編輯:編輯部 HZh
【新智元導讀】 30多年的數學猜想首次獲得了進展!Meta等學者提出的PatternBoost,使用Transformer構造了一個反例,反駁了一個已懸而未決30年的猜想。是否所有數學問題都適合機器學習技術?這樣的未來太令人期待了。
30多年的數學猜想,被AI發現了一個反例?
就在剛剛,Meta、威斯康辛大學麥迪遜分校、伍斯特理工學院、悉尼大學的幾位學者提出PatternBoost,這種全新的方法可以在一些數學問題中尋找有趣的結構。

論文地址:https://arxiv.org/abs/2411.00566
其核心思想是交替進行「局部搜尋」和「全域搜尋」。
在第一個「局部」階段,使用傳統的經典搜尋演算法來生成許多理想的構造。
在第二個「全域」階段,使用Transformer神經網絡對這些最優構造進行訓練。然後,將訓練好的Transformer樣本用作第一個階段的種子,並重復該過程。
前者類似於貪心演算法,比如給定一個圖形,去除包含多個4-圈的邊,直到沒有4-圈為止。
而後者的一個例子,是讓Transformer生成更多類似於上次篩選中表現前1%的圖。
這種叠代交替,比傳統的貪婪方法或者單獨的非貪婪增強Transformer方法要好得多。
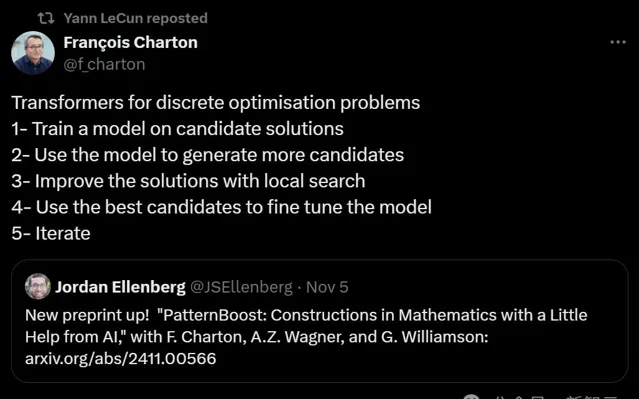
結合Transformers來求解離散最佳化問題的步驟
比起某些問題,它會更擅長解決另一些問題。因此,這篇論文在許多不同的數學領域測試了相同的協定。
哪些數學問題最適用於機器學習技術?或者說,最終我們將證明,所有數學問題都適合機器學習技術?
這個可能性,實在太令人興奮了。
PatternBoost不僅找到了幾個長期問題的最佳已知解決方案,而且還構造了一個反例,反駁了一個已懸而未決30年的猜想。
比如可以生成網絡拓撲中較為常見的C4-free稠密圖,也就是一幅不存在由4個頂點組成的閉合路徑的稠密圖。
PatternBoost在多個極值組合學問題中表現優異,其中一個經典套用是,就是無4-圈問題。
即在給定頂點數n的情況下,構造盡可能多的邊而不包含4-圈的圖。
此類問題對機器學習方法具有挑戰性,因為其數學結構較為復雜且解的空間巨大。
研究者是透過以下步驟套用PatternBoost的:首先生成一個初始數據集,並使用Transformer模型對其進行訓練以生成新樣本。
將這些新樣本作為局部搜尋的起點,經過多輪叠代後,PatternBoost在這個無4-圈問題上獲得了比傳統方法更佳的解。
「許多邊沒有三角形」問題
問題引入
現在讓我們來設想這樣一個問題:在一個n個頂點的圖中,如果沒有任何三個邊形成三角形,那麽它最多可以有多少條邊?
