如果目的是為了快速發論文,那麽RL好;如果是為了好找工作,那麽SLAM好。
從工業角度,RL距離落地還有很遠的距離,或者說基本在實際系統上沒用。如果看未來五年的「錢」景,果斷SLAM。SLAM雖然成熟,但是還是有很多點可以挖掘,比如裏程計的精度提升、多傳感器融合機制、更有效的閉環檢測、長航城的地圖拼接融合等。這些問題在學術上沒有完美的解決方案,但是在工程上可以創造很大的商業價值。從學術角度,兩者的意義一樣大。這篇論述,我會從我在CMU的實際經歷帶大家感受一下SLAM和RL各自的魅力,不一定會幫各位決定以後要研究的方向,但可能在一定程度上回答大家的部份疑惑。
前言
此份總結可能會有點長,分別涵蓋我們過去5年在卡內基梅隆大學從事過的一些前沿工作,也包含在SLAM和RL領域的幾篇IEEE T-RO,IJRR和若幹IEEE RAL工作,我會慢慢更新。2023年6月起,我開始入職香港城市大學,長期從事SLAM,RL,Multi-agent工作。MetaSLAM是我們成立的一個非盈利組織,致力於提供最前沿的機器人相關(SLAM,RL,Multi-agent等)研究工作,我們的核心成果也會在裏面有所展示。
官網:MetaSLAM
Github:https:// github.com/MetaSLAM
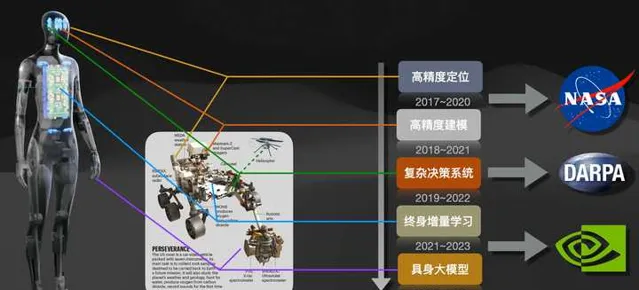
如上圖所示,是我們在過去5年多所從事的工作,時間跨度從2017年9月到2023年5月,涵蓋了SLAM、Planning、Lifelong Learning和Embodied AI的相關研究。長期以來我們一直在尋找RL和SLAM最融洽的結合點,隨著2023年大模型ChatGPT的火爆和Tesla 人形機器人的發展,這個思路似乎也在變得越來越清晰。關於機器人與大模型之間的意義,請參考我最近更新的下面文章。
在本篇文章中,我們會先從SLAM和RL兩個領域分別出發探討其在機器人領域的價值。需要指出的是,因為篇幅有限,本篇所涉及的SLAM和RL工作,僅從可以在實際機器人系統中實用的相關工作進行探討。最後,我們也會進一步分析一把,如何把SLAM和RL跟大模型系統LLM緊密耦合起來。
1. SLAM&RL的內在關聯
從本質上講,SLAM和RL本來就應該是繫結在一起的。SLAM的初衷是幫助機器人實作定位導航,但是他的作用並不僅僅只是定位導航。我們當前在做SLAM的時候,只關心定位的效率、建圖的精度等,但是這些只是SLAM的外部表現。SLAM的最大作用實際上是一個巨大的數據關聯中心,他可以把所遇到的場景、事物、地點、時間等要素關聯起來(雖然聽起來沒啥用),因此他本身是一個數據庫。當我們在做重定位的時候,Loop Closure Detection會嘗試克服環境的視角變化、光照天氣變化而提取初相互管理的場景資訊,這其實就是在觸發SLAM的關聯能力。在這種關聯作用下,SLAM其實有辦法把發生的「事物」和特定的「場景」、「時間」關聯起來,也就構成了我們在強化學習裏面經常提到的「記憶」。而在強化學習領域,我們可以很多學習任務的Model-based或者Model-free學習策略,但是我們卻往往忽略「位置」資訊。這一點跟動物或者人完全不同,我們不會在打遊戲的時候考慮「一會做飯的時候應該如何控制刀具的角度」,或者工廠裏加工零件的時候回呼「4歲學舞蹈課的時候腿的步調順序」。因為我們有一些特殊的功能區「Working Memory",而這些區域的最大特點就是-> (把發生的「事物」和特定的「場景」、「時間」關聯起來)。 有意思的是,對於人或者動物,SLAM中所涉及的定位問題、記憶問題和我們的行為的最佳化都跟一個模組直接相關,那就是 Hippocampus。
