當 下 A I 編 程 現 狀 :

AI 編程一直是人們對人工智能的一大期望,現有的 AI 編程技術雖然已經惠及了許多不會編程的普通使用者,但從上圖來看,還遠沒有達到滿足人們預期的程度,一大痛點在於:現有 AI 只會進行機械地記憶與復制貼上,難以靈活處理人們的需求。下面,我們會詳細說明現有AI編程技術的發展程度,未來發展的關鍵,以及微軟亞洲研究院在這方面所作出的努力:新型神經網絡架構 LANE(Learning Analytical Expressions),可以模擬人類的抽象化思維,從而在 AI 編程中獲得組合泛化能力。
從 AI 編程說起
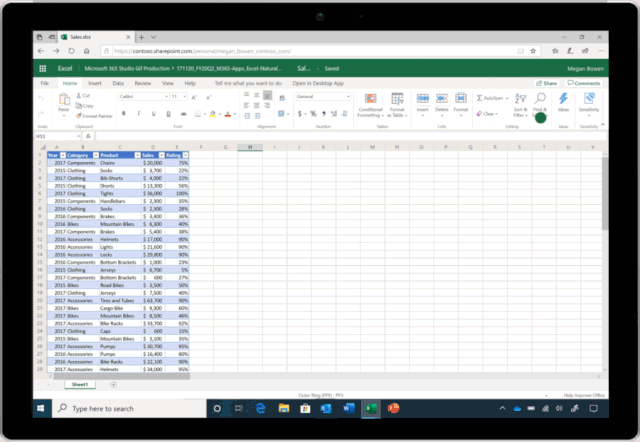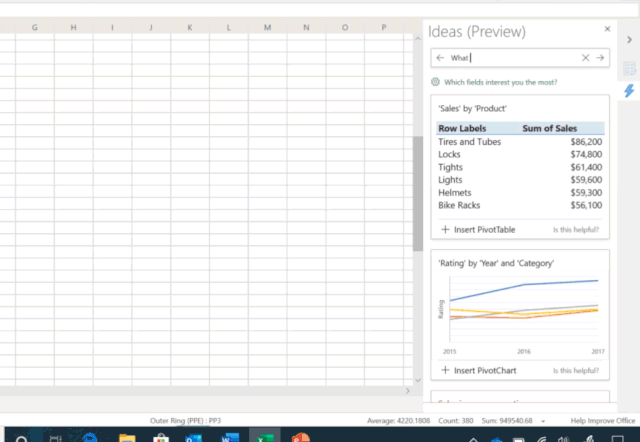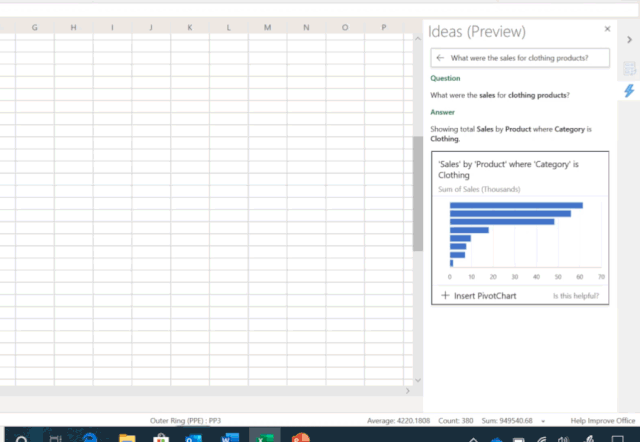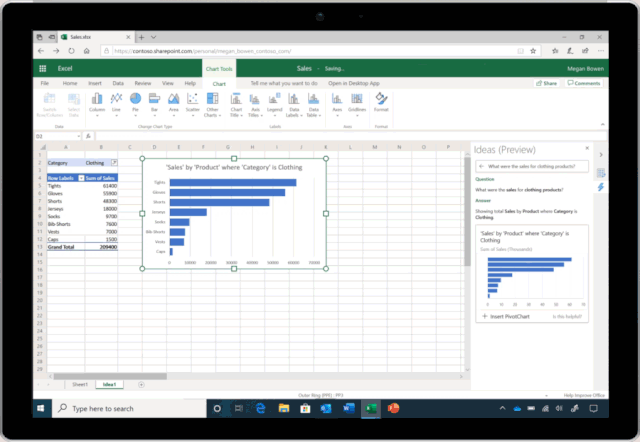
讓 AI 學會寫程式,是人們的普遍預期:直接用自然語言描述想幹什麽,AI 就能自動生成相應的程式。現有的 AI 編程技術顯然還遠達不到這種預期,但相關技術已然在各種特定領域中以更為廣泛的形式惠及了大量不會編程的普通使用者。例如,微軟在 Ignite 2019 大會上展示了Excel 中的一項新功能[1]——只需要向 Excel 提問題,它就能自動理解並進行智能數據分析,並透過視覺化圖表的方式將結果呈現在你的眼前(如圖1所示)。這個超實用功能背後的技術支撐正是一系列將自然語言轉換為數據分析程式的 AI 編程技術。而另一個例子是微軟 Semantic Machines 團隊研發的智能對話服務,其產品化方案正是基於程式合成的[2]。
本文所討論的「AI 編程技術」,指的是以一個自然語言句子作為輸入,自動生成一段相應的機器可解釋/可執行的程式作為輸出。這裏的程式通常是由一個已知的 DSL(Domain Specific Language,領域特定語言)所編寫。自然語言處理領域的研究者可能更熟悉這一任務的另一稱謂:語意解析(Semantic Parsing)。
然而,即使是在這樣的限定下,現有的 AI 編程技術也並不總能讓人滿意。一大痛點在於,它們似乎只學會了從已知的程式碼庫中進行機械地記憶與復制貼上,卻難以為人類靈活多變的需求生成真正合適的程式。
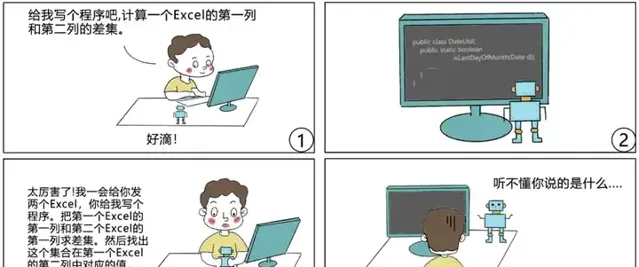
以圖2漫畫(改編自[3])為例,當使用者提出的需求相對簡單,且這個 AI 編程機器人可以在某個大程式碼庫中找到能夠實作這一需求的程式時,效果通常是不錯的。但是如果使用者提出的需求相對復雜,要求 AI 編程機器人具有一定的推理能力(所需的程式在已知程式碼庫中並不存在,需要對一些已有的程式片段進行復合生成),在這種情況下的效果通常是比較糟糕的。
本回答所介紹的研究工作正是以此為出發點,旨在探索如何讓 AI 編程機器人不再只會」復制貼上」,而是學會類人的推理能力,從而更為有效地合成所需的程式。