第一步,我們可以提出一些有許多邊,且沒有三角形的少量頂點上的圖。
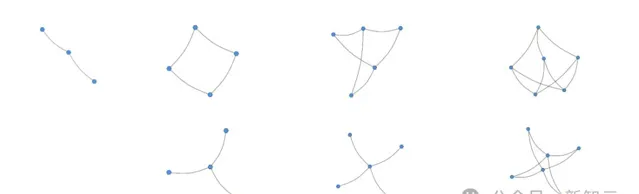
然後,我們會很幸運地註意到,許多範例實際上是二分圖。
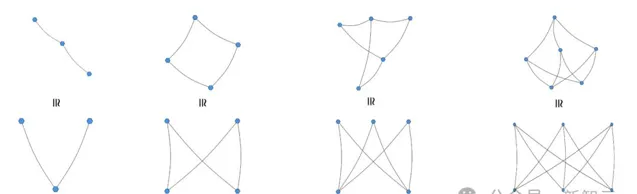
不難發現,這裏面大多數表現最優的圖形都是二分圖。而這一規律也被稱為稱為Turán三角定理或Mantel定理。
二分圖(Bipartite Graph)是一種特殊類別的圖,它的頂點可以被分成兩個互不相交的集合,比如說集合A和集合B。
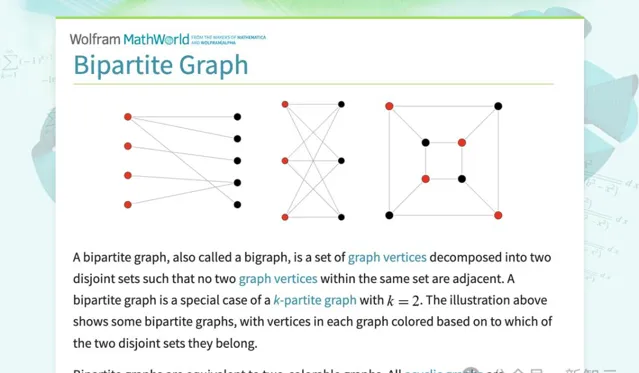
在二分圖中,每條邊都連線著集合A中的一個頂點和集合B中的一個頂點,也就是說,集合A中和B中各自都不存在將兩個頂點相連線的邊。
但是如果問題變得更加艱難,要求的結構不僅僅只是三角形呢?比如五邊形這樣更為復雜的結構。這時研究者就很難再憑借歸納和直覺去發現其最優結果中蘊含的規律了。
所以研究者希望有一種通用的方法,可以幫助發現或自行逐漸逼近這些結構。
PatternBoost就是這樣一種方法!
首先,研究者需要確定局部搜尋方法和評分函數。
局部搜尋法是一種將可能包含也可能不包含三角形的圖形作為輸入的演算法,並輸出一個得分至少與輸入得分相同的圖形。
由於研究者想要說明的是局部-全域叠代方法的有效性本身,所以不執著於最佳化局部搜尋函數,而是采用了很簡單的辦法。也就是:
- 當搜尋到的圖還包含三角形時,就刪掉其中的一條邊
- 一旦圖中已經沒有三角形,則在不建立新三角形的情況下,盡可能多地隨機添加新邊
評分函數則需要體現出當前得到的結構逼近於最優結構的程度。
例如,如果圖包含任何三角形,研究者可以決定給出負無窮大的分數,否則返回邊的數量。邊的數量越大,則分數越高。
需要註意的是,如果圖形中有三角形,研究者也可以從三角形中直接刪除任何邊,以使分數至少增加1
具體步驟
第一步:建立起始數據庫
研究者的步驟如下:從空圖開始,以此為起點執行上述簡單的局部搜尋演算法(即在不產生三角形的情況下,盡可能長時間地隨機添加邊)。
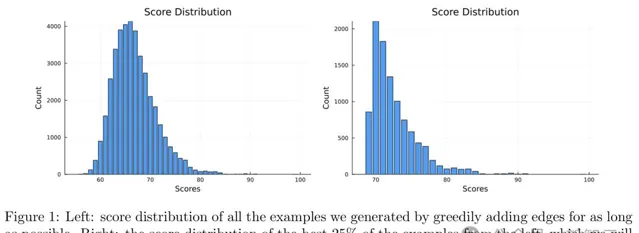
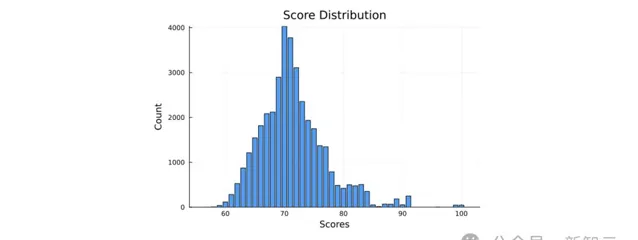
他們重復了40,000次,每次都從空圖開始,得到的分數分布如圖1所示(由於局部搜尋的輸出永遠不會出現三角形,因此這裏的分數只是邊的數量)。
大部份圖形分數的分布都是一個平滑的分布,峰值為66。然後研究者保留了該數據集中得分最高的25%;這些圖形將作為訓練集。
從圖1右側的直方圖中可以看到訓練集的分數分布。
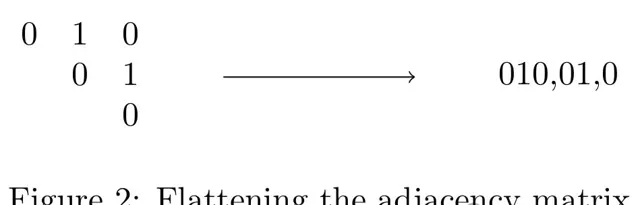
訓練集中的每個圖都可以用其鄰接矩陣來表示,該矩陣有n²=20²=400個條目。
研究者註意到,鄰接矩陣是對稱的,而且沒有迴圈,因此可以使用矩陣的上三角部份而不是整個矩陣,從而將其減少到20×19/2 = 190。
