感謝前輩,光榮屬於前輩。
1行程概念
行程定義
行程是並行環境下,一個具有獨立功能的程式在某個數據集上的一次執行活動,它是作業系統進行資源分配和保護的基本單位,也是執行的單位。
PCB
行程控制表(Process Control Block,PCB)是為了描述和控制行程的執行而定義的一種數表結構,它是行程存在的唯一標誌,也是行程實體的一部份。作業系統對行程的管理和控制主要以PCB為依據。PCB中包括了作業系統所需要的行程執行的所有資訊。
行程的上下文
使用者級上下文: 正文、數據、使用者堆疊以及共享儲存區;寄存器上下文: 通用寄存器、程式寄存器(IP)、處理器狀態寄存器(EFLAGS)、棧指標(ESP);系統級上下文: 行程控制表task_struct、記憶體管理資訊(mm_struct、vm_area_struct、pgd、pte)、內核棧。
2執行緒概念
執行緒上下文
多執行緒環境下的行程定義,很顯然,行程是系統進行資源分配和保護的基本單位。行程包括容納行程映像的一個虛擬地址空間,以及對CPU、I/O資源、檔以及其他資源的有保護有控制的存取。
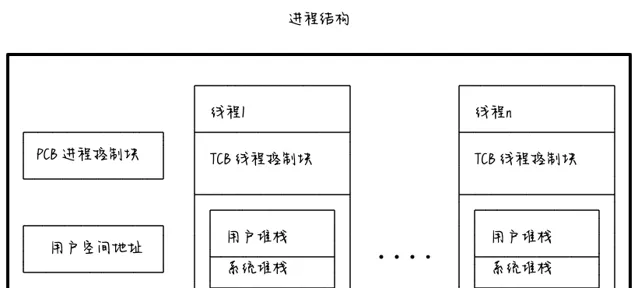
可見,一個行程可以劃分為兩個部份:一部份是資源部份,一部份是執行緒部份。
TCB
執行緒由執行緒控制塊(Thread Control Block,TCB)、使用者堆疊、系統堆疊以及一組處理器狀態寄存器和一個私用記憶體儲存區組成。
3上下文
cpu上下文
CPU 寄存器,是 CPU 內建的容量小、但速度極快的記憶體。而程式計數器,則是用來儲存 CPU 正在執行的指令位置、或者即將執行的下一條指令位置。它們都是 CPU 在執行任何任務前,必須的依賴環境,因此也被叫做 CPU 上下文。
行程上下文切換
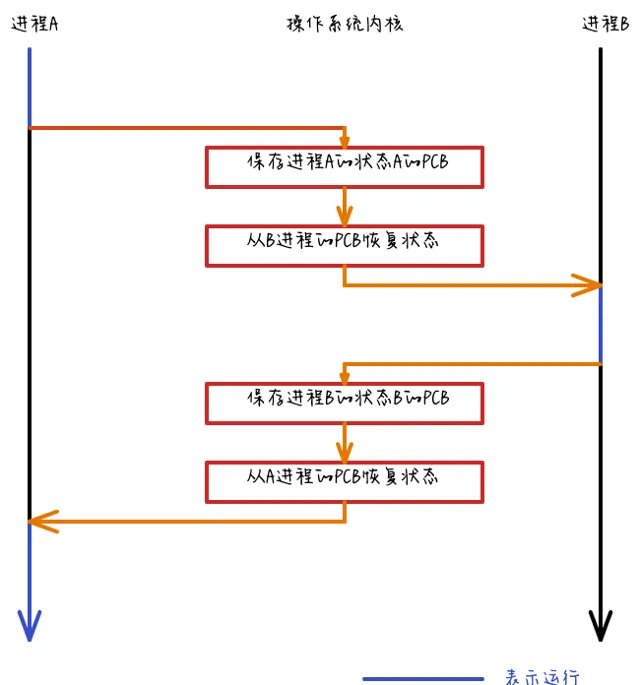
每當內核壓入一個新的系統上下文層時,它就要保存一個行程的上下文。特別是當系統收到一個中斷,或一個行程執行系統呼叫,或當內核做上下文切換時,就要對行程的上下文進行保存。上下文切換情況:
了解這幾個場景是非常有必要的,因為一旦出現上下文切換的效能問題,它們就是幕後兇手。
執行緒上下文切換
雖然同為上下文切換,但同行程內的執行緒切換,要比多行程間的切換消耗更少的資源,而這,也正是多執行緒代替多行程的一個優勢。
系統呼叫
系統呼叫 (system call),指執行在使用者空間的程式向作業系統內核請求需要更高許可權執行的服務。系統呼叫提供使用者程式與作業系統之間的介面。大多數系統互動式操作需求在內核態執行。
典型實作(Linux)
Linux 在x86上的系統呼叫透過 int 80h 實作,用系統呼叫號來區分入口函數。作業系統實作系統呼叫的基本過程是:
-
應用程式呼叫庫函數(API);
-
API 將系統呼叫號存入 EAX,然後透過中斷呼叫使系統進入內核態;
-
內核中的中斷處理常式根據系統呼叫號,呼叫對應的內核函數(系統呼叫);
-
系統呼叫完成相應功能,將返回值存入 EAX,返回到中斷處理常式;
-
中斷處理常式返回到 API 中;
-
API 將 EAX 返回給應用程式。
CPU 寄存器裏原來使用者態的指令位置,需要先保存起來。接著,為了執行內核態程式碼,CPU 寄存器需要更新為內核態指令的新位置。最後才是跳轉到內核態執行內核任務。而系統呼叫結束後,CPU 寄存器需要恢復原來保存的使用者態,然後再切換到使用者空間,繼續執行行程。
