泻药。强化学习(RL)在游戏领域上已经取得了巨大成功,比如下围棋;但是目前在现实问题上的应用还有很多困难。俞老师有一个很有名的回答:强化学习领域目前遇到的瓶颈是什么?

据我的观察,现实任务相较于游戏,最大的挑战就是stochasticity(随机性)。这篇文章我就用我们最近的工作作为例子来讲一下用RL解决现实问题的一些经验,包括怎么去建模现实问题、什么是随机性、解决的算法应该有怎样的性质、base model怎么选等等。
这里有一个选择:RL可以用来做pre-training和post-training,但是post-training更亲民一点,作为科研乞丐我也只能玩的起微型的post-training,比如这份工作从头到尾用的GPU甚至没超过13G,一张T4就够了。但是模型小并不代表性能差,关键还是怎么去建模这个问题然后选择合适的算法。例如我们把这个小模型的性能从18%(跟GPT-4水平差不多)直接飙到了82%,翻了好几倍。现在LLM无脑堆数据和模型,我感觉还是有不少别的东西可以做的。如果大家关心工作的内容,也可以先看看我们的website,有很多demo和可以玩的东西:https://digirl-agent.github.io。
现实环境中的RL困境
Stochasticity
RL目前打游戏很强,而游戏往往是符合某种可预测的规则的。比如下围棋,规则是放在那里的,你下5行4列的黑子,这个黑子就会出现在5行4列;玩atari也是,你按一下往右的按键,人物就一定会往右一格。但是real-world的task不一定,会有 几乎无限 的扰动,比如如果你要买一个东西,输入物品名字后淘宝每次会给你推不同的东西。现在很多的RL工作做机械臂的一些模拟,都是在同一个工作台上做实验,如果换一个桌面环境,就秒挂了。但是现实任务下,几乎没有办法避免环境中出现随机性,因此应该去 显式地建模这种随机性 (将解决随机性作为任务的一部分)。为了体现随机性,我们选了一个用手机完成查资料、购物这些现实任务的方向(之前没有人在这个上面做过RL),这个任务的所有环境都是在手机模拟器里面运行的,所以用户自己玩会出现的各种随机性,环境都会建模进去。一些比较典型的随机性有这些:

比如网页过一段时间主页会变,这个会导致每次点击网页同一个地方都可能看到不同的结果,比如前两张图,有时候网页上面的广告只有两行,有时候有三行,这样会导致整个网页的布局变化;再比如后面有几张图,有时候网页会有弹窗或者广告,必须先解决掉才能继续;又比如商品每次搜索的顺序都可能不同,是根据服务器的推荐算法排序的。这些随机性会导致直接behavior cloning比较困难,直接用monte carlo去做RL也很困难,因为之前monte carlo用的data很可能没法generalize到stochastic的情况上。
Scale
要解决stochasticity,一般来说需要 巨大的数据量 。可以这么理解:每一个可能存在stochasticity的自由度都需要一批cover到尽可能多情况的数据进行拟合。比如上面提到的google弹窗,理想情况下我们应该尽可能多地收集在google页面可能弹出的弹窗,以及成功的trajectory是怎么解决这些弹窗的。当类似这样的stochasticity的量多起来时,所需要的数据也是成倍增长的。要解决这个问题,如果用offline RL,显然需要大量数据;如果是online RL,那每次training间隔时收集的数据也是越多越好:因为如果有偏地建立对stochasticity的表示,一定会降低collected trajectory的质量。
