#人員重辨識##Transformer#
Self-Supervised Pre-Training for Transformer-Based Person Re-Identification
阿裏
基於 Transformer 的監督預訓練在人員重辨識(ReID)方面取得了很好的效能。但由於 ImageNet 和 ReID 數據集之間的域差距,通常需要一個更大的預訓練數據集(如ImageNet-21K)來提高效能,因為 Transformer 的數據擬合能力很強。
本次工作的目標是分別從數據和模型結構的角度緩解預訓練和 ReID 數據集之間的差距。
首先研究用 Vision Transformer(ViT)在無標簽的人物影像(LUPerson數據集)上進行預訓練的自監督學習(SSL)方法,並根據經驗發現它在 ReID 任務上明顯超過了ImageNet的監督預訓練模型。為進一步縮小域差距,加速預訓練,提出災難性遺忘分數(CFS)來評估預訓練和微調數據之間的差距。基於 CFS,透過對接近 down-stream ReID 數據的相關數據進行抽樣,並從預訓練數據集中過濾不相關的數據,選擇一個子集。對於模型結構,提出一個 ReID-specific 模組,IBN-based convolution stem (ICS),透過學習更多的不變特征來彌補域差距。
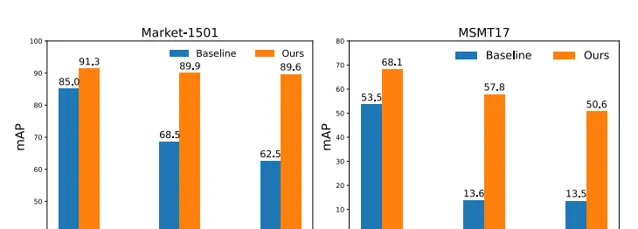
在監督學習、無監督域適應(UDA)和無監督學習(USL)的設定下,進行了大量的實驗來微調預訓練模型。並成功地將LUPerson數據集的規模縮小到50%,並且沒有效能下降。最後,在Market-1501和MSMT17上實作了最先進的效能。例如,ViT-S/16在Market1501的有監督/UDA/USL ReID上實作了91.3%/89.9%/89.6%的mAP準確性。
將開源:https:// github.com/michuanhaoha o/TransReID-SSL
論文:https:// arxiv.org/abs/2111.1208 4
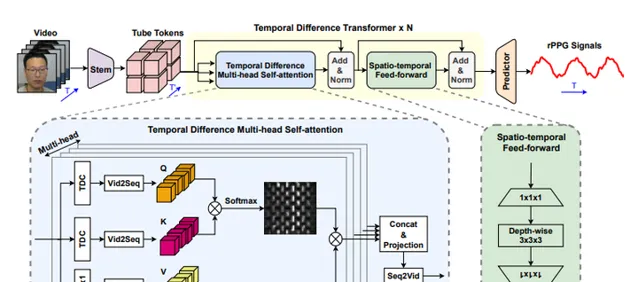
PhysFormer: Facial Video-based Physiological Measurement with Temporal Difference Transformer
芬蘭奧盧大學&英國牛津大學&西安交通大學&西北大學(PRC)
PhysFormer,是一個基於端到端的影片 Transformer 的架構,以自適應地聚集局部和全域的時空特征來增強 rPPG 表示。作為 PhysFormer 的關鍵模組,時差transformers 首先透過時差引導全域註意力來增強準周期性的rPPG特征,然後針對幹擾完善局部時空表示。此外,提出標簽分布學習和受課程學習啟發的頻域動態約束,為 PhysFormer 提供詳細的監督,並緩解過擬合現象。
在四個基準數據集上進行了綜合實驗,以證明它在數據集內部和跨數據集測試中的卓越表現。其中一個亮點是,與大多數需要從大規模數據集進行預訓練的Transformer 網絡不同,所提出的 PhysFormer 可以很容易地在 rPPG 數據集上從頭開始訓練,這使得它有希望成為rPPG社區的一個新型 Transformer 基線。
將開源:https:// github.com/ZitongYu/Phy sFormer
論文:https:// arxiv.org/abs/2111.1208 2
