編輯:LRST
【新智元導讀】 研究人員對基於Transformer的Re-ID研究進行了全面回顧和深入分析,將現有工作分類為影像/影片Re-ID、數據/標註受限的Re-ID、跨模態Re-ID以及特殊Re-ID場景,提出了Transformer基線UntransReID,設計動物Re-ID的標準化基準測試,為未來Re-ID研究提供新手冊。
目標重辨識(Object Re-identification,簡稱Re-ID)旨在跨不同時間和場景辨識特定物件。
近年來,基於Transformer的Re-ID改變了該領域長期由 摺積神經網絡 (CNN)主導的格局,不斷重新整理效能記錄,取得重大突破。
與以往基於CNN與有限目標類別的Re-ID綜述不同,來自武漢大學、中山大學以及印第安納大學的研究人員全面回顧了近年來關於Transformer在Re-ID中日益增長的套用研究,深入分析Transformer的優勢所在,總結了Transformer在四個廣泛研究的Re-ID方向上的套用,同時將動物加入Re-ID目標類別,揭示Transformer架構在動物Re-ID套用的巨大潛力。

論文地址:http://arxiv.org/abs/2401.06960
專案地址:https://github.com/mangye16/ReID-Survey

Transformer架構方法打破CNN架構效能記錄
研究背景
Transformer以優異效能滿足各種Re-ID任務的需求,提供一種強大、靈活且統一的解決方案。
研究人員將現有工作分類為基於影像/影片的Re-ID、數據/標註受限的Re-ID、跨模態Re-ID及特殊Re-ID場景,詳細闡述Transformer在應對這些領域中各種挑戰時所展現的優勢。
考慮到無監督Re-ID的流行趨勢,研究人員提出了新的Transformer基線——UntransReID,在單模態/跨模態任務實作最先進效能。
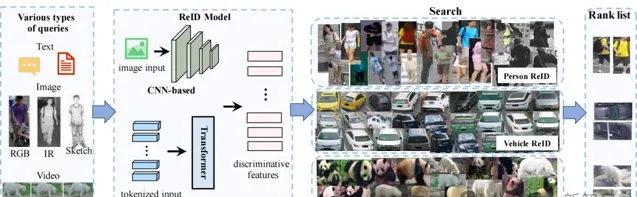
一般的Re-ID流程
針對尚未被充分探索的動物Re-ID領域,研究人員還設計了標準化的基準測試,進行廣泛的實驗以探討Transformer在這一任務中的適用性,促進未來研究。
最後,討論了一些在大模型時代中重要但尚未深入研究的開放性問題。
Transformer在圖片/影片Re-ID的套用
Transformer在backbone層依靠註意力機制,具有全域、局部和時空關系的通用建模能力,有助於在影像/影片Re-ID任務中輕松提取全域、細粒度和時空資訊。
Transformer在影像Re-ID的套用
1. 架構最佳化:設計特殊的Transformer架構,如金字塔結構、層次聚合等,或改進註意力機制。
2. Re-ID特定設計:利用視覺Transformer具備註意力機制和影像塊嵌入的特性,捕捉局部區分性資訊。透過Transformer中的編碼器-解碼器結構實作某些關鍵資訊的解耦。根據不同目標類別的結構先驗和任務特性進行Transformer架構設計。