組合泛化能力是走向類人 AI 的關鍵
前面所討論問題的核心可以歸結為 AI 系統的「組合泛化」(Compositional Generalization)能力問題。更通俗地說,就是 AI 系統是否具備「舉一反三」的能力:能夠將已知的復雜物件(即本文中所討論的「程式」)解構為多個已知簡單物件的組合,並據此理解/生成這些已知簡單物件的未知復雜組合。
人類天生具有組合泛化能力。例如,對於一個從沒接觸過「鴨嘴獸」這個概念的人,只要看一張鴨嘴獸的照片,他就認識它了,並可以在腦海中很有畫面感地理解一些復雜句子,比如「三只鴨嘴獸抱著蛋並排坐著」、「兩只鴨嘴獸在河裏捕食完小魚之後開始上岸掘土」等。這和深度學習是很不同的,即使是為了學會「鴨嘴獸」這樣一個單獨的概念,深度學習都需要大量的標註數據,更不用說學會這個概念的各種復雜組合了。
從語言學的角度看, 人類認知的組合泛化能力主要體現在系統性(Systematicity)和生產性(Productivity)上 。系統性可以簡單理解為對已知運算式的局部置換。比方說,一個人已經理解了「鴨嘴獸」和「狗在客廳裏」,那麽他一定能夠理解「鴨嘴獸在客廳裏」。生產性則可以簡單理解為透過一些潛在的普適規律,用相對簡單的運算式構造出更復雜的運算式。比方說,一個人已經理解了「鴨嘴獸」和「狗在客廳裏」,那麽他一定能夠理解「鴨嘴獸和狗在客廳裏」。
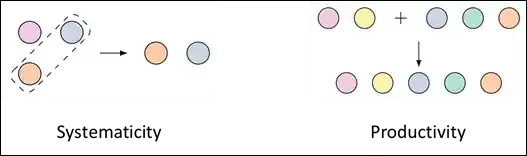
正如語言學家、哲學家喬姆斯基所說,「有限資源,作無窮運用(infinite use of finite means) 」。正是依靠組合泛化能力,人類智能才能夠從一些最基礎的元素出發,一步一步創造出復雜甚至無限的語意世界。可以說, 組合泛化是類人智能體必須具備的基本能力 。
深度學習缺乏組合泛化能力
程式是具有組合性的,即使是一個很小的 DSL(領域很限定,語法很簡單,預定義的函數很有限),也能夠產生一個指數爆炸式的巨大程式空間。任何一個訓練數據集中所包含的程式,都只是這個指數級程式空間中的冰山一角。因此,若一個 AI 編程機器人缺乏組合泛化能力,則必然會導致如前面漫畫所體現的「人工智障」情況。
從這個角度出發,越來越多的研究工作開始重新審視現有的基於深度學習的 AI 編程解決方案。當前主流的解決方案大多基於深度編解碼架構(Neural Encoder-Decoder Architectures)。紐約大學教授 Brenden Lake 和 Facebook AI 科學家 Marco Baroni 的一系列研究表明,現有的深度學習模型並不具有組合泛化能力[4]。圖4簡單展示了他們的研究方法。實驗任務是將諸如「run after walk」這樣的自然語言句子轉譯成諸如「WALK RUN」這樣的指令序列(程式)。