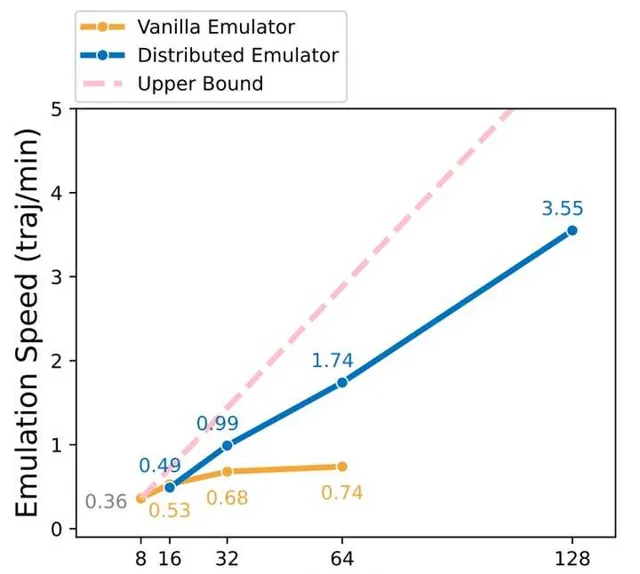
例如我们的工作中,为了解决这个问题,就专门写了一个多机distributed parallel的脚本,支持多机大规模收集trajectory。例如一台机子能开8个安卓模拟器的话,可以轻松scale到四机甚至十六机,收集速度是线性增长的,而且不需要任何GPU。我们对比了只在一个更多CPU的机子上开更多的模拟器的方案,这个单机方案的速度是logarithm增长的,比我们的方法慢很多,在repo里面有详细的分析:digirl/multimachine/README.md。工作早期四天的训练,有了多机支持,后面只需要两天甚至一天就搞定了。
Reward: Step-level or Trajectory-level?
之前在Jiayi的工作里面大家尝试了用step-level reward去解这个问题,但是发现evaluator很难正确地给出reward。比如如果我们要查询淘宝上某一个商品的价格,那么从淘宝跳到百度应该是一个负的reward;但是百度搜索也是可以找到淘宝的商品的,只要给一个「淘宝」的关键字就可以了(有时候甚至不需要关键字搜出来的也都是淘宝的结果)。这使得这个reward具体的数值很难确定(有时候甚至正负也不好确定)。因此我们认为应该将reward做成trajectory-level的,因为 判断「一个任务是否成功」比「这一步是否更靠近结果」简单很多 ,现在的LLM例如Gemini都可以完美解决了;而对于step-level上是否离目标更近,LLM还不太行,所以应该转而交由一个专用算法解决,例如训练一个很靠谱的critic。
小模型能否逆袭?
「小」不一定「差」
大家会好奇我们用的是什么模型,好像想要解这个问题,需要一个很fancy的模型架构。其实我们用的模型非常小而且朴实,参数加起来才 1.5B,一张T4就能跑 ,无lora的training才用了13G的vram。模型的架构是一个freeze的CLIP配一个要tune的T5,之前一个大哥pre-train的,模型名字叫做AutoUI。模型的输入是一张当前和上一个state的手机的屏幕截图 + 上一步的action + 最终的goal。模型会输出接下来要做什么,例如文字或者坐标。 注意输出的是坐标,比如[528, 129],屏幕上是没有任何提示的。 之前的工作,例如GPT,都是屏幕上有很多tag,让GPT去选一个出来,比如GPT的屏幕被弄成了这样来让他好做一点:
我们的是没有这些tag的,直接输出一个text形式的坐标。这个难度要大得多,也更realistic一点,但是我们一个1.5B的模型直接把GPT干趴了,领先三倍多(详见后面的结果部分)。大模型固然好,但也不是人人都玩得起的,这个结果充分说明了一个专精的模型不需要很大。当然,如果要scale到general tasks,可以想像1.5B的容量还是有点小了。
选择base模型的一些通用建议
这里我有一些选base模型的建议,首当其冲的就是 base模型的性能不能太差 。如果policy initialization太差,那么采集到的trajectory大概率是错的,这个时候RL必死无疑,不管你用什么算法都救不回来,没有data拿什么学。那怎么获得一个还可以的policy initialization?往往需要先从human/很厉害的模型(比如GPT-4)那边用监督学习学到一点知识,然后再上RL。比如我们的工作中,大概的流程是这样的:
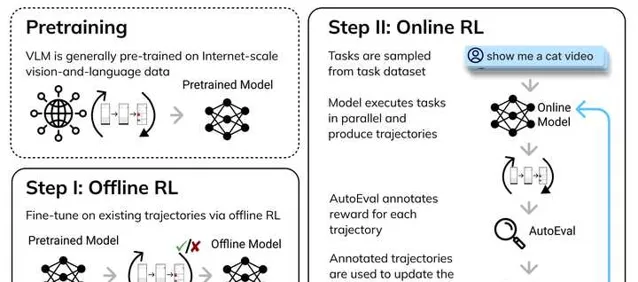