影像Re-ID方法設計的不同Transformer架構
Transformer在影片Re-ID的套用
1. 套用Transformer進行後處理:許多套用Transformer的影片Re-ID方法為混合架構,先利用CNN模型提取特征,再使用Transformer模型進一步處理。透過Transformer的自註意力機制,捕捉序列中的長期依賴關系和上下文資訊。
2. 純Transformer架構:為克服混合架構中CNN導致的長距離資訊獲取受限,一些研究嘗試探索純Transformer架構在影片Re-ID中的套用。
數據/標註受限的Re-ID
Transformer為無監督學習提供更多可能。Transformer能夠對更強大、更通用的模型進行廣泛自監督預訓練,以應對數據或標註受限的Re-ID任務。標註受限場景通常采取無監督Re-ID,而數據受限則主要透過領域泛化Re-ID解決。
Transformer在無監督Re-ID的套用
1. 自監督預訓練:一類針對無監督Re-ID中Transformer套用的研究關註自監督預訓練。Transformer模型對大規模無標簽數據具有強大可延伸性,其結構的靈活性提供了更多樣化的自監督範式。
2. 無監督領域自適應:Transformer在無監督領域自適應(UDA)問題中受到的關註有限。對於行人Re-ID,Wang等人借助Transformer實作不同身體部位之間的細粒度領域對齊。對於車輛Re-ID,一項工作透過聯合訓練策略,令Transformer自適應地關註每個域中車輛的判別部份。
Transformer在跨模態Re-ID的套用
Transformer提供了統一的架構,有效處理不同模態的數據。多頭註意力機制可在各種特征空間和全域語境中聚合特征。高度適應力的編碼器-解碼器結構可容納不同類別的輸入和輸出。因此Transformer特別適合在跨模態Re-ID中建立模態間關聯,促進多模態資訊的融合。
可見光-紅外Re-ID 旨在匹配白天的可見光影像與夜間的紅外影像。因紅外影像缺乏顏色與光照條件,視覺Transformer可更好地捕捉模態不變特征並具備更強的魯棒性。視覺Transformer的結構及其註意力機制可在 patch 級別輕松建立局部跨模態關聯。現有可見光-紅外Re-ID方法聚焦於學習模態共享特征,將特征分解為模態特定特征和共享模態特征,在特征層面進行模態對齊。
文本-影像Re-ID 為跨模態檢索任務,根據文本描述在影像庫中辨識目標。作為Transformer架構在多模態套用中的裏程碑,對比語言-影像預訓練(CLIP)等大型多模態預訓練模型使該領域取得顯著進展。近期,CLIP已成為下遊文本-影像Re-ID任務中的有力工具。
素描-影像Re-ID與骨架Re-ID 均屬於跨模態匹配任務,前者基於藝術家或業余者繪制的素描,後者則基於姿態估計生成的骨架圖。Transformer擅長提取全域特征,在素描-影像Re-ID中表現突出。對於骨架Re-ID,可利用Transformer對骨架點構成的圖結構進行全關系建模。
Transformer在特殊Re-ID的套用
在實際套用需求的推動下,Re-ID領域出現一系列特殊套用場景。Transformer被初步套用於這些復雜挑戰,體現了卓越的可延伸性和適應力。
遮擋Re-ID: 遮擋Re-ID場景下,圖片中的辨識目標被部份遮擋,導致身份資訊難以完整提取。近年來基於Transformer的方法在這一場景取得顯著成效,其核心策略包括提取局部區域特征。
換衣Re-ID: 在長期Re-ID場景中,行人可能會以未知方式更換衣物,以服裝外觀為主導的判別性特征表示將失效。Lee等人在換裝Re-ID場景下對不同的特征提取主幹網絡進行評估,Transformer架構相較於CNN表現出顯著效能優勢。
以人為中心的任務: 以人為中心的通用模型旨在將包括行人檢測、姿態估計、內容辨識和人體解析在內的多個人體相關任務整合到同一框架中,從而相互促進,提升如Re-ID這類下遊任務的效能。
行人檢索: 行人檢索是一種端到端方法,透過多工學習同時解決行人檢測與Re-ID這兩個目標沖突的問題。將多尺度Transformer架構引入行人檢索方案可實作查詢層面的例項級匹配。
群體Re-ID: 群體Re-ID利用群體中的上下文資訊來匹配在同一個群體中的個體,面臨群體成員變動與布局變化等挑戰。傳統方法在位置建模方面存在不足,利用Transformer的位置嵌入機制可更好地處理群體級別的布局特性。
無人機Re-ID : 與固定網絡攝影機相比,無人機在高度與視角上快速變化,導致影像更為復雜。在鳥瞰影像中分析車輛與行人時,顯著的邊界框尺寸差異與物體方向不確定性是關鍵挑戰。除了純無人機視角Re-ID外,還有研究重點關註空中與地面視角的跨域匹配。