研究者使用的Transformer接受一維輸入;因此,研究者可以將上三角矩陣逐行寫出,並在每行後加上分隔符(在本例中為逗號),從而將其扁平化,如圖2所示。
在開始訓練之前,可以透過Byte-Pair Encoding (BPE) Tokenization來標記化數據以去進一步的資料壓縮。
也就是說,如果研究者發現字串「00101」在數據集中出現了很多次,那麽研究者就引入一個新的字元,比如「2」,來表示這個字串。

第二步:訓練Transformer
研究者使用的是Makemore,這是Andrej Karpathy的一個簡單的Transformer實作。
他的程式碼的優點是,它是公開可用的,並且易於修改,並且它提供了一個穩固的基線,因此研究者可以嘗試用更復雜的方法超越它。
研究者使用了一個微小的2層Transformer,包含4個頭部和16的嵌入維度。
他們訓練這個Transformer來生成與初始數據集中的「相似」的序列,方法類似於將一個大型英語句子數據庫(即序列中的大多數是單詞)給Transformer進行訓練,使其能夠生成更多的英語句子。
在訓練的每一個階段,都可以讓Transformer預測給定的k個token序列之後的下一個token。特別地,對於每一個k和數據集中每個圖G(用token序列表示),可以讓Transformer在給定前k個token的情況下預測第k+1個token。
「損失」衡量了Transformer未能正確預測G中實際下一個token的頻率。經過15,000步的訓練後,訓練集的損失降到2.07,測試集的損失為2.09。
第三步:從Transformer獲取新結構
接下來,研究者要求Transformer生成在某種「全域」意義上與研究者迄今為止遇到的最佳圖形(即訓練集中的圖形)相似的新結構。
研究者以這種方式生成了100,000個tokenized的新圖形。在將token序列解碼為矩陣(或嘗試解碼為矩陣)後,研究者得到了37,000個矩陣的條目數(190),這與20個頂點圖的鄰接矩陣相符。
第四步:從Transformer中獲得的新結構中,執行本地搜尋
研究者把從小模型中得到的37000個有效結構圖,重新輸入到他們的簡單局部搜尋演算法中。
也就是說,從這37,000個圖形中的每一個中,研究者首先貪婪地刪除邊以去除所有三角形,然後盡可能長時間地隨機添加邊而不產生任何新的三角形。
第五步:重復此過程
最後,研究者重復提取上一代中最好的10,000個詞組,使用之前相同的token對它們進行分詞,並在這個新的訓練集上微調Transformer。
請註意,每次叠代都不需要從頭開始訓練。透過再進行5次迴圈,模型很快學會只生成完整的二分圖,而且這些二分圖中的大多數都具有相等的兩部份大小,見圖4。
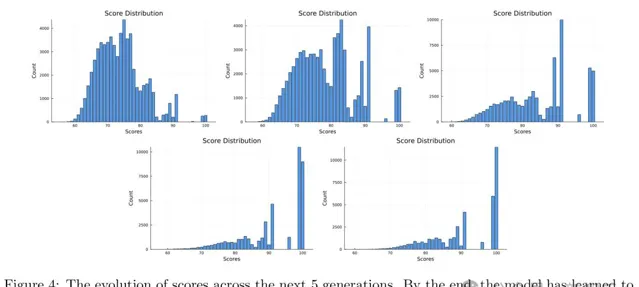