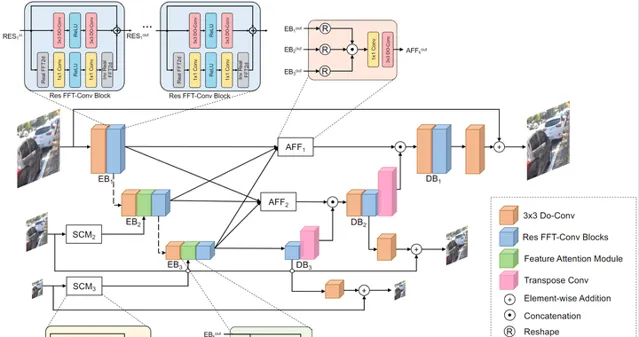
Deep Residual Fourier Transformation for Single Image Deblurring
華東師範大學&上海交通大學
文中提出 Residual Fast Fourier Transform with Convolution Block(Res FFT-Conv Block),能夠捕捉到長期和短期的相互作用,同時整合低頻和高頻的殘留誤差資訊。Res FFT-Conv 塊在概念上很簡單,但計算效率很高,而且是隨插即用的塊,可以在不同的架構中獲得顯著的效能提升。透過Res FFT-Conv塊,進一步提出基於 MIMO-UNet 的深度殘留誤差傅立葉變換(DeepRFT)框架,在 GoPro、HIDE、RealBlur 和 DPDD 數據集上實作了最先進的影像去模糊化效能。
實驗表明,DeepRFT可以顯著提高影像去模糊效能(例如,與MIMO-UNet相比,GoPro數據集的PSNR提高了1.09dB),DeepRFT+在GoPro數據集的PSNR甚至達到33.23dB。
已開源: https:// github.com/INVOKERer/De epRFT
論文:https:// arxiv.org/abs/2111.1174 5
LMGP: Lifted Multicut Meets Geometry Projections for Multi-Camera Multi-Object Tracking
薩爾大學&漢諾威大學等
多機位多目標跟蹤目前在電腦視覺領域備受關註,因為它在現實世界的套用中具有優越的效能,如在擁擠的場景或廣闊的空間中進行影片監控。
本次工作提出一個多機位多目標跟蹤方法,它是基於 spatial-temporal lifted 的 Multicut 公式。模型利用單鏡頭追蹤器產生的最先進追蹤器作為建議。由於這些追蹤器可能包含 ID-Switch 錯誤,作者透過從3D幾何投影中獲得的新型預聚類來完善它們。因此,得出一個沒有 ID-Switch 的更好的跟蹤圖,以及數據關聯階段更精確的 affinity 成本。
然後,透過解決一個global lifted 的 multicut 公式,將位於同一攝影機中的小追蹤器的短距離和長距離的時間互動以及攝影機之間的互動納入其中,將小追蹤器與多攝影機軌跡進行匹配。
在WildTrack數據集上的實驗結果接近完美,在Campus上的表現優於最先進的跟蹤器,而在PETS-09數據集上則與之相當。
將開源:https:// github.com/nhmduy/LMGP
論文:https:// arxiv.org/abs/2111.1189 2
 LMGP
https://www.zhihu.com/video/1446791246233088000
LMGP
https://www.zhihu.com/video/1446791246233088000
#弱監督##雲檢測#
Weakly-Supervised Cloud Detection with Fixed-Point GANs
奧胡斯大學
現有的基於 CNN 的監督式雲檢測方法需要大量的帶有像素級雲標簽的訓練影像,導致標簽成本大。因此,當像素級標簽不可用時,套用現有的基於 CNN 的方法來檢測越來越多的地球觀測衛星中的雲是非常昂貴的。