嚴格意義的講,現在我們常見到的只是SLAM的一個分支,metric-SLAM,這一類方法追求定位精度。但是SLAM還有另一個分支,那就是topological-SLAM->拓撲SLAM,這種方式在10年前的概率機器人時代比較火,後來隨著metric-slam的普及被人淡忘了。之前跟著Howie Choset大哥混的時候,就是被他一篇20年前的工作吸引過去的,哈哈。拓撲SLAM追求對於地圖的高層次抽取,追求地圖資訊的融合和hierarchy層次的表達,由於過於抽象,難以在工程中達到厘米級定位而被放棄,但是拓撲SLAM卻是最早模仿人和動物的感知行為而建立的。下面我會從SLAM和RL兩個角度分析當前的進展,和兩者合並的必要性。
2. 我們先來講一講SLAM
關於當前SLAM的文章或者書籍一堆,我就不展開了,這裏做簡化處理。一般意義中的SLAM中包括什麽模組主要為以下三個:
- 裏程計 : 包括常見的視覺、激光、毫米波裏程計,實作連續幀間的姿態估計。
- 閉環檢測 :loop closure detection, 也叫place recognition,根據傳感器資訊在視角變化、環境變化情況下,重辨識出歷史軌跡。
- 後端最佳化 :圖最佳化的各類演算法,iSAM系列,Factor Graph結點合並剪枝等等。
當前SLAM技術在裏程計和後端最佳化方面已經誕生了很多傑出的的成果,在 裏程計 方面,視覺裏程計中的ORB-SLAM系列,VINS-mono系列,激光裏程計中的LOAM系列、Livox-LOAM系列、Catographer系列,都構建了相對比較完備的裏程計系統。在 後端最佳化 方面,gtsam,ceres,g2o也基本把大部份的後端最佳化問題處理的比較妥當。但是,不管是基於視覺還是基於激光的SLAM系統,在現實中用的時候都無法實作large-scale和long-term下的定位導航,這是為什麽呢?這裏面的工程問題和理論問題背後又有什麽耐人尋味的秘密呢?
( 2023年6月13 日更)
時隔約一年,讓我們繼續這個話題。讓我們先繼續完成對於SLAM的論述,我將會從一個親歷者視角,回答為什麽SLAM技術依舊是非常重要的存在。如在前文中所提到的,SLAM技術的關鍵技術中,閉環檢測是非常關鍵的一環,因為它能直接決定移動機器人在大尺度(Large-scale)和長航程(Long-term)環境下的魯棒性。這一點尤其在無人駕駛領域,特種機器人領域,服務機器人領域等有著重要的作用。如果配以高效能的視覺/激光裏程計,以及魯棒的後端最佳化操作,SLAM可以發揮出巨大的潛力。下面我就從我自己相關的三個專案,帶大家一起感受一下。
2.1 NASA火星登陸專案中的SLAM定位問題 (2019~2022年)
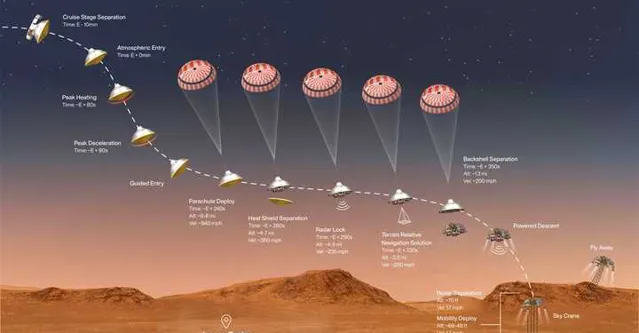
大概是在2019年時,我當時在CMU跟Ji Zhang大哥(LOAM & V-LOAM鼻祖)拉到一個NASA的專案,那就是設計一套輔助NASA火星車精確降落的方案。這件事的原因很簡單,在火星上不比地球,因此一般飛行器只能粗略的落在一個指定的區域,但是精度就完全指望不上了,離譜的話有可能會偏出去幾公裏(畢竟安全降落就已經不容易了,哈哈)。但這樣不好地方在於,機器人往往單個行動,而很難與其他前期的機器人協同工作。因此我們經常聽到新聞,哪個火星車又陷在沙子裏出不來了,或者翻車了在嘗試自救。因此很多人都在想,如果給登陸機器人提供高效能抗造能力強的定位系統,那麽後來的機器就可以精準的降落到指定的規劃區,一方面可以輔助前期的機器人,另一方面也可以進行多機協作,甚至可以推進人造基地這種高端的設計了:)。