可以直觀地發現,隨著叠代的代數增加,分數分布的峰值也逐漸越來越高,從75轉移到了最終的滿分100,十分直接地證明了局部+全域聯合叠代搜尋這種流程的有效性。
長期未解決的猜想:d-維超立方體直徑為d的生成子圖
超立方體(Hypercube)是一種常見的網絡拓撲結構,其結構為一個具有高對稱性的n維立方體,每個頂點與其他所有頂點都直接相連。
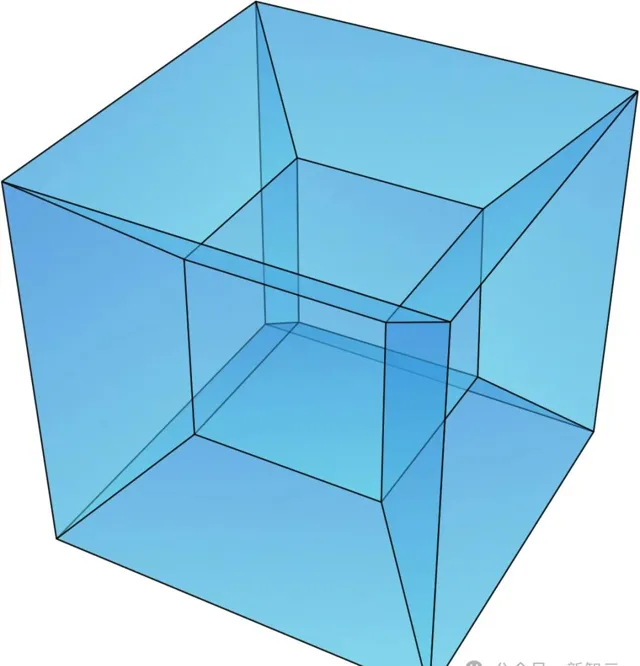
在超立方體中,直徑是一個重要的概念,它表示從任意一個頂點到另一個頂點所需的最大步數。
對於平行計算網絡,如大規模平行計算機中的處理器網絡,超立方體的直徑是描述其通訊效率的關鍵參數,因為它直接影響到網絡中的通訊速度和延遲。
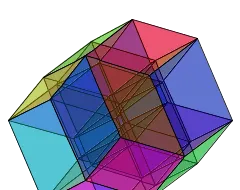
因此,研究超立方體的直徑以及如何透過改變其結構來最佳化直徑成為了一個重要的研究方向。
在論文中提到的長期未解決的問題是:在不增加其直徑的情況下,可以從d-維超立方體中刪除的最大邊數是多少?
這個問題最早由Niali Graham和Frank Harary在1992年提出,問題也可以表述為,怎麽構造直徑始終是d的d維超立方體的最小生成子圖。
對於這個問題,曾經提出的猜想具體是這樣的:
他們觀察到,如果固定兩個相對的頂點v和v′,並透過為每個頂點u(u不屬於{v, v′})構建一個子圖G,其中包括一條通向在d-維立方體中更接近v的頂點的邊和一條通向在d-維立方體中更接近v′的頂點的邊,則生成的子圖是全覆蓋的且具有直徑d。這樣的子圖至少有
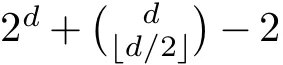 條邊,並且可以透過多種方式實作這樣的構造。
條邊,並且可以透過多種方式實作這樣的構造。
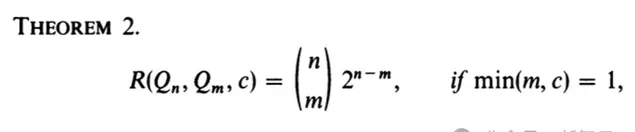
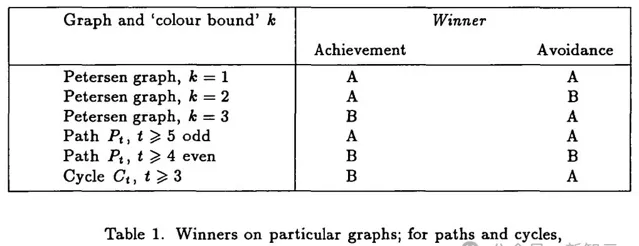
問題來了:是否存在一種更好的構造,可以用到更少的邊?Graham猜想,這種構造實際上就是最優的。
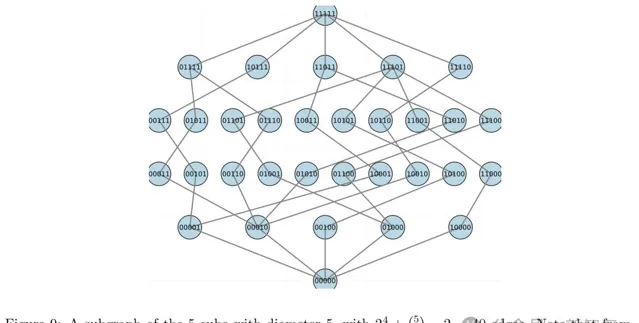
一個直徑為5的5維超立方體的子圖,包含40條邊。註意,從每個頂點都有一條邊向下和一條邊向上連線,即不存在阻塞頂點
對於PatternBoost,有一種自然的方法來建立這個猜想。一個具有跨度並且直徑為d的子圖的分數可以定義為其中的邊數(研究者試圖將其最小化)。
反例的提出
對於局部搜尋,最簡單的演算法是,給定一個子圖G,向G中隨機添加邊,直到它成為一個具有直徑d的跨度圖,然後在盡可能長的時間內隨機移除邊,同時保持直徑為d。
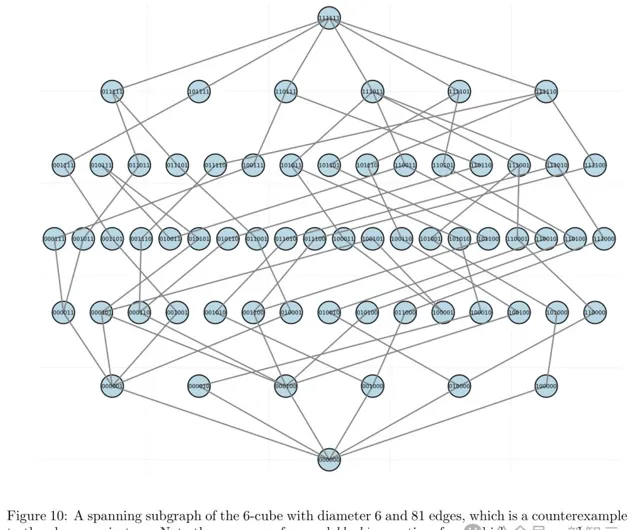
研究者對d=5和6的情況,進行了實驗。
對於d=5,上述構造似乎是最優的,但對於d=6,研究者能夠找到一個具有81條邊的圖(而非上述構造中的