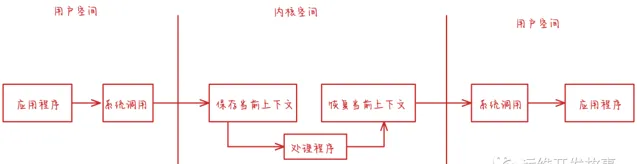
總結:一次系統呼叫的過程,其實是發生了兩次 CPU 上下文切換。但是主要是CPU寄存器,不會涉及到虛擬記憶體等資源。
中斷上下文切換
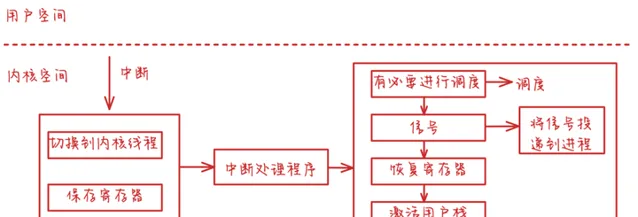
無論是硬件中斷(如來自時鐘和外設)、可編程中斷(programmed interrupt)(執行引起「軟件中斷」(software interrupt)的指令),還是例外中斷(如頁面錯),都由系統負責處理。
當發生一個中斷時,如果CPU正在比該中斷級低的處理機執行級上執行,它就在解碼下條指令之前,接收該中斷,並提高處理機執行級。這樣,在它處理當前的中斷時,就不會響應該級別或更低階別的中斷,從而維護了內核數據結構的完整性。內核處理中斷的操作順序如下。
4分析linux系統的cpu上下文切換
工具
vmstat
vmstat 是一個常用的系統效能分析工具,主要用來分析系統的記憶體使用情況,也常用來分析 CPU 上下文切換和中斷的次數。
$ vmstat 5
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 27458868 145996 4781912 0 0 0 1 0 0 0 0 99 0 0
0 0 0 27459388 145996 4781928 0 0 0 3 8937 15791 1 1 99 0 0
0 0 0 27457272 145996 4781948 0 0 0 10 9022 15774 1 1 99 0 0
你可以透過man手冊解讀每列的含義。現在我們重點強調:
vmstat 只給出了系統總體的上下文切換情況,要想檢視每個行程的詳細情況,就需要使用我們前面提到過的 pidstat 了。給它加上 -w 選項,你就可以檢視每個行程上下文切換的情況了。
# 每隔5秒輸出1組數據
$ pidstat -wu -t 5
Linux 4.4.0-142-generic (i-0nxoa13q) 07/22/2021 _x86_64_ (16 CPU)
03:54:53 PM UID TGID TID %usr %system %guest %CPU CPU Command
03:54:58 PM 0 3 - 0.00 0.20 0.00 0.20 0 ksoftirqd/0
03:54:58 PM 0 - 3 0.00 0.20 0.00 0.20 0 |__ksoftirqd/0
03:54:58 PM 0 7 - 0.00 0.20 0.00 0.20 12 rcu_sched
03:54:58 PM 0 6849 - 0.80 0.00 0.00 0.80 10 dockerd
...
03:54:53 PM UID TGID TID cswch/s nvcswch/s Command
03:54:58 PM 0 3 - 64.21 0.00 ksoftirqd/0
03:54:58 PM 0 - 3 64.21 0.00 |__ksoftirqd/0
03:54:58 PM 0 7 - 98.01 0.00 rcu_sched
03:54:58 PM 0 - 7 98.01 0.00 |__rcu_sched
...