理想是美好的,但是現實是打臉的:
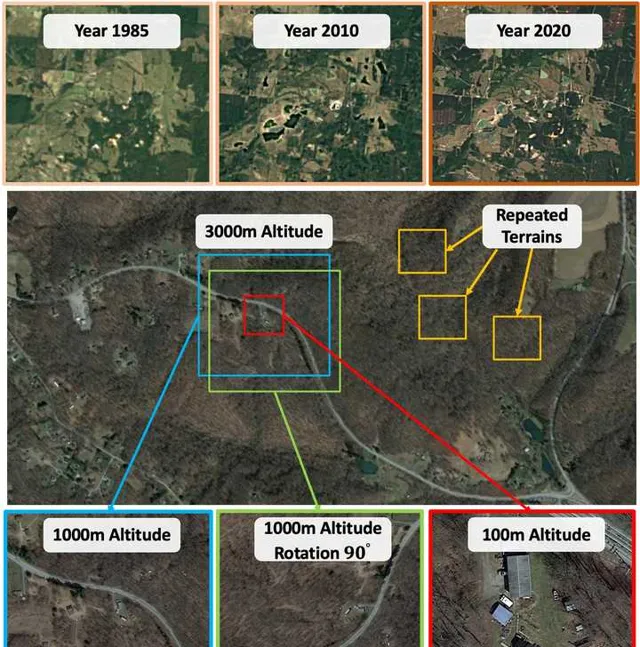
因此如何在這種情況下,實作穩定的定位能力(降落定位精度控制在20m內),是我們面臨的核心問題。這個問題放在SLAM裏面,其實也就是:「如何在 視角未知 、 外觀變化 、 場景重復 的條件下,實作穩定的場景辨識(或者閉環檢測)。」 其復雜程度可以用下圖表示,假設我們將要把機器人降落到圖中紅色的框區域:1)此圖上面一欄描述的是一塊區域在不同年代下的Google地圖資訊;2)第二欄顯示的是這個區域包含多種重復的區域;3)而且如第三欄所示,即便對於相同的區域,在不同高度(Altitude)和視角下(Yaw,Pitch,Roll)其外觀也會不同。
對於這個問題我們初期嘗試了很多當時SOTA的Matching策略,例如SuperPoint以及Superpoint系列的衍生物HLoc,最終發現都不太理想,因為這類方法都只能在局部進一步提升圖片辨識的能力, 而且泛化能力極差,在實際中壓根用不了 。因此我們經過為期一年的實驗,提出來一套廣泛適用於場景辨識的方法,iSimLoc: Visual Global Localization for Previously Unseen Environments with Simulated Images[1]。那麽這個工作裏面的核心是什麽呢,就是那個最不起眼的 場景辨識 。

我們設計了一套跟視角、環境條件無關的場景特征資訊,確保飛行器可以在不同視角、高度下精確辨識同一個地方;同時我們又設計了一套Hierarchical的Coarse-to-fine的重定位機制,使得機器人永遠不怕「找不到回家的路」。為了驗證這個系統的有效性,我們花了一年的時間做實驗,2019~2020年。終於分別在小型無人機和直升機上驗證了系統的可靠性:
來,咱們直接上實戰影片:
 https://www.zhihu.com/video/1652248911657144320
https://www.zhihu.com/video/1652248911657144320
這些效能指標剛好解決了NASA的需求,如果這個工作可以為以後人類登入出一份力,我們也就很開心啦。那麽這個專案給我的直觀感受是,SLAM很重要,場景辨識確實很重要,哈哈 。後面這個工作也發在今年的IEEE TRO上面,機器人領域的朋友大概也都了解這個期刊幹啥的,有興趣的話可以看看原文。這份工作也是我們在MetaSLAM組織下的第一份大型工作,後續也會陸續開源。
[1] P. Yin, I. Cisneros, S. Zhao, J. Zhang, H. Choset and S. Scherer, "iSimLoc: Visual Global Localization for Previously Unseen Environments With Simulated Images," in IEEE Transactions on Robotics ( T-RO ) , vol. 39, no. 3, pp. 1893-1909, June 2023, doi: 10.1109/TRO.2023.3238201.
