論文連結:https:// arxiv.org/pdf/2501.0400 3
專案連結:https:// drive-bench.github.io/
數據集連結:https:// huggingface.co/datasets /drive-bench/arena
作者單位:加州大學艾榮分校 上海人工智能實驗室 新加坡國立大學 新加坡南洋理工大學 S-Lab 香港大學
註:本工作由具身智能之心獨家解讀,轉載歡迎聯系我們;

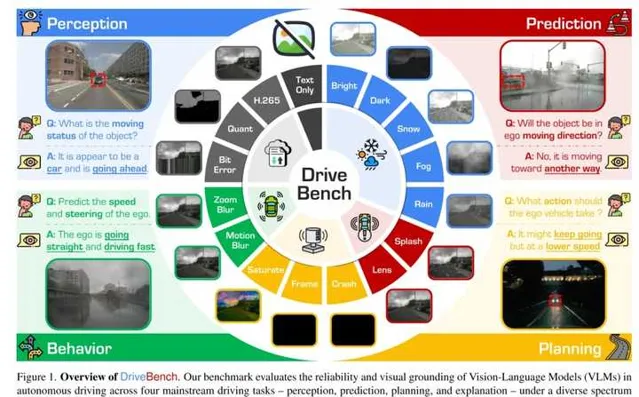
這裏提出的基準測試從 感知 、 預測 、 規劃 和 解釋 四個主流駕駛任務出發,評估視覺語言模型(VLMs)在自動駕駛中的可靠性和視覺基礎能力。測試覆蓋了17種輸入設定(清晰輸入、損壞輸入和僅文本輸入),包含19,200幀影像和20,498個問答對,涉及三種問題類別:多項選擇、開放式問答和視覺基礎問題。透過應對多樣化的任務和條件, DriveBench 旨在揭示 VLM 的局限性,推動可靠且可解釋的自動駕駛發展 。
原文連結: VLM為自動駕駛做好準備了嗎?從感知、預測、規劃和解釋性四個任務出發探討內容出自國內首個具身智能全棧學習社區:具身智能之心知識星球,這裏包含所有你想要的。
寫在前面
近年來, 視覺語言模型(Vision-Language Models, VLMs) 的進展引發了其在自動駕駛領域套用的廣泛興趣,尤其是在透過自然語言生成可解釋駕駛決策方面。然而,VLMs 能夠內在地提供視覺基礎、可靠且可解釋的駕駛解釋這一假設仍缺乏系統性驗證。為填補這一研究空白,這裏提出了 DriveBench ,一個評估 VLM 可靠性的基準數據集。該數據集覆蓋了17種輸入設定(包括清晰輸入、損壞輸入和僅文本輸入),包含19,200幀影像、20,498個問答對、三類問題類別、四種主流駕駛任務,以及總計12種主流 VLMs。
研究發現,VLMs 通常基於通用知識或文本線索生成合理的響應,而非真正依賴視覺資訊,特別是在視覺輸入退化或缺失的情況下。這種行為由於數據集的不平衡性和評估指標的不足而被掩蓋,然而在諸如自動駕駛等對安全性要求極高的場景中,這種缺陷可能帶來顯著風險。此外,本文觀察到 VLMs 在多模態推理方面存在困難,並對輸入損壞表現出高度敏感性,導致效能不一致。
針對這些挑戰,該工作提出了最佳化的評估指標,重點關註穩健的視覺基礎和多模態理解能力。同時,強調了利用 VLMs 對輸入損壞的感知能力來提升其可靠性的潛力,進而為開發更可信且具有可解釋性的真實世界自動駕駛決策系統提供了路線圖。 該基準工具包現已公開釋出。
實證研究的思路