表面上看,這是個非常簡單的序列到序列生成任務。在收集到大量自然語言句子以及它們所對應的指令序列之後,隨機劃分成訓練集和測試集,用現有的深度學習模型進行訓練,即可在測試集上達到99.8%的準確率。然而,一旦從組合性的角度對訓練集和測試集的劃分方式加以約束,深度學習模型就不再有效。例如,為了驗證模型的系統性,可以讓模型在訓練階段除了「jump -> JUMP」之外不再接觸任何與 jump 有關的樣例,而在測試階段去看模型是否能夠在包含 jump 的句子(例如:「jump around left」)上做對。實驗結果表明,在這樣的設定下,深度學習模型僅能達到1.2%的準確率。
另一方面,為了驗證模型的生產性,則可以讓模型在訓練階段只接觸指令序列長度小於24的樣例,而在測試階段去看模型是否能夠正確地生成長度不小於24的指令序列。實驗結果表明,在這樣的設定下,深度編解碼網絡僅能達到20.8%的準確率。諸如此類的一系列研究表明,現有的深度學習模型在語意解析任務上不具備組合泛化能力[4][5]。
在當前的工業實踐中,從業者主要透過深度學習與人工規則的混合系統來緩解這一瓶頸(數據增廣也可以歸入其中,因為需要增廣哪些數據通常也需要人工歸納)。本文想要探討一種更有趣的思路:是否能夠在深度學習中引入合適的歸納偏置,使之擺脫簡單的記憶與模仿,也不需要引入人工規則,而是自動地探索、發現並歸納出數據集中內在的組合性規律,從而使端到端的深度神經網絡具備組合泛化能力。
在深度神經網絡中模擬人腦的抽象化思維
人類的認知之所以具備組合泛化能力,關鍵在於抽象化(Abstraction),即省略事物的具體細節,以減少其中所含的資訊量,從而更有利於發現事物間的共性(規律)。
這種抽象化能力是一種代數能力,而這正是現有的深度神經網絡所缺乏的。如圖5左側所示,對於 AI 編程任務,現有的深度神經網絡更傾向於「死記硬背」:自然語言和程式語言被看作是兩個集合,那麽學習到的只能是具體的自然語言句子和具體的程式之間的簡單對映關系,這樣自然是難以做到組合泛化的。對於這一問題,關鍵思路在於,將自然語言和程式語言看作是兩個代數結構,且需要 讓深度神經網絡傾向於學習這兩個代數結構之間的同態 (如圖5右側所示)。

更形象地來說,如果訓練數據中已經包含「run opposite walk」、「run after left」、 「walk twice」等樣例,現在面對如下樣例:
INPUT: 「run opposite left after walk twice」
OUTPUT: 「WALK WALK LTURN LTURN RUN」
深度學習模型的實質是記住諸如此類輸入輸出對之間的對映關系,而人類的認知則傾向於做出如圖6所示的抽象化:
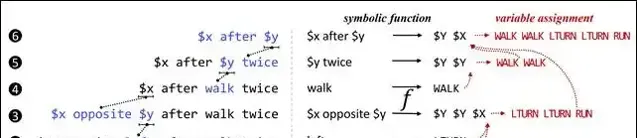