2.2 DARPA SubT Challenge中的多機SLAM和眾包地圖 (2019~2023年)

在2019年,DARPA的地下機器人挑戰賽拉開帷幕。Darpa SubT Challenge(2019~2021) 要求在限定的時間內利用不同類別機器人最快速、最精確的辨識定位出潛在的物件(書包、手機、人員、閥門等),得分高者優勝。 熟悉DARPA的同學可能還記得,這個機構一直致力於推動機器人事業的前沿發展。如2005年的Darpa Ground Challenge,2007年的Darpa Urben Challenge,這兩項賽事開啟了美國的無人駕駛熱潮,然後這股熱浪慢慢席卷全世界,到我們面熟悉的國內公司。Darpa Robotics Challenge (2012~2015)人形機器人比賽,這項賽事也是為期三年,雖然最優以慘淡收場,但是去開啟了人形機器人、足式機器人等領域的研究先河。在此基礎上誕生了美國的Boston Dynamics和蘇黎世的Amymal Robotics等知名企業。SubT比賽的推進,也標誌者Darpa開始釘選在地下極端環境或者其他GPS-denied環境(月球、火星)下的多機協作問題。
在這次比賽中,由於沒有任何GPS或者其他第三方定位資訊,因此機器人需要透過有限帶塊的Wifi建立彼此之間的協同定位。這對於這個研究熱點,MIT,NASA,ETHZ,QUT,CMU(我們)等分別給出了非常出色的解決方案。但是在比賽中,大家基本還是在用一些偏工程的策略,比如:
- 機器人都要在同一點出發以提高彼此之間的辨識精度;
- 隨著地圖復雜度提高,一旦機器人的相對定位誤差增加,很難精確估計彼此之間的位置資訊。
以上資訊導致在實際套用的時候,就必須要求所有機器人必須同時線上。而在實際地下復雜環境或者其他極端環境中,這顯然不可能實作。我記得那是在2020年夏天,一次午後在CMU跟Ji Zhang大哥交流的時候,我們想到是否有辦法在不依賴任何第三方輔助的條件下,建立分布式的眾包地圖,其核心思想是:
A. 任何機器人可以在任何地點出發,一旦機器人之間的軌跡有重疊,此眾包地圖系統會自動解耦出相遇機器人之間的相對關系;B. 此眾包地圖系統支持所有機器人異步上線,因此地圖融合的靈活性得到保障;
C. 多個機器人在不依賴任何第三方定位系統(GPS,UWB)的前提下,實作整套地圖的全域建模,規模要大,10~120公裏,因為規模太小對於當前的SLAM沒有實際落地意義。
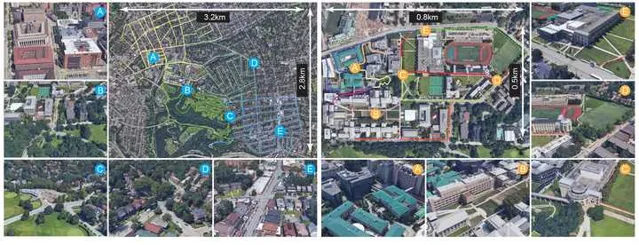
我們聊了一下午,結論是這事兒可行,幹吧。因此在當時「疫情」的大背景下,我們采集了一套名為ALITA Dataset[2] (ALITA: A Large-scale Place Recognition Dataset for Long-term Autonomy)的數據集paper,覆蓋了包括CMU校園內部和匹茲堡部份街區的120km數據,用於我們 驗證場景辨識 的能力和 眾包地圖的效果。 然後用了一年多的時間,搭建了一套可用於針對於園區、城市級別的眾包地圖系統, AutoMerge[2] (Automerge: A framework for map assembling and smoothing in city-scale environments), 他可以分布式的的完成地圖的獲取、上傳,並可以在雲端自動完成地圖的拼接整合,而跟得到地圖的先後順序無關;於此同時由於其高效的匹配特性,使得AutoMerge可以同時支持10~20個以上Agent的聯合建模。這一點對於後續多節協作的任務比較重要。