隨著 視覺語言模型(Vision-Language Models, VLMs) 的最新進展,在自動駕駛套用中引入 VLMs 的研究興趣日益增加。這些研究涵蓋了端到端框架的設計,以及透過自然語言提升可解釋互動與決策的 VLMs 整合。這種可解釋性被認為能夠增強自動駕駛系統的透明性、可信度和使用者信心。
然而,先前的研究指出,在開環(open-loop)設定中評估端到端自動駕駛模型存在顯著局限性。因此,與其專註於使用潛在不可靠的開環端到端 VLMs 進行軌跡預測,本文轉而關註另一個重要但尚未被充分探索的問題,該問題在諸多研究中被廣泛假設:
現有的視覺語言模型(VLMs)是否能夠基於視覺線索為駕駛提供可靠的解釋?
為此,該工作研究了 VLMs 生成的駕駛決策是否真正基於來自物理環境的感知資訊,抑或僅反映了通用知識和基於文本線索的虛構響應。
模型可靠性
為回答這一核心問題,透過 分布外(Out-of-Distribution, OoD)魯棒性 的視角評估 VLM 的可靠性。為此,提出了 DriveBench ,一個基準數據集,涵蓋四種主流駕駛任務和15種數據損壞類別,包括19,200張影像和20,498個針對真實自動駕駛場景設計的問答對。
為了評估在極端條件下的魯棒性,該工作透過僅使用文本提示(text-only prompts)將視覺退化推至極限。令人驚訝的是,即使在沒有任何視覺線索的情況下,VLM 的表現與在「清晰」視覺輸入下的輸出相當(如圖2所示)。這一現象與人類駕駛員的表現形成鮮明對比,因為在如此惡劣的條件下,人類駕駛員通常難以應對。
深入分析表明,這種表面上的「韌性」往往是由於數據集不平衡和評估協定不完善造成的,而非模型自身具備的內在魯棒性。
數據集
該工作對現有的「語言驅動駕駛」(Driving with Language)基準數據集進行了深入分析,發現了關鍵缺陷,尤其是在數據集不平衡方面的問題。這些基準數據集大多基於流行的駕駛數據集構建,如 nuScenes 、 BDD 和 Waymo Open ,並繼承了其原始設計中的局限性。
例如,不平衡的數據分布導致評估結果傾斜,使得過於簡單的回答(如「直行」)在與運動相關的查詢中即可實作超過90%的準確率。此外,許多基準數據集依賴於單幀問題,而這些問題通常需要時間上下文的支持,這甚至對人類標註者來說也存在挑戰。
因此,這些基準數據集存在固有的偏差和持續的負樣本問題,這削弱了評估結果的可解釋性和可靠性。
指標
這裏還對現有的指標設計進行了深入的重新評估。針對駕駛套用中的語言互動,目前通常使用傳統的模式匹配指標進行評估,如 ROUGE 、 BLEU 和 CIDEr ,這些指標最初為摘要和轉譯任務而設計。然而,正如先前工作所指出的,這些指標在評估復雜的語言驅動駕駛決策時存在顯著局限性。