圖6的左側自下而上地給出了對於作為輸入的自然語言句子的抽象化過程。在第1、2、4步,分別剝離掉「run」、「left」和「walk」這三個單詞的具體內容,將它們抽象為變量;在第3、5、6步,分別剝離掉「$x opposite $y」、「$y twice」和「$x after $y」這三個子句內容,也將它們抽象為變量。人類記住的並非輸入與輸出之間的直接對映,而是這一抽象化過程中每一步所產生的局部對映(如圖6右側所示)的集合。例如,在第1步中,將單詞「run」對映到了程式「RUN」上;在第3步中,將抽象子句「$x opposite $y」對映到了程式「$Y $Y $X」。此處的「$X」是一個程式中的變量,指代自然語言中的變量「$x」所對應的程式;同樣地,$Y$亦是一個程式中的變量,指代自然語言中的變量「$y」所對應的程式。
上述例子說明了,相比於直接記住相對復雜的具體對映,人類更傾向於從中歸納出相對簡單的共性抽象對映,從而獲得組合泛化能力。因此,為了讓深度學習也獲得組合泛化能力,需要設計一種能夠模擬人類認知中的抽象化過程的新型神經網絡架構。
將輸入/輸出的各個具體物件形式化,稱為源域運算式(Source Expression, SrcExp)/目標域運算式(Destination Expression, DstExp),統稱為運算式(Expression, Exp)。若運算式中的某個/某些子部份被替換為變量,則稱這些帶變量的運算式為解析運算式(Analytical Expression, AE)。同樣地,解析運算式也可分為源域解析運算式(SrcAE)和目標域解析運算式(DstAE)。
對於每個輸入的 SrcExp,神經網絡架構需要透過若幹次抽象化操作逐漸地將其轉換為更簡單的 SrcAE(如圖6左側所示)。在這一抽象化過程中,每個被置換為變量的 SrcAE 將被解析為一個 DstAE,最終由這些 DstAE 組合形成一個 DstExp 作為輸出(如圖6右側所示)。模型需要以這種抽象化過程作為一種歸納偏置,在不依賴任何人工預定義的抽象/對映規則的前提下,完全自動化地完成對具體的抽象化過程與運算式對映的探索與學習。
LANE 的模型實作
新型的神經網絡架構 LANE(Learning Analytical Expressions)能夠在語意解析任務中模擬人類的抽象化思維,從而獲得組合泛化能力 。在之前的神經網絡學習框架中,神經網絡是直接被用來學習一個從具體的源字串(Source Token Sequence)到具體的目標串(Destination Token Sequence)的對映函數。而在 LANE 中,需要學習的是一個定義域和值域分別是由源字串抽象化後匯出的解析運算式和目標串解析運算式的函數。
LANE 由兩個神經網絡模組構成:一個模組稱為 Composer,由一個 TreeLSTM 模型實作,負責對輸入的 SrcExp 進行隱式樹狀歸納(Latent Tree Induction),從而得到逐漸抽象簡化的中間 SrcAE;另一個模組稱為 Solver,負責在每次抽象發生時進行局部語意解析,將語意細節剝離並保留在記憶單元(Memory)中,從而使得後續處理過程中這些細節被簡化為一個變量。
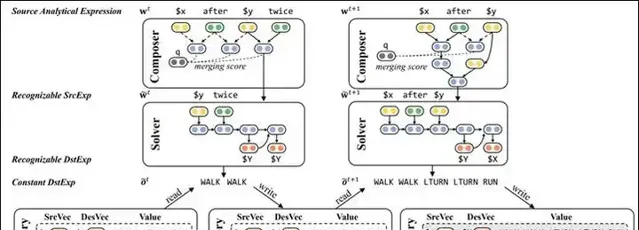
