嚴謹一點的回答是,漢語是世界上資訊熵最大的主流語言。
1948年,山農的【A mathematical theory of communication】一文震撼了學術界,從此開創了一個資訊度量時代。既然事件發生的資訊可以度量,語言也是一種資訊傳遞手段,那麽語言中的資訊究竟是多少?世界上有最優的語言嗎?
在正式開始之前,我們先來談談資訊熵跟資訊量之間的關系。
資訊量是事件可能性不確定度的度量, 第 i 個可能性中資訊量是 -logP_i , 比如明天下雨有下雨不下雨兩個可能性,下雨的概率是 P_1 ,那麽下雨的資訊量就是 -logP_1 .
資訊熵指的是事件發生的所有可能性中包含資訊的期望平均值,
H(X)=-\sum_{i}{P_i}log {P_i} 。
這裏的「事件」可以指代任何隨機發生的事情,比如提筆寫下隨機一個字。如果對上述定義不是很理解的話,可以參考下邊這個回答~
那麽,如果想要計算一個事件的資訊熵,需要什麽要素呢?從資訊熵公式,很明顯可以看出是 事件發生的所有可能性,以及對應的概率。
我們為什麽要計算語言的資訊熵呢?
拋開興趣不談,其實從科學研究角度,語言的資訊熵研究也有著非常現實的意義。如果可以準確的計算出語言的資訊熵,那麽就得到該語言的資訊壓縮的下界,即文本壓縮演算法到達這個界限再也無法壓縮。這種演算法就是該語言的最優壓縮演算法,不需要繼續最佳化辣。
現在可以回到原來的問題, 語言的資訊熵究竟是多少?
這個問題的計算方式其實很直觀,只需要代入資訊熵的公式就可以了。但是困擾消息理論和語言學者將近一個世紀的問題是, 我們無法準確地知道一個語言中特定文字的出現概率,甚至有時難以統計某種語言中究竟有多少種字元 。
消息理論科學家只能透過各種手段來 估計 各個語言的資訊熵,比如Shannon認為英語的資訊熵在0.6到1.3bits/字之間[1],Cover和King則認為英語的資訊熵是1.25bits/字[2]。差異來自於樣本和實驗方法的不同。英語等表音文字只有24個字母, 但是對於漢語,統計難度就大大增加了。幸運的是,當年消息理論發展不久,各行各業的科學家都投入了極大興趣來探索各種語言,即使中文有很大的特殊性,消息理論前輩們也排除萬難,用統計采樣的方式計算了漢語的資訊熵[3](數據集不完備),
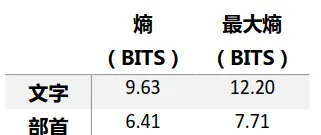
很明顯,中文不論從以文字,部首還是音節作為統計基礎,其資訊熵都遠遠超過英語。
看到這裏各位觀眾可能覺得已經滿足了, 但是這樣計算出的實驗結果並不能與其它語言直接對比 。因為上述實驗基於不同的數據集,不能確定實驗樣本是否蘊含著等量的資訊,同樣不能排除轉譯人員的個人原因導致的資訊誤差。
2002年,哈佛大學的Frederi等人重新做了對比實驗。他們認為,從過往的自然語言研究來看,自然語言都有著很多共同的統計特性和相似的模式。他們假設,對不同種類的語言,類似PPM這種基於馬爾科夫的壓縮演算法會忽視語言特性,把文本壓縮至逼近資訊壓縮下界[4]。
換句話說,如果采用的壓縮演算法不是針對某種語言特殊最佳化,不同的語言可以透過比較演算法的壓縮效率來近似比較資訊熵。因此他們設計了一個實驗,采用PPM演算法壓縮了各種不同版本的聖經:
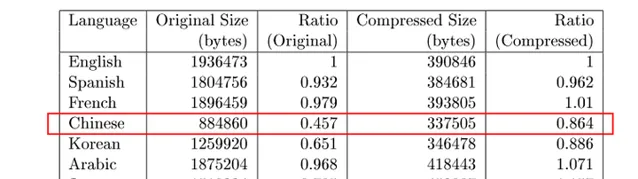