即使是現代評估方法(如基於 GPT 的評分機制),在沒有任務特定評分規則的情況下,也難以提供深入見解。 這些限制凸顯了需要能夠有效捕捉推理能力、上下文理解和安全關鍵因素的指標。
該工作倡導開發更加先進的評估指標,這些指標應結合任務特定的評分規則、結構化問題格式以及上下文駕駛資訊,從而更準確地評估 VLM 在真實世界場景中的表現。
關鍵見解
透過一系列全面的實驗,該工作從分析中得出了一些關鍵見解。實驗覆蓋了 17種輸入設定 (包括清晰輸入、僅文本輸入以及各種損壞輸入)、 12種 VLMs (包含開源和營運模式)、 5個任務 (感知、預測、規劃、行為和損壞辨識)以及 3種評估指標 (準確率、傳統語言指標和基於 GPT 的評分)。這些發現揭示了在將 VLMs 整合到駕駛場景中所面臨的當前挑戰:
- 退化條件下的虛構響應 :在視覺條件退化的情況下,VLMs 通常生成看似合理但實為虛構的響應,包括在完全沒有視覺線索的場景中。這引發了對其可靠性和可信度的擔憂,因為此類行為難以透過現有的數據集和評估協定進行檢測。
- 對視覺損壞的感知 :盡管 VLMs 在一定程度上能夠感知視覺損壞,但僅在被直接提示時才會明確承認這些問題。這凸顯了模型在自主評估視覺輸入可靠性以及提供針對具體場景和安全性的響應方面的能力有限。
- 數據集偏差的影響 :高度偏向的數據集和次優的評估協定可能導致對 VLM 效能的誤導性認知。在許多情況下,VLMs 更傾向於依賴通用知識而非實際的視覺線索來生成響應,這在現有指標下可能意外地獲得高分。
- 客製化評估指標的需求 :現有的評估指標,包括傳統的語言指標和基於 GPT 的評分,無法充分反映自動駕駛任務的復雜需求。亟需開發專門的評估指標,以更有效地評估 VLMs 的推理能力、上下文理解能力以及安全關鍵因素。
該工作的研究透過 DriveBench 不僅突出了改進數據集和評估協定的必要性,還為開發更安全、更具可解釋性的真實世界自動駕駛系統中的 VLMs 奠定了基礎。
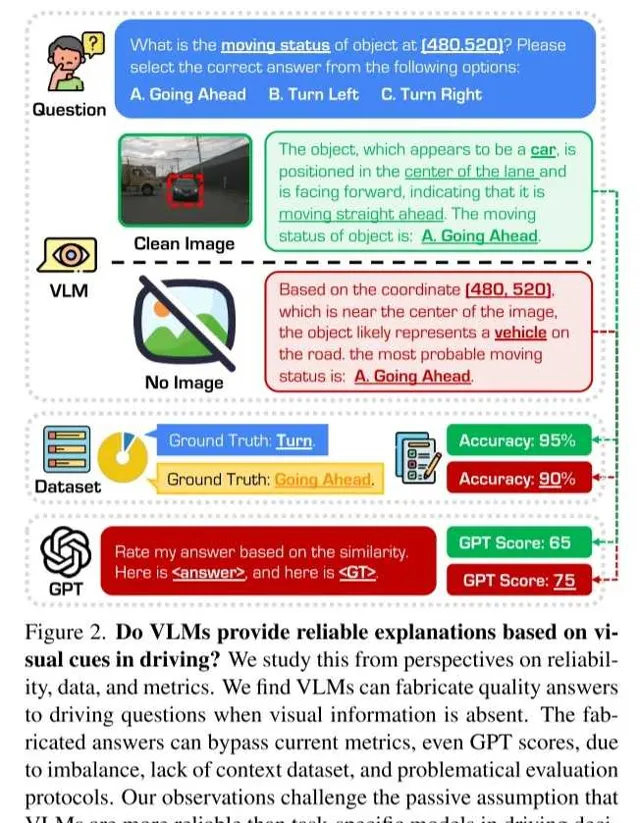
從 可靠性 、 數據 和 指標 三個視角對此進行研究。研究發現,當視覺資訊缺失時,VLMs 仍能夠生成高質素的駕駛問題答案。然而,這些虛構的答案由於數據集不平衡、缺乏上下文資訊以及評估協定存在問題,能夠透過現有指標的檢驗,包括基於 GPT 的評分。這一觀察挑戰了之前的假設,即 VLMs 因其基於視覺的可解釋性響應在駕駛決策中比任務專用模型更可靠。
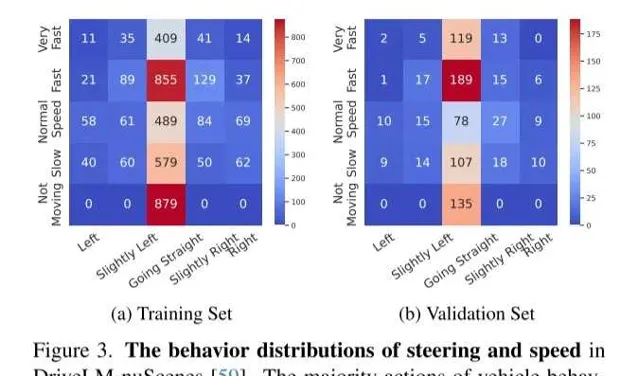
車輛行為的主要動作是「直行」,這一現象在 [39] 中也有所提及。