圖7解釋了 LANE 的工作流程,也展示了 LANE 如何處理圖6中的第5步和第6步抽象。在第5步抽象化過程中,對於當前的 SrcAE 「$x after $y twice」,Composer 基於樹狀 LSTM 輸出下一步抽象動作:應該對「$y twice」這個局部進行抽象化。Solver 則使用一個深度編解碼網絡將「$y twice」解釋為 DstAE 「$Y $Y」,與原 Memory 中的「$Y = WALK」結合得到新變量所對應的 DstExp 「WALK WALK」,並以此更新 Memory。經過這一過程,「$x after $y twice」中的「$y twice」這部份細節被剝離掉了,形成了一個抽象程度更高的 SrcAE 「$x after $y」,進而可以開始第6步抽象。透過這樣的方式,Composer 與 Solver 協同工作,LANE 將輸入的 SrcExp 逐漸抽象為簡化程度越來越高的 SrcAE,直到形成一個由單變量構成的最簡 SrcAE。該變量在 Memory 中對應的取值即為最終輸出的 DstExp。
由於 LANE 中包含不可求導的離散操作,因此可以基於強化學習(Reinforcement Learning)來實作模型的訓練。模型訓練有如下三個關鍵點:
1. 獎勵(Reward)設計 。Reward 分為兩部份:一部份是基於相似度的獎勵,即模型生成的 DstExp 與真實的 DstExp 之間的序列相似度;另一部份是基於簡潔度的獎勵,它是受奧卡姆剃刀原則啟發,用於鼓勵模型生成更通用/簡潔的解析運算式。由於這兩個獎勵的設計都沒有刻意引入任務相關的特別知識,表明 LANE 應該具有很大的普適性。
2. 分層強化學習(Hierarchical Reinforcement Learning)。Composer 和 Solver 協同工作,但地位並不相同:Solver 的決策依賴於 Composer 的決策。因此,將 Composer 和 Solver 分別視作高層代理(High-level Agent)和底層代理(Low-level Agent),套用分層強化學習聯合訓練這兩個模組。
3. 課程學習(Curriculum Learning)。為了加強探索效率,根據 SrcExp 的長度將數據劃分為從易到難的多個課程。模型先在最簡單的課程上進行訓練,而後逐漸將更難的課程加入訓練。
實驗結果
Lake 等人建立了一套基準數據集 SCAN,用於評測語意解析系統的組合泛化能力[4]。該數據集上衍生出了多個子任務,用於度量不同方面的組合泛化能力。例如,ADD_JUMP 子任務用於度量模型是否能夠處理新引入元素的組合;LENGTH 子任務用於度量模型是否能夠生成超出訓練數據中已知長度的組合。研究實驗結果表明,LANE 在這些子任務上均達到了100%的準確度。
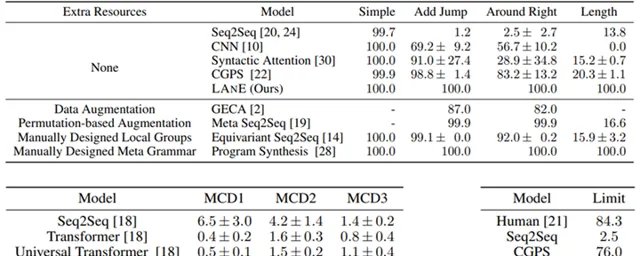