如上圖中,研究者們對比了英語,西班牙語,法語,中文,漢語,阿拉伯語,日文,俄語這些不同版本聖經的壓縮前檔大小,壓縮前檔大小與英文檔的比例,壓縮後檔大小,壓縮後檔大小與英文檔的比例等內容。理想條件下,如果轉譯,壓縮等過程沒有資訊損失,壓縮後其他語言檔大小與英文檔的比例應該等於1。
我們可以很明顯看到,中文的壓縮效率低於其他文字,但是這個壓縮效率是不是由於文本和壓縮演算法的原因引起的呢?他們又完成了如下兩個實驗,
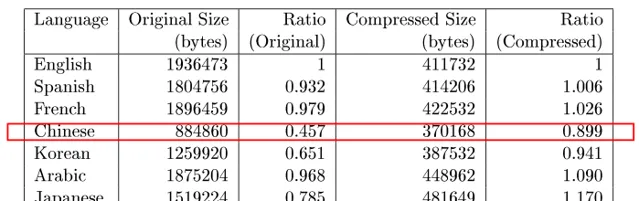
第二個實驗中采取了不同的壓縮演算法(BZIP2),結果相似,說明並不是壓縮演算法導致的壓縮效率低下。
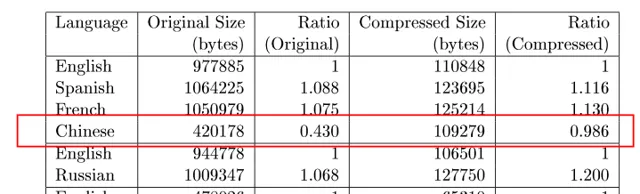
第三個實驗中采用了不同文本(歐盟法規),除英語外的所有譯文都被擴充了,而中文是其中被擴充最多的。對此研究者的解釋是,聖經的文本是非常普遍的詞匯,而歐盟法規中包含著很多特殊詞匯,從其他語言轉譯需要很長的文字擴充套件。這種現象可能是由於法律文本總是期望采用一些特殊詞匯來轉譯,這些詞匯在日常生活中出現的頻率不高,因此顯得資訊很多。如果將法律文本轉譯成普遍的詞匯,需要做一些語言擴充套件。但是依然可以看出,中文是「壓縮」效率最低的語言。
從上述三個對比實驗結果,可以得到結論,中文是壓縮效率最低的語言,或者可以認為是最接近資訊熵界限的語言。
雖然這個實驗設計的也並不完美,但是從多個實驗結果來看和近似估計來看,
中文是英語,西班牙語,法語,中文,漢語,阿拉伯語,日文,俄語這些主流語言中資訊熵最大的語言。
如果存在完美的語言,那麽應當達到資訊壓縮下界,但是即使我們知道了資訊壓縮的下界,怎麽達到它又是另外一個非常大的課題。
在找到辦法準確計算語言的資訊壓縮下界之前,類似是否存在/是否可以設計完美語言的這種問題我們都無法回答。
[1] Shannon C E. Prediction and entropy of printed English[J]. Bell system technical journal, 1951, 30(1): 50-64.
[2] Cover T, King R. A convergent gambling estimate of the entropy of English[J]. IEEE Transactions on Information Theory, 1978, 24(4): 413-421.
[3] Wong K, Poon R. A Comment on the Entropy of the Chinese Language[J]. IEEE Transactions on Acoustics, Speech, and Signal Processing, 1976, 24(6): 583-585.
[4] Fromkin V, Rodman R, Hyams N. An introduction to language[M]. Cengage Learning, 2018.
[5] Behr Jr F H, Fossum V, Mitzenmacher M D, et al. Estimating and comparing entropy across written natural languages using PPM compression[J]. 2002.











