編輯:LRS
【新智元導讀】只需幾十個樣本即可訓練專家模型,強化微調RLF能掀起強化學習熱潮嗎?具體技術實作尚不清楚,AI2此前開源的RLVR或許在技術思路上存在相似之處。
在2016年的NeurIPS會議上,圖靈獎得主Yann LeCun首次提出著名的「蛋糕比喻」:
如果智能是一塊蛋糕,那麽蛋糕中的大部份都是無監督學習,蛋糕上的糖霜(錦上添花)是有監督學習,蛋糕上的櫻桃則是強化學習。
If intelligence is a cake, the bulk of the cake is unsupervised learning, the icing on the cake is supervised learning, and the cherry on the cake is reinforcement learning (RL).
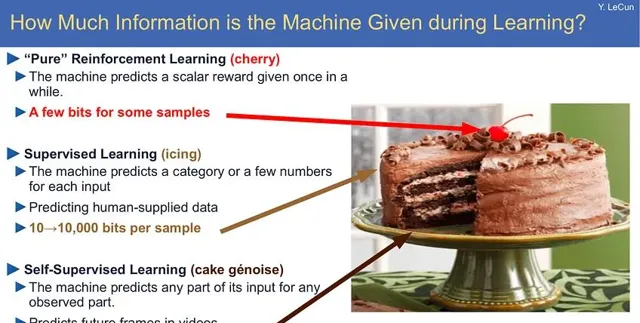
從大型語言模型的發展路線來看,這種比喻實在是完美預測:從計算量FLOP上的開銷來看,對互聯網上的海量數據進行自監督學習占據了大部份訓練時間;之後是用指令監督微調(SFT)數據進行後訓練,開銷相比自監督訓練來說大大降低;最後的強化學習則是讓大模型走向終端使用者的必備階段,可以提高模型的安全性,但模型只是從部份訓練樣本中學習少量資訊。
在OpenAI的第二天直播中,宣布即將開放 「強化微調」(RFT)的API ,開發者只需提供最低「幾十個」高質素樣本,就能實作領域專家模型的客製,還能根據提供的參考答案對模型的回復進行評分,再次印證了強化學習的重要性!
強化微調的重點是「匹配答案」(matching answer),給定查詢和正確答案,RFT可以幫助模型「學習」如何獲得正確答案。
相比標準的指令調優(instruction tuning)只是對數據進行1-2個epoch的損失計算,並更新模型權重,強化微調則是透過對相同的幾個數據點進行成百上千個epochs來讓模型有時間學習新行為。
重復數據在基礎模型訓練的時候作用不大,但卻可以提升RFT的穩定性。
強化學習的發展可能已經超過了Yann LeCun的預測,不再只是一顆蛋糕上的櫻桃,未來或許「有監督微調」不再那麽重要,只需要在互聯網數據上進行自監督,然後進行自我強化學習,而不需要明確的人工設計。
大模型技術路線再次顛覆
「強化微調」的出世,也標誌著語言模型和強化學習的發展路線再次發生變化:
1. 強化學習的穩定性是可以解決的
開發人員在考慮是否采用強化學習時,其穩定性一直是核心因素,主要體現在兩方面:強化學習本身可能會發生劇烈變化,不一定穩定有效;其次,強化學習的訓練本身比標準語言模型訓練更脆弱,更容易出現損失峰值、崩潰等情況。
如今OpenAI能釋出強化學習的API,雖然目前仍然處於測試階段,但也代表著他們對這項技術的穩定性有了突破,不管使用者的數據是什麽樣,都能穩定、有效地訓練。
以往,研究人員要執行強化學習演算法時,通常都會一次性執行多個隨機種子,然後選擇那些沒有崩潰的模型繼續執行;而現在就可以依賴強化學習模型的穩定執行,並在模型檢查點上與初始策略計算KL距離,以確保效果不會下降。
2. 開源版本或許已經「存在」
強化微調與AI2最近釋出的「具有可驗證獎勵的強化學習(RLVR)」工作非常相似,核心元件,如數據格式和最佳化器類別是相同的,只要開源社區繼續合作來增加強化學習數據,對不同的模型、不同類別的數據等進行實驗。
3. 高級推理模型的潛在數據飛輪
之前有猜測認為,OpenAI的o1模型使用了某種搜尋策略,主要透過大規模RL數據進行訓練,並具有可驗證的輸出,和這個API很類似。