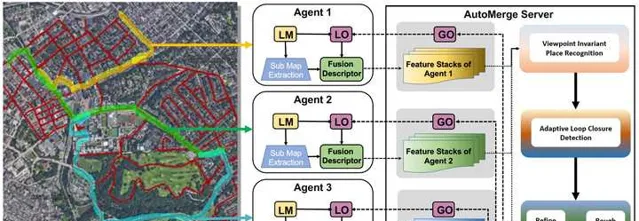
這一方法算是首次幫助多機器人系統在城市規模的大尺度環境下,不依賴任何外部的GPS等定位系統,實作多機器人之間的聯合建模、定位。這份工作讓我們意識到,真正魯棒的大型SLAM系統確實需要大量的工程最佳化,需要長時間的反復實驗(為期三年),但其中也蘊含著很多的科研潛力,而且對於現實生活中的很多問題可以提供完全新穎的思路。正如前面所提,對於地下和太空等沒有其他參考定位資訊的極端環境,AutoMerge可以輔助多機器人系統建立大範圍的相對定位資訊,方便多機器人之間復雜的任務排程等。
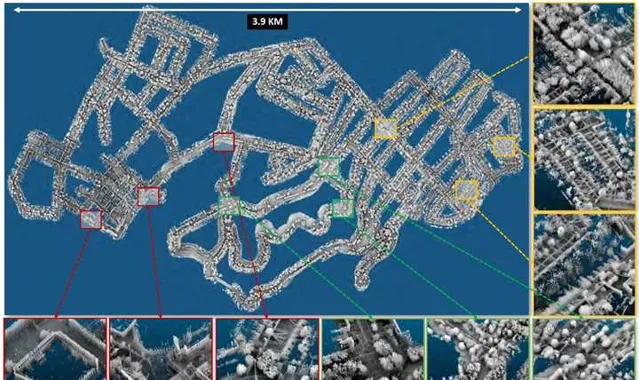
最後來兩段影片給大家感受一下眾包地圖的視覺沖擊感,以下影片是由AutoMerge為匹茲堡建立的眾包地圖效果,數據采用ALITA Dataset(只有VLP-16和IMU,無GPS),50相對獨立的機器人各自進行數據采集,最終完成整體的眾包地圖。也正因為這套方法可以支持多個機器人進行聯合建模,從而為後續的多機協作開啟了一個新的視窗。
 https://www.zhihu.com/video/1652250181218295808
https://www.zhihu.com/video/1652250181218295808
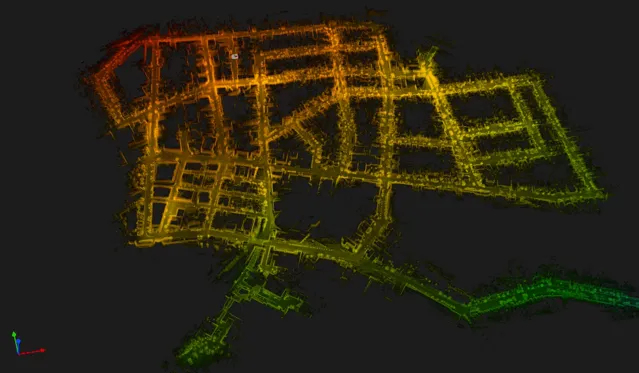 https://www.zhihu.com/video/1652242448024776704
https://www.zhihu.com/video/1652242448024776704
[2] P. Yin, S. Zhao, et al. "ALITA: A large-scale incremental dataset for long-term autonomy." International Journal of Robotics Research ( IJRR ) (2023), preprint arXiv:2205.10737.
[3] P. Yin, S. Zhao, H. Lai, R. Ge, R. Fu, I. Cisneros, J. Zhang, H. Choset and S. Scherer, "Automerge: A framework for map assembling and smoothing in city-scale environments," in IEEE Transactions on Robotics ( T-RO ) (2023) , arXiv preprint arXiv:2207.06965.
[4] S. Zhao, P. Yin, G. Yi, & S. Scherer. SphereVLAD++: Attention-Based and Signal-Enhanced Viewpoint Invariant Descriptor. IEEE Robotics and Automation Letters ( RAL ) (2022).