本次工作提出 FCD,一種弱監督的雲檢測方法,它只需要影像級別的標簽,而這些標簽的獲取成本要低得多。FCD 套用一個固定點 GAN 來學習清晰影像和多雲影像之間的影像轉換,同時確保在轉換過程中只有雲會受到影響。透過將影像轉譯成清晰的影像,從而去除任何雲層,能夠從原始影像和轉譯後的影像之間的差異中檢測到像素級別的雲層。由於FCD是一個生成模型,還提出 FCD+ 來完善FCD 生成的雲層掩碼,透過消除生成的副作用來進一步改進。
在包含全球各種生物群落的衛星影像的大型 Landsat-8 生物群落數據集上,證明了所提出方法優於現有的基於規則的方法和基於類啟用圖的弱監督方法的雲檢測。
此外,FCD+在僅用1%的可用像素級標簽進行微調後,達到了接近完全監督的效能。因此,所提出的方法能夠大幅減少訓練基於CNN的雲檢測器的標簽工作,並使效能損失最小。
已開源 :https:// github.com/jnyborg/fcd
論文:https:// arxiv.org/abs/2111.1187 9

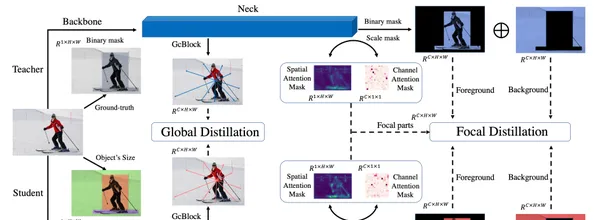
Focal and Global Knowledge Distillation for Detectors
清華大學深圳國際研究生院&字節跳動&北航
文中指出,學生檢測器需要註意教師檢測器的關鍵部份和全域關系。然後,提出Focal and Global Distillation(FGD)來指導學生檢測器。
Focal 蒸餾法分離了前景和背景,迫使學生對教師的關鍵像素和通道進行關註。Global 蒸餾法重建不同像素之間的關系,並將其從教師轉移到學生身上,彌補 Focal 蒸餾法中缺失的全域資訊。所提出方法只需要計算特征圖上的損失,因此 FGD 可以適用於各種檢測器。
在具有不同骨幹的各種檢測器上進行了實驗,結果表明,學生檢測器取得了出色的 mAP 改進。例如,基於 ResNet-50 的 RetinaNet、Faster RCNN、RepPoints和 Mask RCNN 用所提出蒸餾方法在 COCO2017 上實作了 40.7%、42.0%、42.0%和 42.1% 的 mAP,分別比基線高 3.3、3.6、3.4 和 2.9。
已開源 :https:// github.com/yzd-v/FGD
論文:https://
arxiv.org/abs/2111.1183
7
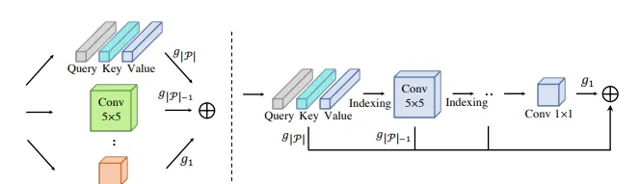
Pruning Self-attentions into Convolutional Layers in Single Path
蒙納士大學&悉尼大學&京東探索研究院
對於 Vision Transformers(ViTs)在電腦視覺任務中套用中,MSA 層對全域相關性進行建模會導致兩個被廣泛認知的問題:大量的計算資源消耗和缺乏對局部視覺模式進行建模的內在歸納偏見。
本次工作,作者在 MSA 和摺積運算之間引入一種新的分權方案,它允許用 MSA 參數的子集對摺積運算進行編碼,並同時最佳化這兩類運算。基於權重共享方案,提出SPViT,以減少 ViT 的計算成本,以及以低搜尋成本自動引入適當的歸納偏置。
在兩個有代表性的ViT模型上進行了廣泛的實驗,表明所提出方法取得了有利的準確性-效率權衡。
將開源:https:// github.com/zhuang-group /SPViT
論文:https:// arxiv.org/abs/2111.1180 2
#知識蒸餾##BMVC2021#
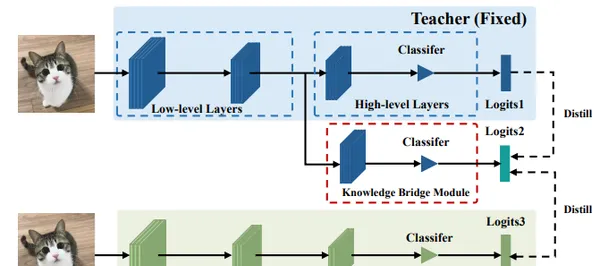