這個結果中有兩列內容是我們的重點關註物件。一個是 cswch ,表示每秒自願上下文切換(voluntary context switches)的次數,另一個則是 nvcswch ,表示每秒非自願上下文切換(non voluntary context switches)的次數。這兩個概念你一定要牢牢記住,因為它們意味著不同的效能問題:
proc 檔案系統
Linux 內核提供了一種透過 /proc 檔案系統,在執行時存取內核內部數據結構、改變內核設定的機制。proc檔案系統是一個偽檔案系統,它只存在記憶體當中,而不占用外存空間。它以檔案系統的方式為存取系統內核數據的操作提供介面。深入了解可以去看這篇文章:https:// tldp.org/LDP/Linux-File system-Hierarchy/html/proc.html 中斷次數變多了,說明 CPU 被中斷處理常式占用,還需要透過檢視 /proc/interrupts 檔來分析具體的中斷類別。
sysbench壓力測試
sysbench是一個開源的、模組化的、跨平台的多執行緒效能測試工具,可以用來進行CPU、記憶體、磁盤I/O、執行緒、數據庫的效能測試。Sysbench的測試主要包括以下幾個方面:
下面的案例基於 Ubuntu 18.04,當然,其他的 Linux 系統同樣適用。我使用的案例環境如下所示:
# 以10個執行緒執行5分鐘的基準測試,模擬多執行緒切換的問題
sysbench --threads=10 --max-time=300 threads run
top命令:
top - 11:10:05 up 10 days, 35 min, 3 users, load average: 2.72, 1.27, 0.64
Tasks: 120 total, 1 running, 119 sleeping, 0 stopped, 0 zombie
%Cpu0 : 22.3 us, 69.4 sy, 0.0 ni, 8.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 23.2 us, 66.3 sy, 0.0 ni, 10.4 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu2 : 22.3 us, 67.1 sy, 0.0 ni, 10.6 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu3 : 22.8 us, 68.8 sy, 0.0 ni, 8.4 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 8008272 total, 2646040 free, 3650548 used, 1711684 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 4048240 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
18770 root 20 0 94368 3672 2696 S 378.4 0.0 2:43.48 sysbench
看到內核cpu使用率很高。可疑行程為sysbench。此時可以使用pidstat命令檢視:
pidstat -wu -t 5 -p 18770
Linux 3.10.0-1160.15.2.el7.x86_64 (pulsar-1-348d-0002-f741-0002) 2021年07月23日 _x86_64_ (4 CPU)
11時11分26秒 UID TGID TID %usr %system %guest %CPU CPU Command
11時11分31秒 0 18770 - 98.60 100.00 0.00 100.00 3 sysbench
11時11分31秒 0 - 18770 0.00 0.00 0.00 0.00 3 |__sysbench
11時11分31秒 0 - 18771 9.00 28.60 0.00 37.60 2 |__sysbench
11時11分31秒 0 - 18772 9.60 27.40 0.00 37.00 3 |__sysbench
11時11分31秒 0 - 18773 9.80 29.00 0.00 38.80 3 |__sysbench
11時11分31秒 0 - 18774 9.60 27.80 0.00 37.40 2 |__sysbench
11時11分31秒 0 - 18775 9.80 29.00 0.00 38.80 1 |__sysbench
11時11分31秒 0 - 18776 10.40 27.80 0.00 38.20 2 |__sysbench
11時11分31秒 0 - 18777 11.20 27.00 0.00 38.20 1 |__sysbench
11時11分31秒 0 - 18778 9.80 27.40 0.00 37.20 2 |__sysbench
11時11分31秒 0 - 18779 9.80 28.20 0.00 38.00 2 |__sysbench
11時11分31秒 0 - 18780 9.80 28.40 0.00 38.20 0 |__sysbench
11時11分26秒 UID TGID TID cswch/s nvcswch/s Command
11時11分31秒 0 18770 - 0.00 0.00 sysbench
11時11分31秒 0 - 18770 0.00 0.00 |__sysbench
11時11分31秒 0 - 18771 47647.40 132455.60 |__sysbench
11時11分31秒 0 - 18772 47523.60 148473.80 |__sysbench
11時11分31秒 0 - 18773 44959.80 162137.20 |__sysbench
11時11分31秒 0 - 18774 46765.00 138126.60 |__sysbench
11時11分31秒 0 - 18775 47758.40 157361.60 |__sysbench
11時11分31秒 0 - 18776 47324.00 142616.40 |__sysbench
11時11分31秒 0 - 18777 48346.40 145743.60 |__sysbench
11時11分31秒 0 - 18778 49163.60 140320.40 |__sysbench
11時11分31秒 0 - 18779 47157.00 144586.60 |__sysbench
11時11分31秒 0 - 18780 46882.20 144493.00 |__sysbench
非自願上下文切換為15萬左右,說明系統存在強制排程,都在爭搶cpu時間,說明 CPU 為系統瓶頸。
上下文切換多少次才算正常?
這個數值其實取決於系統本身的 CPU 效能。如果系統的上下文切換次數比較穩定,且內核cpu使用率很低,都應該算是正常的。當上下文切換在一萬左右波動,且內核cpu使用率偏高,就很可能出現了效能問題。
總結
上下文切換發生在作業系統內核中。當看到內核cpu使用率過大,考慮在發生上下文切換。
自願上下文切換變多了,說明行程都在等待資源,有可能發生了 I/O 等其他問題;
非自願上下文切換變多了,說明行程都在被強制排程,也就是都在爭搶 CPU,說明 CPU 為系統瓶頸;
中斷次數變多了,說明 CPU 被中斷處理常式占用,還需要透過檢視 /proc/interrupts 檔來分析具體的中斷類別。
本文使用 文章同步助手 同步