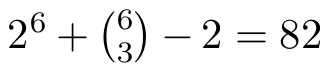 條邊),見圖10。
條邊),見圖10。
這推翻了之前的猜想,並標誌著在這個問題上30年來的首次進展。
一個有趣的觀察是,對於較大的d值,下界或上界哪個更接近真實情況。
用AI生成純數學構造
總的來說,在本文中,研究者介紹並舉例說明了一種稱為PatternBoost的計算方法,用於生成純數學中有趣的構造。
該方法涉及「局部」與「全域」步驟的反復交替。前者通常是一個簡單的貪婪演算法,後者則是一種結合Transformer的遺傳演算法,這是一種靈活的機器學習技術,研究者認為其特別適合處理此類問題。
為了理解這種叠代可能的樣子,可以考慮一個集體合作叠代的例子,即單車的設計。
- 「局部」步驟涉及許多單個單車制造商各自對他們的設計進行一系列精細調整,努力使其盡可能地高效和舒適。
- 「全域」步驟則涉及生活在世界各地的人們,他們看到周圍的許多單車,每一輛都經過精心的局部最佳化,然後基於他們觀察到的單車進而設計開發出新的單車設計。

當然,這種新設計隨後會由其設計者和其他人精心最佳化;如果經過這些調整後,新單車被證明特別舒適和高效,那麽它們將被大量銷售,並加入下一位潛在設計者觀察到的一般單車佇列中……如此周而復始。
數學物件並非單車。但人類可以抽象出單車的特征,並開發出研究者認知為單車的新物件,盡管它們與任何現有例項都不完全相同,數學家對數學物件也是如此。然而,這個過程通常很難自動化。
研究者對這裏描述的方法的希望在於,機器學習的技術(尤其是 Transformer)至少具備某種程度的這種能力——即面對一系列數學實體時,它們可以產生更多在某些方面「同類」的例子,便於互相參照,進行叠代。
研究者的工作受到第三作者早期工作的強烈影響。在那項工作中,強化學習中的交叉熵方法被用來尋找組合學中幾個問題的反例。
交叉熵方法的問題在於其擴充套件性:當序列長度超過幾百個Token時,基礎神經網絡就會變得難以訓練。
在AI中,當嘗試使用基礎神經網絡對長序列的字母或單詞進行下一個Token預測時,也會遇到類似的問題,而Transformer架構正是在這類問題上表現出色。
PatternBoost的主要優勢之一,就是其廣泛的適用性。透過添加一個使用Transformer的全域步驟來為局部搜尋建議更好的起點,PatternBoost可以改良許多最佳化問題的結果。
PatternBoost可以視為放置在任何局部搜尋方法之上的額外層,通常能比單獨使用局部搜尋獲得更好的解決方案。
簡單來說,無論研究者使用何種局部搜尋演算法,PatternBoost 通常都能使其更好。
研究者強調,研究者的主要目標是為數學工作者開發一個有用且簡單的工具,該工具不需要深入的機器學習專業知識或使用工業級計算能力。
使用機器學習作為數學中的實用工具的一個困難在於,機器學習本身很復雜!人們可能會花費大量時間來調整超參數、探索不同的Token化方案等。