特殊Re-ID場景
新基線UntransReID
研究人員提出了一個單模態/跨模態的常規無監督Re-ID基線UntransReID。
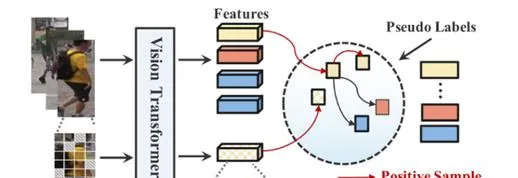
無監督Re-ID基線UntransReID
單模態無監督Re-ID: 研究人員在無監督訓練過程中設計了一種面向patch級別的mask增強策略。在數據增強過程中采用一系列learnable tokens來mask部份影像patch,並在訓練過程中建立原始特征與掩碼特征之間的對應關系,將此作為監督訊號來引導模型學習。
跨模態無監督Re-ID: 針對可見光-紅外跨模態行人Re-ID,研究人員設計了一種雙流Transformer結構,包含兩個面向特定模態的patch嵌入層以及一個模態共享的Transformer。為進一步提升模態的泛化能力,在可見光通道中引入隨機通道增強作為額外的輸入,實作聯合訓練。
實驗結果分析: 對於單模態無監督Re-ID,UntransReID取得了與當前最先進方法相當的效能。跨模態Re-ID現有先進方法大多基於CNN且需要復雜的跨模態關聯設計,UntransReID在多個可見光-紅外Re-ID數據集上憑借簡潔的設計實作了最先進的效能。
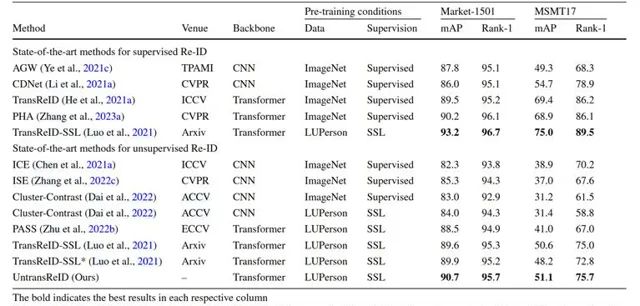
表1 基於CNN/Transformer的有監督/無監督方法的實驗結果
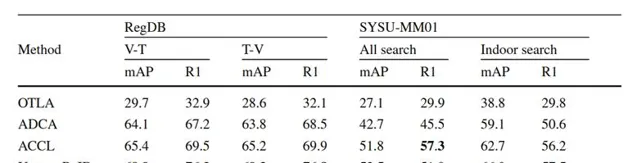
表2 可見光-紅外跨模態基線在RegDB和SYSU-MM01上的實驗結果
動物Re-ID
研究人員特別探討了動物Re-ID領域研究現狀,總結近年來的動物Re-ID數據集和基於深度學習的動物Re-ID方法,為動物Re-ID制定統一的實驗標準,並評估在此背景下使用Transformer的可行性,為未來的研究奠定堅實基礎。

近年來的動物Re-ID數據集
動物Re-ID方法
基於全域影像的方法: 許多現有研究借鑒行人Re-ID的傳統方法,將完整的動物影像輸入深度神經網絡以獲取可靠的特征表示。
基於局部區域的方法: 一些工作在數據采集與特征提取階段關註動物的關鍵部位,例如牛的頭部、大象耳朵、鯨魚尾巴以及海豚的鰭等。
基於輔助資訊的方法: Zhang等人以牦牛頭部左右朝向的簡化姿態為輔助監督訊號,強化特征表示;Li等人借助姿態關鍵點估計將老虎影像劃分為多個身體部位進行局部特征學習。
動物Re-ID的統一基準測試
研究人員使用多種先進的通用Re-ID方法進行了廣泛動物Re-ID實驗。實驗評估了基於CNN架構的BoT方法和基於Transformer架構的TransReID、RotTrans方法。基於Transformer架構的方法在多數情形下表現更優,本實驗證明了Transformer在動物Re-ID套用的可行性與巨大潛力。
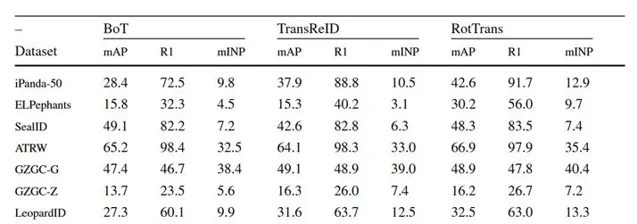
最先進的Re-ID方法在多個動物數據集上的評估結果
未來展望
Re-ID與大語言模型的結合
將大語言模型(LLM)與Re-ID任務深度融合正成為熱門研究方向。透過生成或理解視覺數據的文本描述,LLM可在細粒度語意提取、無標記數據的利用以及模型泛化能力提升等方面為Re-ID提供有力支持。
通用Re-ID大模型構建
滿足多模態、多目標的實際套用場景是Re-ID未來的重要訴求。Transformer在多模態數據融合和大模型訓練中表現出突出能力,可用於同時處理視覺、文本乃至更多元的資訊,從而建立模態無關、任務統一的通用Re-ID模型。
面向高效部署的Transformer最佳化
影片監控、智能安防等場景要求即時性與輕量級部署,在保持Transformer魯棒性的同時需要減少計算開銷。有效遷移通用預訓練模型的知識到特定Re-ID任務,應對大規模動態更新中的災難性遺忘問題,這些也是未來亟待解決的課題。