結果來源於 DriveLMAgent 。其中, No Pix. 表示無影像像素輸入, No Fea. 表示無特征輸入。

結果來自 GPT4-o 。
(a):黑色轎車正左轉,左轉訊號燈已亮。
(b):黑色轎車正右轉。模型卻對兩者均預測為「直行」。這些範例展示了在轉向選擇(Turn choice)中的挑戰性案例,其中視覺線索過於細微或需要依賴時間上下文才能做出正確預測。
(c) 和 (d) 均為右轉場景,但由於存在重疊或遮擋,模型無法基於中心像素位置正確定位物體。

從提出的基準數據集中的問答對提取的詞雲,突出顯示了 DriveBench 中不同自動駕駛任務的主要關註點。字型越大,出現頻率越高。
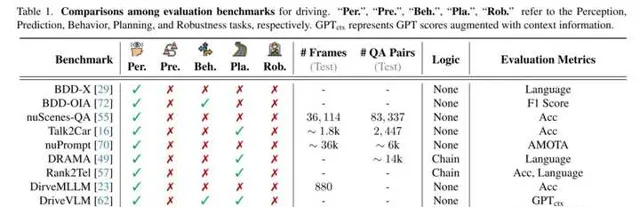
「Per.」、「Pre.」、「Beh.」、「Pla.」、「Rob.」 分別表示感知、預測、行為、規劃和魯棒性任務。 表示結合上下文資訊增強的 GPT 評分。
實驗結果分析


(a):GPT-4o 透過物體相對於幀的位置變化來推斷行人運動狀態,而非基於運動物體本身的座標,導致感知結果錯誤。
(b):模型在基於目標物體座標區分正確方向時表現困難。
(c):GPT-4o 透過物體相對於當前幀的相對位置推斷 SUV 的運動狀態,導致感知結果錯誤。
(d):GPT-4o 未能正確感知汽車的朝向。
(e):數據集中包含需要多幀推理才能成功的範例,但 GPT-4o 無法透過單幀輸入解決這些問題。
(f):GPT-4o 透過物體相對於當前幀的相對位置推斷 SUV 的運動狀態,再次導致感知結果錯誤。
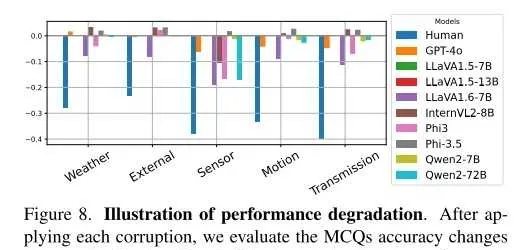
在每種損壞條件下,該工作評估多項選擇題(MCQs)準確率相對於清晰輸入的變化。結果顯示,人類效能大幅下降,而大多數 VLM 的表現幾乎沒有變化。
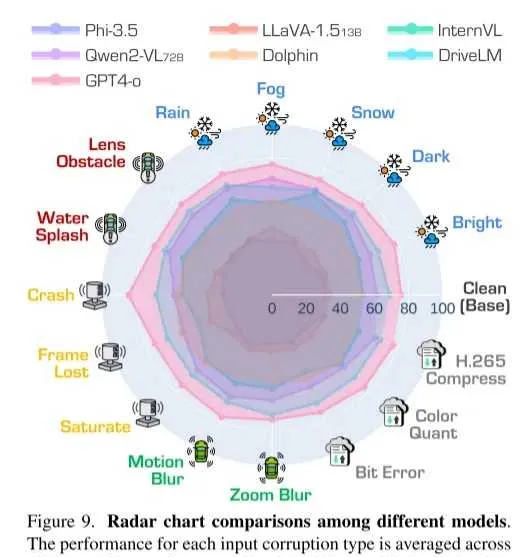
每種輸入損壞類別的效能透過四種駕駛任務中的 1,261 個問題的平均值計算得出。評估指標為 GPT 評分。

該模型可能透過利用文本線索(如問題中的相機和座標位置),在沒有視覺資訊的情況下「猜測」多項選擇題(MCQ)的答案。

語言指標(如 ROUGE-L 和 BLEU-4 )表現出較高的一致性,而 GPT 評分顯示了顯著的差異。同時,該工作發現微調過程顯著提升了 DriveLM 在規範響應格式方面的能力,從而在語言指標下表現出誤導性較高的效能。

該工作還研究了準確率或 ROUGE-L 分別與 GPT 評分在開放式問題和多項選擇題(MCQs)中的匹配程度。結果發現,ROUGE-L 未能反映駕駛中關鍵的語意資訊(如關鍵物體)。相比之下,準確率與 MCQs 的 GPT 評分具有較好的一致性,而在答案正確的情況下,GPT 評分能夠進一步捕捉解釋中的細微差異。