务必先拿一个稍微靠谱的pre-trained模型 (性能有10%以上),然后RL。如果性能太差(比如只有1%),还是早点换一个base model比较好,不然不知道要学到什么时候。有同学会问为什么自己上课时作业里遇到的RL可以用random initialization:这是因为游戏的action space很小,盲猜也能对的。在real-world problem上一抓几千个potential action,给random policy直接干玉玉了。
第二个是 base模型的大小不能太大 。一个原因是模型大,就需要更多的data去fit,简称训不动。特别是online RL,所有data都是边训边收集的,如果model需要成倍的数据,那么collect也会需要成倍的数据,这需要很多机器一起跑collection。如果想偷懒少收集一点,那得调learning rate,可能更痛苦。试想你跑一轮实验需要一个星期,还要不要毕业了。另一个原因是穷。这个就不太需要解释了。作为一名合格的科研乞丐,我深刻认识到穷是不需要任何解释的。
算法
这一部分会稍微烧脑一点,可能需要反复读几次。我会把用到的知识都做成link放在旁边。
Filtered AWR
环境的基础搭好以后,就可以着手思考什么样的算法适合这个问题了。一个能想到的最简单的解法就是filtered behavior cloning(filtered BC),就是让模型自己玩,玩对了就拿对的整条trajectory让模型去学习自己是怎么做对的,玩错了就扔掉这个数据。train的方法也很简单,直接用language modeling的老方法去训练即可。但是filtered BC有两个问题:第一是只要trajectory成功了,那么其中的每一步,不管好坏,都会被模仿到;第二是没法高效地建模stochasticity,因为没有critic去专门fit这种随机性。
因此我们想到了, 可以不使用最终的reward,转而使用advantage去filter data 。这种算法会产出一个模型,这个模型在infer时的架构与原来完全相同,不需要为了RL往模型里面加新的module;而在train时,我们可以加入critic来估计这个advantage,从而用这个advantage来filter data;然后用这个filtered data来用和BC一样的loss训练模型。这是一个非常简单的想法,灵感来源于AWR(没听说过的同学可以略看这篇:AWR(Advantage-Weighted Regression)算法详解与实现),但是我们把AWR硬化成了hard filtering。
GAE的通俗理解
现在我们就要思考如何去设计这个advantage了。前面提到了stochasticity的问题,其实有关随机性,RL的前人已经有过非常多的讨论,其中John Schulman的GAE(Generalized Advantage Estimation)很大程度上缓解了随机性的问题。对GAE还不了解的同学强推这篇:张海抱:【强化学习技术 28】GAE。其实GAE本质上就是下面这一串advantage estimate的加权平均:
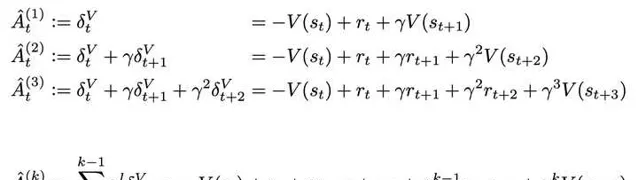
其中, \hat{A}^{(k)}_t 称为 k -step advantage。 当 k=1 时,就是1-step TD;如果我们把 k 拉到无穷大,那其实就是 t 时刻的monte carlo estimate \sum_{l=0}^{\infty}\gamma^lr_{t+l} 减掉baseline V(s_t) 。 这体现了GAE 「generalized」的原因:将advantage考虑成TD和MC的某种融合。因为MC是低bias的,TD是低variance的,所以可以根据实际情况调这个比重。