按照預期來說,使用者透過API上傳數據,OpenAI就可以積累海量數據集來繼續訓練o1模型的下一個版本,o1目前的主要限制仍然是適用領域缺乏多樣性,如果有使用者的飛輪數據參與進來,o1勢必會更加強大。
4. 強化學習語言模型訓練的範圍不斷擴大
在基礎科學層面上,o1的最大的貢獻是,讓我們有了更多的方法來訓練語言模型,以實作潛在的高價值行為;向研究人員和工程師開放的大門越多,我們對人工智能的總體發展軌跡就應該越樂觀。
大概一年前,OpenAI的一位研究人員就曾提到過,他們對RLHF及相關方法非常有信心,因為損失函數比自回歸預測更通用,最近的發展也正如大部份人期待的,強化學習中的人類反饋(human feedback)也並不是特別必要。
強化微調實作的猜測
由於OpenAI沒有公布任何技術細節,所以對具體的實作仍然只能靠猜。
分類模型/配置(Grader models/configs act as reward shaping for generalized answer checking)
強化學習能成功實作的核心是「正確界定環境範圍」,其中環境由轉移函數(transition function)和獎勵函陣列成;
語言模型的轉移函數是人為設計的,也就是語言模型策略本身;獎勵函數是從狀態和動作(即提示和模型回復)到獎勵純量值的對映。
對語言模型的輸出答案進行評分並不新鮮,比如Llama 3.1同時使用「Python程式碼」和「其他大模型」作為判斷器來檢查數學答案是否正確;答案的錯誤或正確對應0或1的二進制分數。
12月7日,OpenAI微調團隊的John Allard此前釋出過一份關於評分器背後思路的說明,以及相關配置的螢幕截圖,基本思路是把待評分的回復分解成一個結構化的物件,然後對每一項的數值進行比較,得到精確率、召回率等指標。
比如想訓練一個資訊抽取器模型,評分器會根據預定義的結構,比如就讀的大學、已知的程式語言、當前居住城市等項分別進行評分,最後獲得一個匯總評分。
{ "university": "University of California Berkeley", "programming_languages": ["python", "c++", "java"], "city": "Los Angeles", "state": "California"}

推文連結:https://x.com/john__allard/status/1865520756559614090?s=46
數據效率最佳化
在直播中,OpenAI提到使用者只需要「幾十個」RFT樣本就可以在新領域進行學習;對於每個提示,強化學習(RL)可以根據超參數設定在一批中生成多個評分回復,在學習步驟和數據的多次叠代中「重復訓練」,因此模型能夠嘗試不同的「策略」來找到正確的答案。
比如用幾千個提示在數據集上執行數十萬條強化學習訓練數據,模型可以多次看到相同的提示而不會過度擬合。

穩定的基礎語言模型
事實證明,強化學習更適合微調而不是從頭開始訓練,基礎強化學習工作已經在控制和決策方面證明了這個結論;憑借非常穩定的基礎,強化學習微調可以溫和地搜尋更好的行為表達,而不會顯著改變模型效能。
比如某個RFT領域對於模型來說是非常新的,可能只需要10個樣本即可獲得總體效能提升。
對於OpenAI來說,o1模型經過大規模訓練,應該已經極其穩定了,可以作為強化學習微調的基礎, 其微調平台團隊成員John Allard就曾表示:任何人都可以利用相同的訓練演算法和基礎設施在新領域微調出一個專家o1模型。