GPT 評分根據評分規則、問題內容和實際駕駛上下文的不同而有所變化。隨著資訊的逐步增加,評估結果變得更加可區分。
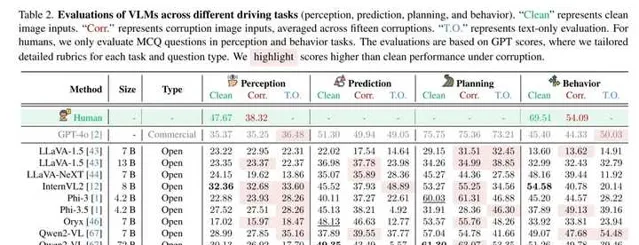
「Clean」 表示清晰影像輸入,「Corr.」 表示損壞影像輸入(取15種損壞的平均值),「T.O.」 表示僅文本輸入的評估。對於人類測試者,本文僅在感知和行為任務中評估多項選擇題(MCQ)。評估基於 GPT 評分,並針對每個任務和問題類別客製了詳細的評分規則。對於在損壞條件下表現優於清晰輸入的分數進行了高亮顯示。

該工作觀察到,大部份模型即使在缺乏視覺資訊的情況下,其效能也未明顯下降。這表明,VLMs 的響應可能主要依賴於多數偏差(例如,在大多數駕駛場景中選擇「直行」),而非利用傳感器提供的視覺線索。

這裏還註意到,在問題中提及損壞類別後,模型效能顯著下降。這表明 VLMs 能夠感知當前的損壞情況,並在被明確提示時承認它們無法對嚴重退化的視覺資訊作出有效響應。
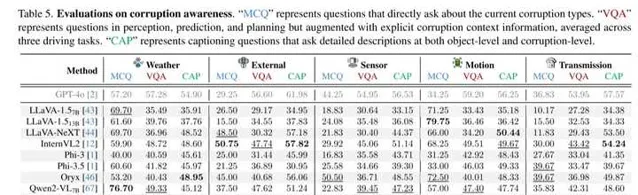
「MCQ」 表示直接詢問當前損壞類別的多項選擇題;
「VQA」 表示針對感知、預測和規劃任務的問題,但增加了明確的損壞上下文資訊,結果取三種駕駛任務的平均值;
「CAP」 表示要求在物體層級和損壞層級提供詳細描述的字幕生成問題。
最後總結下
該工作辨識並探討了在自動駕駛中部署 視覺語言模型(VLMs) 所面臨的關鍵挑戰,重點關註其在復雜真實場景中的視覺基礎可靠性。研究結果表明,在嚴重視覺退化的情況下,VLMs 經常生成看似合理但缺乏依據的響應,這對其在關鍵決策任務中的可靠性提出了質疑。此外,不平衡的數據集和次優的評估協定加劇了這些問題,導致對 VLM 可靠性的高估。
為緩解這些挑戰,該工作倡導未來的研究重點發展 平衡性良好且上下文感知的數據集 ,以及能夠嚴格評估駕駛決策質素、上下文推理和安全性的 先進評估指標 。
參照:
@article{xie2025drivebench,
author = {Xie, Shaoyuan and Kong, Lingdong and Dong, Yuhao and Sima, Chonghao and Zhang, Wenwei and Chen, Qi Alfred and Liu, Ziwei and Pan, Liang},
title = {Are VLMs Ready for Autonomous Driving? An Empirical Study from the Reliability, Data, and Metric Perspectives},
journal = {arXiv preprint arXiv:2501.04003},
year = {2025},
}
更多視覺化範例:

觀察到,GPT-4o 能夠意識到低光環境,並能夠從影像中辨識出公交車和行人,展現了一定的魯棒性。

觀察到,GPT-4o 受到此類損壞的影響,傾向於基於模糊預測「行駛速度快」。該範例表明視覺損壞對高層次駕駛決策產生影響的潛在可能性。

觀察到,GPT-4o 能夠基於可見的物體進行響應,而 LLaVA-NeXT 和 DriveLM 則傾向於虛構提供影像中不可見的物體。

觀察到,在嚴重的視覺損壞條件下,VLMs 傾向於基於其學習的知識給出模糊且籠統的答案,而不參考視覺資訊。大多數響應提及交通訊號和行人,盡管它們在提供的影像中並不可見。
寫在最後
重磅!國內首個具身智能技術社區來啦!近20+學習體系
歡迎star和follow我們的倉庫,裏麪包含了BEV/多模態融合/Occupancy/毫米波雷達視覺感知/車道線檢測/3D感知/多模態融合/線上地圖/多傳感器標定/Nerf/大模型/規劃控制/軌跡預測等眾多技術綜述與論文;
推薦閱讀
具身智能演算法與落地平台來啦!國內首個面向科研及工業的全棧具身智能機械臂
具身智能視覺語言動作模型,VLA怎麽入門?
具身智能與傳統機器人任務有什麽區別?主流方案有哪些?