在研究者看來,PatternBoost的一個優點在於其Transformer架構表現得非常具有彈性,通常可以直接使用,而不需要數學家進行過多的調整,因為他們的專業和興趣可能在其他領域。
他們使用了Andrej Kaparthy的Makemore提供的一個美觀且簡單的Transformer實作,在研究者的實驗中,它似乎在廣泛的數學背景下都生成了有效的輸出。
這裏討論的問題只是他們在開發PatternBoost時嘗試的最初幾個問題——他們希望並期望其他數學家會興致盎然地進行進一步的實驗,從而幫助揭開哪些數學問題適合於機器學習增強方法的這一神秘面紗。
特別是,本文討論的例子主要集中在極值組合數學領域,其中Transformer被用來構造在某些約束條件下盡可能大的組合例子。
當然,組合結構是最容易作為Transformer輸入呈現的實體;但他們並不認為該方法原則上僅限於數學的這一領域。
事實上,該方法中沒有任何內容是特定於數學的!他們也十分有興趣了解PatternBoost是否可以套用於數學之外的問題。
顯而易見的一個挑戰是,在數學中,一個被提議的例子通常可以被機械地、可靠快速地評估,這對PatternBoost至關重要;而在其他領域,評估可能會比較困難。
涉及到的機器學習技術
模型訓練完成後,研究者會從「空序列」t0 開始生成候選方案,並從訓練模型預測的分布中抽取第一個標記t1。
然後,研究者會向模型輸入t0 t1序列,並從預測的分布中采樣第二個token t2。如此反復,直到生成完整的解決方案。
這將鼓勵模型生成與其訓練數據類似的序列(即研究者問題的有希望的解決方案)。
為了將數學結構(如網格和圖)編碼為Transformer可以處理的形式,需要將這些結構轉換為token序列,這一過程稱為「分詞」。
以下是具體的編碼方法:
對於網格編碼來講,一個𝑛×𝑛的網格可以用n^2個二進制條目表示,每個條目表示一個單元格的狀態(0或1)。
即使n值適中,這種樸素的二進制表示也會導致非常長的序列,增加學習的復雜性。
為了減少序列長度,研究者可以將多個二進制條目編碼為一個標記,從而在詞匯表大小和序列長度之間進行權衡。
例如,可以將4個二進制條目編碼為一個token,這樣詞匯表大小會增加,但序列長度會減少。
而圖編碼則是可以采用鄰接矩陣的表示方法,用二進制表示時,可以采用n(n-1)個二進制條目表示,每個條目表示一條邊的存在狀態。
類似地,也可以將多個二進制條目編碼為一個token,以減少序列長度。
每個序列始終以特殊的 <start> 標記開始,以 <end> 標記結束,以便模型知道序列的開始和結束位置。
透過將數學結構(如網格和圖)編碼為Transformer可以處理的標記序列,PatternBoost能夠利用Transformer的強大建模能力來生成復雜的數學構造。
這種編碼方法不僅減少了序列長度,提高了學習效率,還使得模型能夠生成與訓練數據相似的有希望的解決方案。這種方法在多個離散數學問題中展示了其有效性和靈活性。











