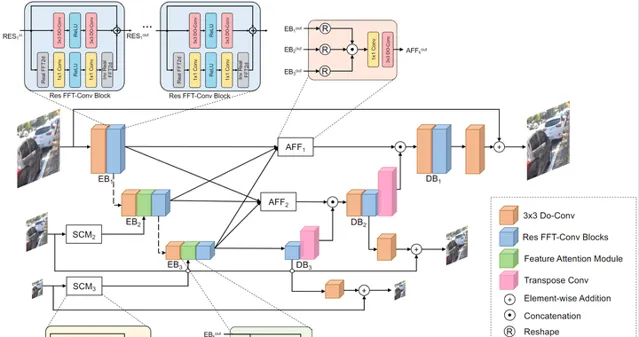
Deep Residual Fourier Transformation for Single Image Deblurring
华东师范大学&上海交通大学
文中提出 Residual Fast Fourier Transform with Convolution Block(Res FFT-Conv Block),能够捕捉到长期和短期的相互作用,同时整合低频和高频的残差信息。Res FFT-Conv 块在概念上很简单,但计算效率很高,而且是即插即用的块,可以在不同的架构中获得显著的性能提升。通过Res FFT-Conv块,进一步提出基于 MIMO-UNet 的深度残差傅里叶变换(DeepRFT)框架,在 GoPro、HIDE、RealBlur 和 DPDD 数据集上实现了最先进的图像去模糊化性能。
实验表明,DeepRFT可以显著提高图像去模糊性能(例如,与MIMO-UNet相比,GoPro数据集的PSNR提高了1.09dB),DeepRFT+在GoPro数据集的PSNR甚至达到33.23dB。
已开源: https:// github.com/INVOKERer/De epRFT
论文:https:// arxiv.org/abs/2111.1174 5
LMGP: Lifted Multicut Meets Geometry Projections for Multi-Camera Multi-Object Tracking
萨尔大学&汉诺威大学等
多机位多目标跟踪目前在计算机视觉领域备受关注,因为它在现实世界的应用中具有优越的性能,如在拥挤的场景或广阔的空间中进行视频监控。
本次工作提出一个多机位多目标跟踪方法,它是基于 spatial-temporal lifted 的 Multicut 公式。模型利用单镜头追踪器产生的最先进追踪器作为建议。由于这些追踪器可能包含 ID-Switch 错误,作者通过从3D几何投影中获得的新型预聚类来完善它们。因此,得出一个没有 ID-Switch 的更好的跟踪图,以及数据关联阶段更精确的 affinity 成本。
然后,通过解决一个global lifted 的 multicut 公式,将位于同一摄像机中的小追踪器的短距离和长距离的时间互动以及摄像机之间的互动纳入其中,将小追踪器与多摄像机轨迹进行匹配。
在WildTrack数据集上的实验结果接近完美,在Campus上的表现优于最先进的跟踪器,而在PETS-09数据集上则与之相当。
将开源:https:// github.com/nhmduy/LMGP
论文:https:// arxiv.org/abs/2111.1189 2
 LMGP
https://www.zhihu.com/video/1446791246233088000
LMGP
https://www.zhihu.com/video/1446791246233088000
#弱监督##云检测#
Weakly-Supervised Cloud Detection with Fixed-Point GANs
奥胡斯大学
现有的基于 CNN 的监督式云检测方法需要大量的带有像素级云标签的训练图像,导致标签成本大。因此,当像素级标签不可用时,应用现有的基于 CNN 的方法来检测越来越多的地球观测卫星中的云是非常昂贵的。