2.3 Lifelong 終身學習式的SLAM定位導航問題 (2021~2023年)
對於這個部份的工作,我會基於此前的這篇人工智能是不是走錯了方向?的基礎上進行整合。從2021年開始,我們在做機器人定位導航中所涉的數據量開始與日俱增。
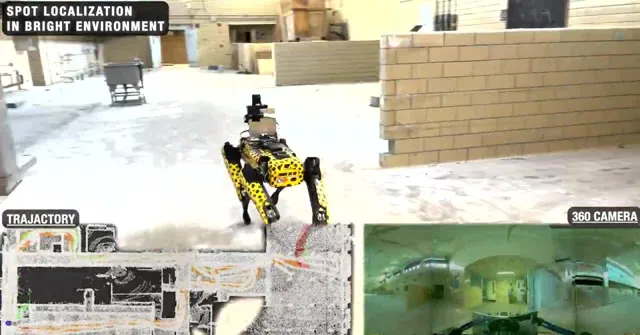 室內復雜環境中的360視覺定位
https://www.zhihu.com/video/1653377165294157824
室內復雜環境中的360視覺定位
https://www.zhihu.com/video/1653377165294157824
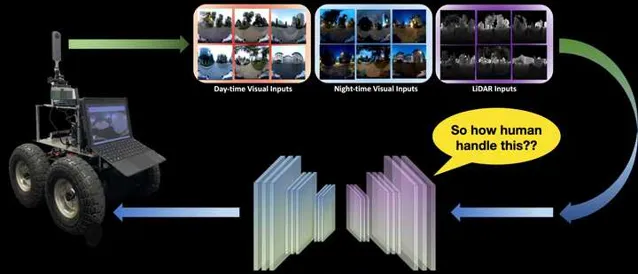
在以上影片中,當我們讓狗子嘗試在不同條件下進行定位導航任務時,狗子需要克服多種環境的幹擾,比如視角變化、光照變化、動態障礙物變化等,如果采用一般的SLAM和場景辨識方法進行重定位,那麽我們一般會采集多種環境條件下的數據對「定位模型」進行Refine,以期望提高模型的泛化能力。然而。。。這不太可能啊。大千世界萬萬千,基本是以上影片中這個簡單的場景,在不同的條件下也會有不同的模態。而對於人也好,動物也好,昆蟲也罷,這些物種卻可以相對輕松的平衡自己的日常生活中的定位能力。比如,你每天都要去學校、公司,你所穿過的街道在不同的動態障礙物環境下、光照條件下、季節條件下,都可以重新幫你辨識出自己的位置。但是 定位 這個問題對於人類來說卻不怎麽占「CPU」,我們往往可以 一邊打電話、聊天、看手機,一邊去往目的地 ,因此人的這種能力就是「 智能 」的一種體現。但是反觀現在的 機器人 - 人工智能 技術,我們往往需要高精度建模、高精度定位辨識,這些內容就能占掉一大半CPU實用率,而且環境一旦變化,之前的先驗資訊大部份都會失效。因此我們開始意識到,想實作長久的定位導航且具備比較好的泛化能力和魯棒性,就必須引入一套額外的機制, Lifelong Learning(終身學習) 。這一類方法在機器學習領域、腦科學領域研究的非常火熱,而且目前的LLMs大模型系統系統也實作了基於Transformer和Long-short-term Memory的終身學習方法,取得了ChatGPT這樣的大型成果。但是在現實生活中的機器人領域,Lifelong Learning似乎依舊停留在一些Toy Example上,或者純仿真環境中。因此如下圖中展示的真實機器人long-term定位導航中,實作切實可用的Lifelong終身學習,是我們在2021年面臨的一個核心問題。
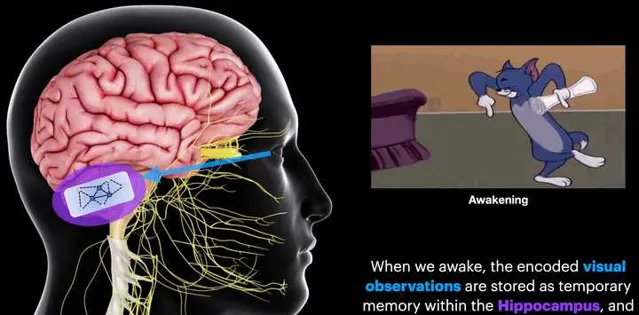