Semi-Online Knowledge Distillation
華南理工大學&哈爾濱工業大學
本文研究了教師模型在 KD 中支持更多可信的監督訊號,而學生在 DML 中捕捉到更多來自教師的類似行為。
基於這些觀察,作者首先提出在一個統一的框架中結合 KD 和 DML 。此外,提出一種半線上只是蒸餾(SOKD)方法,可有效地提高學生和教師的表現。在這個方法中,在 DML 中引入同伴教學的訓練方式,以緩解學生的模仿困難,同時也利用了 KD 中訓練有素的教師所提供的監督訊號。此外,還表明該框架可以很容易地擴充套件到基於特征的提煉方法。
在 CIFAR-100 和 ImageNe t數據集上進行的大量實驗表明,所提出的方法達到了最先進的效能。
已開源: https:// github.com/swlzq/Semi-O nline-KD
論文:https:// arxiv.org/abs/2111.1174 7
Modeling Temporal Concept Receptive Field Dynamically for Untrimmed Video Analysis
國科大&中科院&金山雲&哈爾濱工業大學&鵬城實驗室
本文探討了基於概念的事件辨識方法的時間接受域,以有效地進行未修剪的影片事件分析。
首先,引入時間動態摺積(TDC),賦予基於概念的事件辨識網絡更強的靈活性,它可以根據不同的輸入自適應地調整其感受野的大小。在TDC的基礎上,提出時間動態概念建模網絡(TDCMN),以學習準確和完整的概念表示,用於高效的未修剪影片分析。TDCMN 采用 TDC 來分析同一類別內和不同類別之間的概念的時間特征。
為了證明該模型的有效性,將TDCMN套用於兩個具有挑戰性的影片數據集FCVID和ActivityNet。與其他基於概念的事件辨識方法相比,TDCMN可以在很大程度上提高事件辨識效能。
已開源: https:// github.com/qzhb/TDCMN
論文:https:// arxiv.org/abs/2111.1165 3

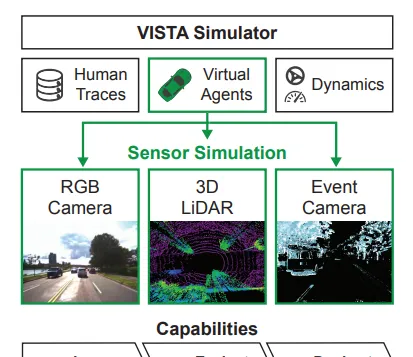
VISTA 2.0: An Open, Data-driven Simulator for Multimodal Sensing and Policy Learning for Autonomous Vehicles
麻省理工學院&University of Toronto and Toyota Research Institute
VISTA,是一個開源的模擬器,支持多模態傳感器的合成,包括二維RGB相機、三維LiDAR和基於事件的移動代理相機。該模擬器是數據驅動的,能夠合成足以用於policy learning (政策學習)和評估的高保真傳感器測量。
並透過在一個完整的自主車輛上為每個傳感器直接部署在VISTA中學習的政策來展示模擬到現實的能力,以及展示了模擬和現實世界測試中閉環評估的一致結果。
作者稱 VISTA 的釋出和可延伸性為社區感知和控制自主車輛開辟了新的研究機會。
將開源:https:// vista.csail.mit.edu/
論文:https:// arxiv.org/abs/2111.1208 3

![[Galtier 2016] 10.6 吸積盤中的磁旋轉不穩定性](http://img.jasve.com/2024-12/fa3e1dbd893c9ac61c1995a8153d789e.webp)









