很多小公司或者小團隊,都透過excel或者口頭來溝通需求變更或者bug修改。帶來的效果,就是大家都覺管理很亂,但是好像又沒有誰能指出問題的根源。
本文介紹一下透過一些問題單的要素資訊,可以分析出哪些芯片開發過程中的質素問題或者風險。
透過遞進式的展示不通的問題單資訊匯總,來由淺入深的展示問題單對於芯片研發質素的作用。
1、狂野型的統計方式
先來看一下最簡單的問題單統計結果——只統計問題模組和問題數量。
我們以一組問題單數據統計範例展開聊聊,只統計這些資訊夠用不?
| 問題模組 | 問題數量 |
|---|---|
| 模組A | 12 |
| 模組B | 23 |
| 模組C | 23 |
專案復盤時,只能知道模組發現了多少問題。但是,這全是開發的問題嗎?設計人員首先回一個表情:我不信。

2、增加問題單發現的領域
把問題單按照送出的領域劃分,從中可以看出,驗證和設計各自的貢獻情況。
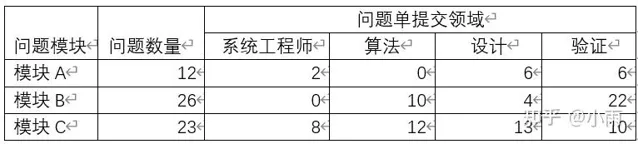
模組C的設計人員一騎絕塵,居然發現的問題比驗證都多。是不是驗證可以靠邊站了。哈哈。那麽,我們給問題單再增加一些維度,再來深挖一下這個現象的真相。
某個模組驗證送出的問題多,往往此模組收斂周期比較長,會成為專案交付的關鍵路徑——拖延專案的交付周期。
3、增加問題來源的分類
| 問題模組 | 問題數量 | 需求變更 | 演算法錯誤 | 演算法最佳化 | 設計最佳化 | 設計缺陷 |
|---|---|---|---|---|---|---|
| 模組A | 12 | 2 | 0 | 0 | 2 | 8 |
| 模組B | 23 | 0 | 8 | 2 | 4 | 9 |
| 模組C | 23 | 8 | 4 | 8 | 1 | 2 |
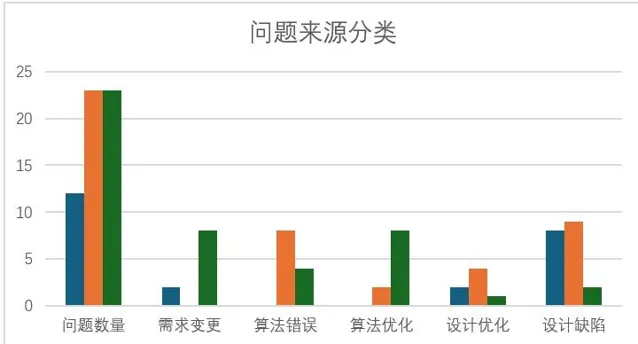
問題單來源的主因:
- 模組A是RTL缺陷。
- 模組B是演算法錯誤和RTL缺陷。
- 模組C是需求和演算法最佳化。
我們可以分析出一些初步的結論:
- 模組B和C,雖然問題單一樣多,但是B設計人員的出錯率較高。
- B模組的演算法不夠穩定,影響了整體收斂速度。
- C模組的需求不穩定,影響了驗證收斂速度。通常情況下,驗證過程中需求問題,帶來的影響比較大。這裏演算法的最佳化問題單,通常很大程度上是因為需求修改引入演算法變更,演算法需要一定時間的理解消化和測試。
- 模組雖然有需求變更,可能是小修改,需求也比較明確。
4、細化缺陷類別
問題單,還可以繼續細化問題類別。以設計方面的為例(設計表示很怨),還可以做如下細分:
- 設計方案錯誤
- 設計功能實作錯誤
- 連線錯誤
- 筆誤
有了這些維度,可以更加全面的看到設計人員在哪些方面出現問題比較多。後續的質素活動更加有針對性——發現問題多的地方,是否還存在盲點?歷代專案問題多的地方,但是發現問題少,是否驗證不夠充分?
5、從時間維度看問題單
透過復盤問題單爆發的時間過程,可以看到問題收斂耗時的主因。可以為下次專案提供借鑒意義。
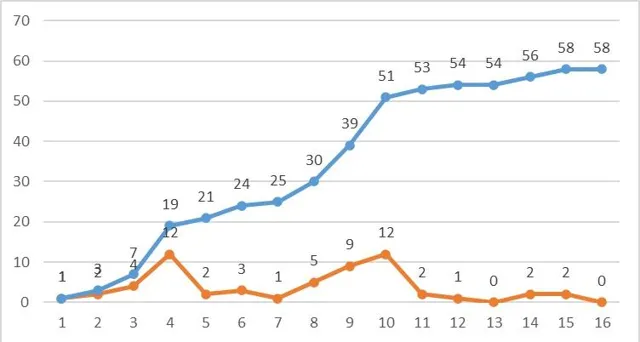
可以看到第4周和第10周分別達到了問題單兩個峰值。
通常情況下,第4周出現峰值,都是因為初步測試典型配置;後面還會有一個小高峰。但是第二個高峰基本上和第一個持平,這個也有異常。
因為案例中後期,需求變更比較多,對問題單也有貢獻,對應的專案收斂周期拉長。這樣來看,第二個高峰也比較合理了。專案收斂後面的小拖尾,很可能和需求變更有一點的關系。
6、不同專案的問題單分析
對於叠代開發的專案,問題單的借鑒意義會更大一些。
相同的人力、周期、需求和程式碼修改,問題單的增加和收斂曲線,往往也是相似。這也可以從另一個側面來說明,制定的交付計劃是否可行。
7、結束語
上述案例中的數據雖然比較粗糙,但是能有一定的代表性。問題單的數據分析,是客觀的,一定程度上減少了主觀因素。

透過設計合理的問題單資訊,可以有效幫助專案復盤,從而改善下一次專案的質素管理。也能辨識到團隊自身存在的問題和長處。











