这个问题得分应用环境考虑。
先来讲讲AVX512是个什么东西:
近年来,Intel的tick-tock战略已然失效,桌面消费级CPU从酷睿6000系的skylake到今年的10000系,实际上没有变化过架构,主要是有两个原因,第一个原因是Intel 10nm工艺的产能与频率一直无法满足要求,第二个原因是,主流架构的IPC改进确实已经进入了一个瓶颈。这个时候Intel需要一个能够让每代CPU有大的性能提升的亮点,AVX这一脉的SIMD指令集就是在这个背景下出现的。
简单点理解的话,SIMD实际上的用途就是在不改变主要设计的同时,能够让CPU在运行能够针对性优化的程序时,拥有极大程度的IPC提升,这个程度在优化真的非常极限的情况下,可能是接近2倍、接近4倍的巨幅提升。
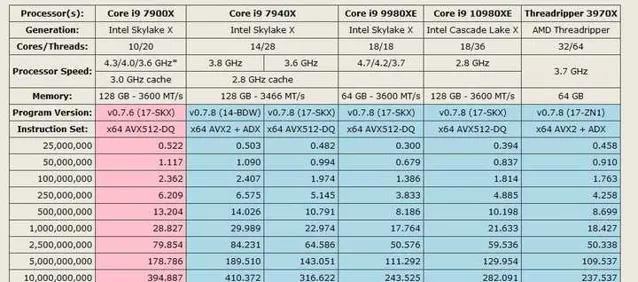
这个提升是怎么实现的?SIMD的含义是单指令多数据,实现方式就是一组数据能够填满SIMD的位宽,而AVX512的位宽是恐怖的512bit,这就等于说要填满需要一组内16个32bit的单精度浮点数据或8个64bit的双精度浮点数据才能填满,而这个时候,一般的民用应用根本没有这么大的浮点数据运算需求量,双精度的应用场景都极为有限,何谈完整利用AVX512?
而AVX512有另一个缺点在于,功耗过高,初代基于14nm的SKLX在使用AVX512时,甚至需要降频到2.8GHz甚至更低来保证功耗维持在可控范围内。这是由于位宽的翻倍提升需要更多的晶体管,而且大量密集集中在芯片的一小块区域,极小面积的大量发热会导致散热压力明显增大。
当然,AVX512也确实已经在不少领域有了相应的建树:在大量使用高精度浮点数的密集运算中,内存才是运算的瓶颈,这个时候AVX512的效率确实比GPU会高不少。而VNNI也在AI领域有了相应的成果。
在和GPU竞争里,CPU的对比除了内存延迟方面,还有人才方面。能写AVX加速代码的人才和精通CUDA的人才……人才成本的优劣大家自己判断吧。
就题目而言,一般的平民用户是不用操心AVX512的,目前桌面民用级大家清一色已经都是满血AVX2到头,Intel想在ice lake上普及半吞吐AVX512,想知道效果如何还是需要应用基础的。这里吐槽一句,要是ICC能大规模普及的话,想必AVX这方面的优化覆盖率会提升一个数量级吧……
总之,这个指令集还是和大多数人没有交集的,想买AMD的平民用户完全不用担心这方面的问题。