GAE被当成各种baseline(包括PPO也用GAE)是有原因的 - 在实验中,我们发现GAE用来做real-world task效果比单纯的TD/MC的estimate要好不少,因为TD很大程度上看value的准确度,而因为现实任务下的训练数据非常noisy,这个value critic是极难学的。这个时候就需要MC过来帮忙。但是单纯的MC又是不行的,因为现实任务有随机性,之前拿到的data没法generalize到随机出现的情况。
GAE的简化
我们的state-level advantage就是受到GAE的启发, 只取了GAE的第一项和无穷项 。对于每一个state action pair,我们取它的MC return advantage \sum_{t=h}^H r(t) = r(s_H,a_H, c) (这个是因为我们是trajectory-level reward,只有最后一步reward可能为1)和one-step TD advantage V(s_{t+1}, c)+r(s_h,a_h,c)-V(s_h,c) ,两者weighted sum可得
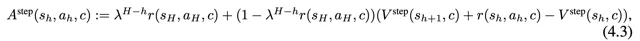
我们发现这个简化版的GAE能够比较robust地估计每个step的advantage。从行为的角度看,MC使得如果trajectory是成功的,那么其中的每一个step都会有比较大的advantage(在实践中我们发现,这样导致不成功的trajectory基本没有机会,这是件好事);TD使得critic认为value gain比较大的transition会获得更大的advantage,从而相对更不会被filter掉。下面是一个例子:
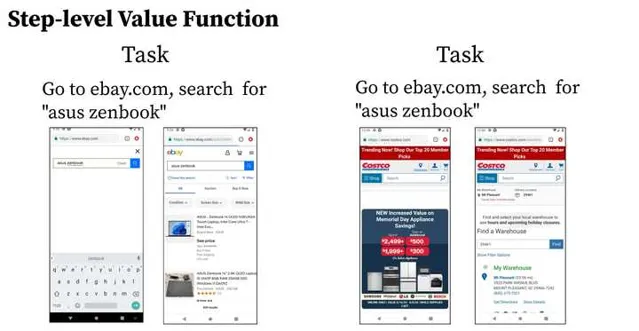
左图中要买一个笔记本电脑,agent从搜索框跳到商品展示页面,我们发现算法给了一个正的transition difference;右图中也是买一个笔记本电脑,但是agent点错了,从costco的主页跳到了地址栏,这个时候我们发现算法给了一个负的transition difference。这些都是比较符合我们设计的结果。由于这些filter都是step-level的,我们将这里的critic称为state-level value critic。
Automatic Curriculum
在实践中,我们发现了另外一个问题:由于我们训练时用的task是从task set里randomly sample出来的,所以 当一个task已经被完全掌握了以后,重新sample到不会带来很大的提升 ,也就是说正信息量比较小。因此我们的filter同时需要过滤掉那些经常成功的trajectory。但是,如果一个task没做对,它带来的信息量大概率是负的。要同时考虑这两种情况,就可以设计一个简单的instruct-level advantage:
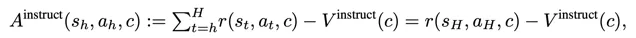