本次工作提出 FCD,一种弱监督的云检测方法,它只需要图像级别的标签,而这些标签的获取成本要低得多。FCD 应用一个固定点 GAN 来学习清晰图像和多云图像之间的图像转换,同时确保在转换过程中只有云会受到影响。通过将图像翻译成清晰的图像,从而去除任何云层,能够从原始图像和翻译后的图像之间的差异中检测到像素级别的云层。由于FCD是一个生成模型,还提出 FCD+ 来完善FCD 生成的云层掩码,通过消除生成的副作用来进一步改进。
在包含全球各种生物群落的卫星图像的大型 Landsat-8 生物群落数据集上,证明了所提出方法优于现有的基于规则的方法和基于类激活图的弱监督方法的云检测。
此外,FCD+在仅用1%的可用像素级标签进行微调后,达到了接近完全监督的性能。因此,所提出的方法能够大幅减少训练基于CNN的云检测器的标签工作,并使性能损失最小。
已开源 :https:// github.com/jnyborg/fcd
论文:https:// arxiv.org/abs/2111.1187 9

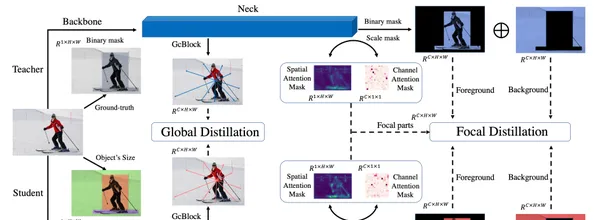
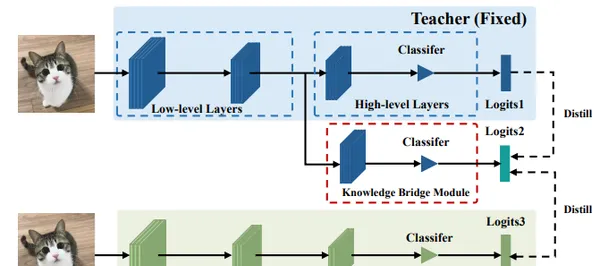
Focal and Global Knowledge Distillation for Detectors
清华大学深圳国际研究生院&字节跳动&北航
文中指出,学生检测器需要注意教师检测器的关键部分和全局关系。然后,提出Focal and Global Distillation(FGD)来指导学生检测器。
Focal 蒸馏法分离了前景和背景,迫使学生对教师的关键像素和通道进行关注。Global 蒸馏法重建不同像素之间的关系,并将其从教师转移到学生身上,弥补 Focal 蒸馏法中缺失的全局信息。所提出方法只需要计算特征图上的损失,因此 FGD 可以适用于各种检测器。
在具有不同骨干的各种检测器上进行了实验,结果表明,学生检测器取得了出色的 mAP 改进。例如,基于 ResNet-50 的 RetinaNet、Faster RCNN、RepPoints和 Mask RCNN 用所提出蒸馏方法在 COCO2017 上实现了 40.7%、42.0%、42.0%和 42.1% 的 mAP,分别比基线高 3.3、3.6、3.4 和 2.9。
已开源 :https:// github.com/yzd-v/FGD
论文:https://
arxiv.org/abs/2111.1183
7
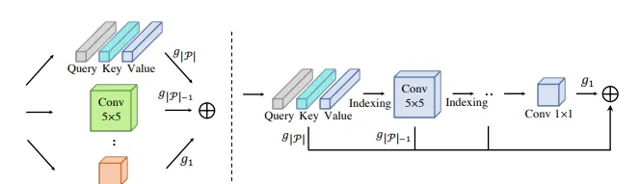
Pruning Self-attentions into Convolutional Layers in Single Path
蒙纳士大学&悉尼大学&京东探索研究院
对于 Vision Transformers(ViTs)在计算机视觉任务中应用中,MSA 层对全局相关性进行建模会导致两个被广泛认知的问题:大量的计算资源消耗和缺乏对局部视觉模式进行建模的内在归纳偏见。
本次工作,作者在 MSA 和卷积运算之间引入一种新的分权方案,它允许用 MSA 参数的子集对卷积运算进行编码,并同时优化这两类运算。基于权重共享方案,提出SPViT,以减少 ViT 的计算成本,以及以低搜索成本自动引入适当的归纳偏置。
在两个有代表性的ViT模型上进行了广泛的实验,表明所提出方法取得了有利的准确性-效率权衡。
将开源:https:// github.com/zhuang-group /SPViT
论文:https:// arxiv.org/abs/2111.1180 2
#知识蒸馏##BMVC2021#