在本文最開始的地方,我們提到過:哺乳動物的大腦有一塊區域叫做 Hippocampus (這個詞後面出現的頻率會越來越多),這個區域會把 定位資訊 和 記憶資訊 耦合起來。而Hippocampus有一個很獨特的功能就是 Memory Consolidation(記憶整合)。 這一步驟其實非常關鍵,他可以幫助人從每天繁多的事情中萃取出最核心的Memory資訊,用於最佳化人的行為。因此我們經常有以下這種感受,
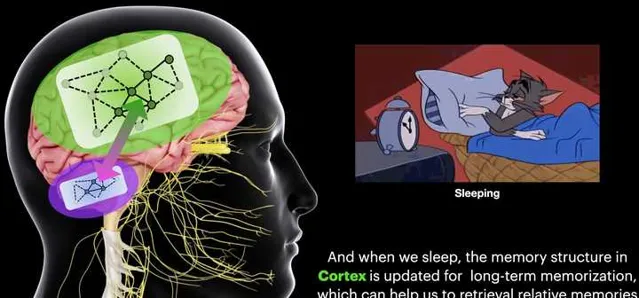
在這種「記憶反芻」的機制下,我們的記憶和學習行為可以得到持續提升(因此每天睡夠8個小時至關重要, )。也是在這種機制的牽引之下,我們設計出了專門針對於機器人Long-term定位導航的BioSLAM: A Bio-inspired Lifelong Memory System for General Place Recognition[5]。這一方法在我們此前的iSimLoc和AutoMerge基礎上,繼續為SLAM中的定位問題賦予了Lifelong 學習的能力:
- 采用了一套固定的模型系統實作了機器人在多模態環境中的定位導航問題;
- 設計了雙記憶塊機制(Long-Short-term Memory),使得BioSLAM可以 實作類似於Hippocampus的Memory Consolidation能力;
- 提供了一套Reward機制,使得本系統可以據真實環境的數據模態變化,自行決定應該如何在記憶區篩選數據,應如何根據外部獎勵強化不同模組的適應能力。
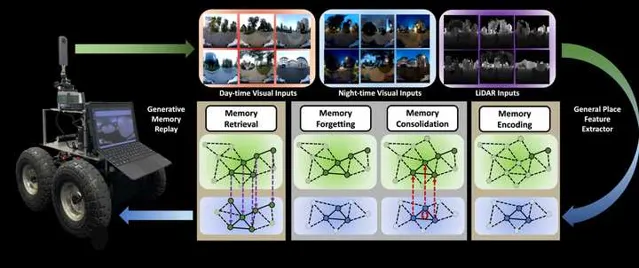
透過這套方法,我們實作了在真實復雜的城市環境、園區環境等,多模態輸入的前提下的長航程定位導航任務。下面直接上影片結果:
- 初始狀態下機器人的定位模型從未有在CMU的園區訓練過,也就是一個僅僅做了初始化的模型;
- 隨著BioSLAM自動更新機器人的Long-term Short-term記憶區,對於提高「學習」能力有價值的資訊被不斷篩選出來,同時我們也能看到保存新樣本的Reward在不斷降低;
- 隨著時間的推移,機器人的定位能力(場景辨識)也在不斷提升(軌跡的顏色所示)。
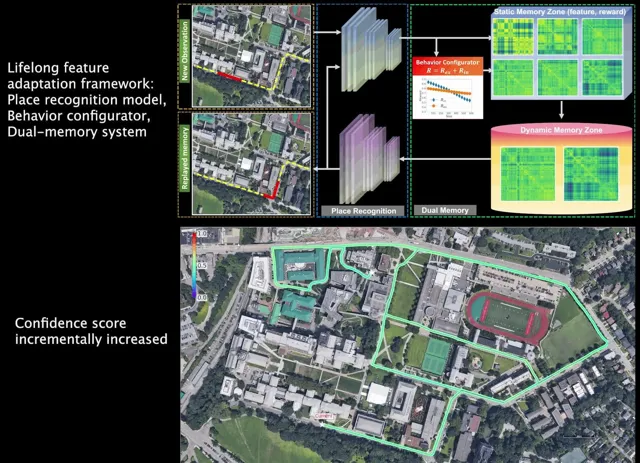 BioSLAM Performance
https://www.zhihu.com/video/1653401925335887872
BioSLAM Performance
https://www.zhihu.com/video/1653401925335887872
[5] P. Yin, A. Abuduweili, S. Zhao, etc. "BioSLAM: A Bio-inspired Lifelong Memory System for General Place Recognition." in IEEE Transactions on Robotics ( T-RO ) (2023), preprint arXiv:2208.14543 .