圖9展示了 LANE 中的 Composer (TreeLSTM)學習得到的兩個隱式樹結構作為範例。TreeLSTM 在具體實作時是二叉化的,將具體進行抽象動作的結點著黑色。可以看到,即使並未引入任意人工預定義的抽象/對映規則,LANE 也能夠自動化地探索出符合人類思維的抽象化過程。

新型的端到端神經網絡架構 LANE 能夠模擬人類的抽象化思維能力,以此學習到數據中潛在的解析運算式對映,從而在 AI 編程(語意解析)任務中獲得組合泛化能力。微軟亞洲研究院的研究員們希望以此作為一個出發點,探討深度學習如何由 「鸚鵡範式」(記憶與模仿)走向「烏鴉範式」(探索與歸納),從而延伸其能力邊界。不過目前這還是初步的理論研究,想要套用到更復雜的任務中還需要很多後續工作(例如,提高訓練效率、提高容錯學習能力、與無監督方法結合等)。
論文:https:// arxiv.org/abs/2006.1062 7
程式碼:https:// github.com/microsoft/Co ntextualSP
參考文獻
[1] 【智能數據分析技術,解鎖Excel「對話」新功能】<https://www. msra.cn/zh-cn/news/feat ures/conversational-data-analysis >[2] 【對話即數據流:智能對話的新方法】<https://www. msra.cn/zh-cn/news/feat ures/dialogue-as-dataflow >
[3] 【朋友送了我一個會編程的機器人,說程式設計師可以下崗了!!!】<http:// dwz.date/dgNY >
[4] Brenden Lake, Marco Baroni. Generalization without Systematicity: On the Compositional Skills of Sequence-to-Sequence Recurrent Networks. 2018. <https:// arxiv.org/abs/1711.0035 0 >.
[5] Daniel Keysers, et al. Measuring Compositional Generalization: A Comprehensive Method on Realistic Data. 2019. <https:// arxiv.org/abs/1912.0971 3 >
本賬號為微軟亞洲研究院的官方知乎賬號。本賬號立足於電腦領域,特別是人工智能相關的前沿研究,旨在為人工智能的相關研究提供範例,從專業的角度促進公眾對人工智能的理解,並為研究人員提供討論和參與的開放平台,從而共建電腦領域的未來。
微軟亞洲研究院的每一位專家都是我們的智囊團,你在這個賬號可以閱讀到來自電腦科學領域各個不同方向的專家們的見解。請大家不要吝惜手裏的「邀請」,讓我們在分享中共同進步。
也歡迎大家關註我們的微博和微信 (ID:MSRAsia) 賬號,了解更多我們的研究。