Semi-Online Knowledge Distillation
华南理工大学&哈尔滨工业大学
本文研究了教师模型在 KD 中支持更多可信的监督信号,而学生在 DML 中捕捉到更多来自教师的类似行为。
基于这些观察,作者首先提出在一个统一的框架中结合 KD 和 DML 。此外,提出一种半在线只是蒸馏(SOKD)方法,可有效地提高学生和教师的表现。在这个方法中,在 DML 中引入同伴教学的训练方式,以缓解学生的模仿困难,同时也利用了 KD 中训练有素的教师所提供的监督信号。此外,还表明该框架可以很容易地扩展到基于特征的提炼方法。
在 CIFAR-100 和 ImageNe t数据集上进行的大量实验表明,所提出的方法达到了最先进的性能。
已开源: https:// github.com/swlzq/Semi-O nline-KD
论文:https:// arxiv.org/abs/2111.1174 7
Modeling Temporal Concept Receptive Field Dynamically for Untrimmed Video Analysis
国科大&中科院&金山云&哈尔滨工业大学&鹏城实验室
本文探讨了基于概念的事件识别方法的时间接受域,以有效地进行未修剪的视频事件分析。
首先,引入时间动态卷积(TDC),赋予基于概念的事件识别网络更强的灵活性,它可以根据不同的输入自适应地调整其感受野的大小。在TDC的基础上,提出时间动态概念建模网络(TDCMN),以学习准确和完整的概念表示,用于高效的未修剪视频分析。TDCMN 采用 TDC 来分析同一类型内和不同类型之间的概念的时间特征。
为了证明该模型的有效性,将TDCMN应用于两个具有挑战性的视频数据集FCVID和ActivityNet。与其他基于概念的事件识别方法相比,TDCMN可以在很大程度上提高事件识别性能。
已开源: https:// github.com/qzhb/TDCMN
论文:https:// arxiv.org/abs/2111.1165 3

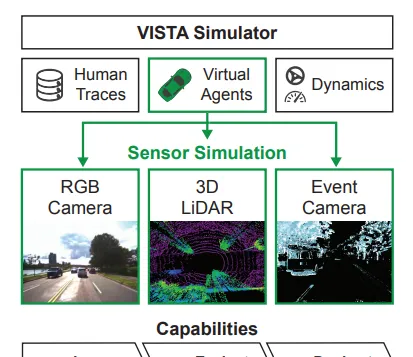
VISTA 2.0: An Open, Data-driven Simulator for Multimodal Sensing and Policy Learning for Autonomous Vehicles
麻省理工学院&University of Toronto and Toyota Research Institute
VISTA,是一个开源的模拟器,支持多模态传感器的合成,包括二维RGB相机、三维LiDAR和基于事件的移动代理相机。该模拟器是数据驱动的,能够合成足以用于policy learning (政策学习)和评估的高保真传感器测量。
并通过在一个完整的自主车辆上为每个传感器直接部署在VISTA中学习的政策来展示模拟到现实的能力,以及展示了模拟和现实世界测试中闭环评估的一致结果。
作者称 VISTA 的发布和可扩展性为社区感知和控制自主车辆开辟了新的研究机会。
将开源:https:// vista.csail.mit.edu/
论文:https:// arxiv.org/abs/2111.1208 3

![[Galtier 2016] 10.6 吸积盘中的磁旋转不稳定性](http://img.jasve.com/2024-12/fa3e1dbd893c9ac61c1995a8153d789e.webp)