為了驗證這套系統的可行性,我們在2021到2022年利用已有的數據和新采集的數據做了為期一年的實驗,證明Lifelong Leanring確實可以在Long-term navigation中進一步提高 SLAM的魯棒性和泛化能力。當然,聰明的朋友們可能已經註意到,其實我們在BioSLAM裏面引入了很多類似於RL的機制,比如說Memory Replay,Reward機制(Intrinsic and Extrinsic)。在這個環節下,我們意識到,SLAM和RL之間明確的界限已經在慢慢消失了。。。關於SLAM的問題,我先寫到這裏,後面有其他有趣的工作我再更新到這個地方。
2.4 多模態機器人主動協作建模(2022~2024年)
( 2023年8月14日更 )
再開始RL之前,我再插一條我們在多機協作問題的考慮。回顧我們此前的工作,分別解決了大規模、長航程和終身學習的基本能力,但是我們發現:僅僅用單台機器人其實很難實作大規模環境的規劃決策。而且在很多情況下,單一模態機器人的套用其實非常受限,就比如一下無人機、移動機器人的例子:
(1) 如下影片所示的無人機系統,可以實作在復雜室外環境的快速探索,這一能力使得機器人系統可以迅速在超大規模環境中進行全域自主無人建模,無需人為幹預。但是無人機系統卻無法進入復雜的室內環境、地下室環境等,其安全性也是我們在實際套用中需要考慮的問題。
 在CMU RI園區的無人機自主探索
https://www.zhihu.com/video/1674449167849013248
在CMU RI園區的無人機自主探索
https://www.zhihu.com/video/1674449167849013248
(2) 與之相對的,移動機器人系統卻可以輕松進入復雜的室內外環境(當然這個工作也沒有想象的輕松,Ji Zhang大哥和Chao Cao做了3年多才有了現在絲滑的效果),目前移動機器人已經可以實作在極端復雜的室內場景進行大規模的探索工作。但是移動機器人也有短板,一個是無法看到外部建築物的高空環境資訊,同時輪式機器人也不具備在非平坦區域執行的能力。
 移動機器人在CMU RI室內外探索
https://www.zhihu.com/video/1674450906878799872
移動機器人在CMU RI室內外探索
https://www.zhihu.com/video/1674450906878799872
因此我們可以看到,單一模態機器人雖然具備某一些方面的優勢;但在真實環境中,針對大規模環境的探索+決策,單體機器人的能力就會收到諸多限制。其實這個原因也是此前Darpa Subt比賽中采用多模態機器人的原因。但是如果進行大規模的多機協作工作,機器人之間的協同定位又是一個繞不開的問題:因為 不同機器人之間的視角、光線、動態資訊都會不同 ,因此此前我們並沒有找到太多在大規模環境進行多機協作的有效演算法。不過在2022年後,我們意識到這個問題是可以解決的了,那就是采用我們此前已經開發出來的AutoMerge系統輔助機器人進行超大規模地圖協同定位,並在此基礎上進一步鞏固多機協作的能力。
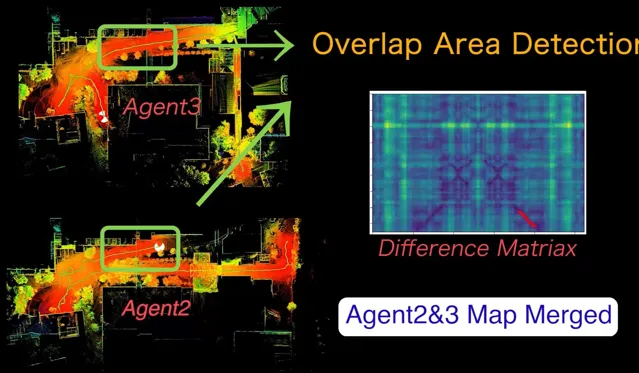 基於AutoMerge的多機協作系統
https://www.zhihu.com/video/1674453615619059712
基於AutoMerge的多機協作系統
https://www.zhihu.com/video/1674453615619059712
為了方便理解,我們可以定義任意單體機器人為「個體」,而多個「個體」構成的合集我們成為「集體」,而多機協作的目的就是「最大化集體利益」。因此在這種背景下,我們的方法具備如下優勢:
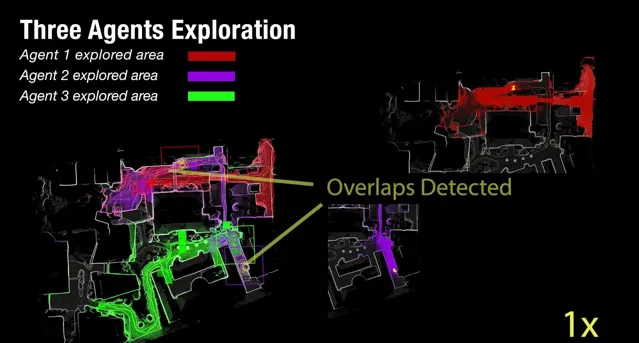 三個智能體在未知環境中的探索
https://www.zhihu.com/video/1674461743542693888
三個智能體在未知環境中的探索
https://www.zhihu.com/video/1674461743542693888
因此其實我們這個系統多少有點像蟲族的決策機制,單個個體所具備的能力雖然有限,但是作為一個集體卻可以完成很多了不起的事情,哈哈。我們聊到這裏,其實大家就會發現,SLAM已經不再單單是SLAM了,它可以向主動SLAM的方向拓展,向多機協同的方向發展,甚至向更有趣的集體智能領域拓展,似乎SLAM跟RL的關系又進了一層。

3. 我們再來說一說RL
有空再寫。。。
4. SLAM和RL在大模型時代下的結合體
有空再寫。。。