其中这个instruct-level value critic直接去 回归task的成功率 即可。这个算法的一个妙处在于,一个简单的task会在早期被解决,这个时候它应该被学到;一个稍微难一点的task在早期没法被解决,但是由于早期的任务解决后,模型通过automatic curriculum有更多资源去学习更难的task,从而加速中期task的解决,但这个时候依然无法解决最难的task;等中期的也被解决的差不多后,训练资源又会向最难的方向倾斜。一个训练到中期的automatic curriculum的功能大致如下:

如图,在中期阶段,最简单的task已经学会了,因此这个instruction(也就是task)的value会比较大,导致instruction-level advantage小;较难的task在这个阶段做对了以后会有更小的instruction value,因此反而可能不被filter掉。在实操中有一个细节,如果是offline-to-online的学习,那么offline阶段不要用instruction-level critic,因为模型一开始还没有学会最简单的task,而pre-collected data里面有很多成功的简单的task,这会导致filtered buffer损失大批简单task的trajectory,模型被critic坑了,完全学不到。在fully online的学习下这倒不是个问题,因为critic的学习和模型一样,也是渐进的,一开始大家的value都小,那成功了也就都会进buffer。
其实Automatic Curriculum是从更大的尺度上在解决stochasticity的问题,因为解决stochasticity需要scale,而大家的计算资源都是有限的。如果一个简单的task已经被解决了,那么它一定在可观察的范围内已经解决了stochasticity的问题,那么更多的计算资源应该被分配到更难的task上,因为更难的task往往难在更强的stochasticity。
组装
接下来,将instruction-level advantage和step-level advantage分别依次用来做filtering,剩下来的高质量数据就能直接用MLE loss训练模型了。所有的代码都开源到github了,欢迎来看源码。

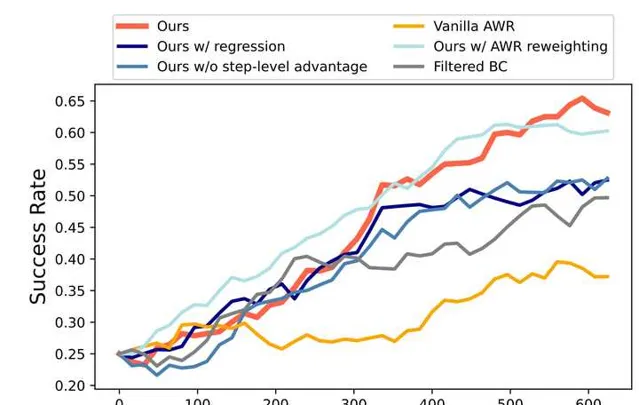
我们把算法和很多baseline比了一下,发现了很consistent的提升,最后的算法是最有效的:
结果
我们的结果不仅远超GPT-4V/Gemini这种off-the-shelf agent,而且比在相同数据集(但是他们是用的pre-collected数据,我们是interactive去收集的)上训过的CogAgent也强一倍多。filtered BC在这里也是我们的baseline,因为我们想要看看这种critic-based filter RL的方法究竟带来了多少好处,结果也是普遍高了10分左右。
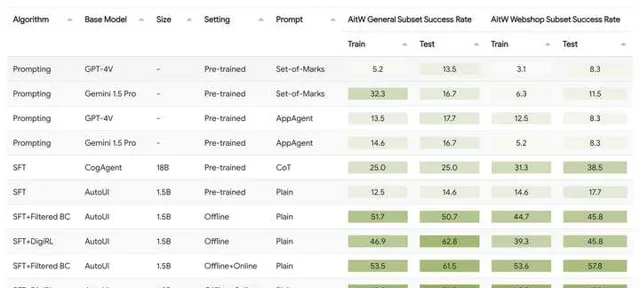
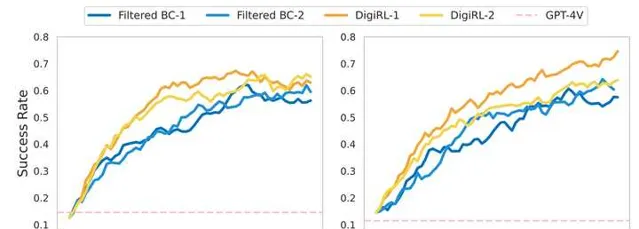
Online learning curve大概分别长这样(我们目前测了aitw这个task集的两个subset,左边一个右边一个):
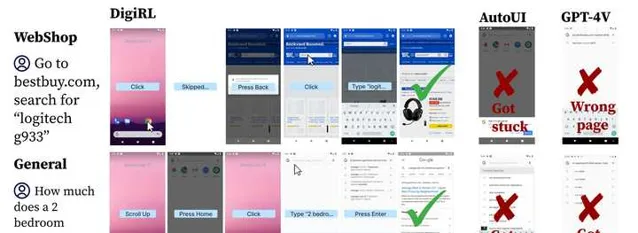
一些qualitative的结果:
资源
非常欢迎大家入坑!我们提供了全套环境、模型、算法代码,并且公开了模型checkpoint和pre-collected data,可以快速启动。 一张T4就够,这不抓紧star起来 ;p
GitHub: https:// github.com/DigiRL-agent /digirl









