作為文學作品,很難做到滴水不漏。但總體設定有據可循。透過將三維歐氏空間下的已有規律進行擴充套件,並增加一些假設,我們能夠對四維歐氏空間的簡單場景進行渲染。這個回答將實作這部份工作。
首先來回顧一下【三體III 死神永生】中對四維視角下場景的描寫:
此時,莫沃維奇和關一帆的眼前,「藍色空間」號飛船像一幅宏偉的巨畫舒展開來。他們可以一直看到艦尾,也可以一直看到艦首。他們能夠看到每一個艙室的內部,也能夠看到艙中每一個封閉容器的內部;可以看到液體在錯綜復雜的管道中流動,看到艦尾核反應堆中核聚變的火球……當然,透視原理仍然起作用,太遠就看不清楚,但一切都能看到。沒有這種經歷的人在聽他們描述時會產生一個錯誤的印象,感覺他們是「透過」艦體看到所有的一切,事實是他們沒有「透過」什麽,一切的一切都並列在外,就像我們看一張紙上畫的圓圈,能看到圓圈內部,並沒有「透過」什麽。這種展開是所有層次上的,最難以描述的是固體的展開,竟然能夠看到固體的內部,比如艙壁或一塊金屬、一塊石頭,能看到它們所有的斷面!他們被視覺資訊的海洋淹沒了,仿佛整個宇宙的所有細節全聚集在周圍色彩斑斕地並列呈現出來。這時,他們不得不面對一個全新的視覺現象:無限細節。
因為最近有接觸光線追蹤相關的專案,之前又有機器人學相關背景。當時看到這個章節,就打算試著把四維視角下的場景用光線追蹤渲染出來試試。因為三維歐氏空間(Euclidean Space)的剛體運動在機器人學中已經有非常成熟的表述,剛體位姿(Pose)可以分解為位置(Position)和姿態(Orientation)。透過對三維位姿的擴充套件,應該不難模擬剛體在四維歐氏空間中的運動。而渲染出四維空間中的影像,需要借助電腦圖形學的方法。現在流行的光線追蹤(Ray Tracing)技術遵照物理學規律對光線在空間中的傳播進行模擬,然後對場景的影像進行渲染。而且相比光柵化的方法(Rasterization)實作簡單,經過簡單地修改也不難推廣到四維歐氏空間。
預備知識:光線追蹤(Ray Tracing)
光線追蹤最基本的思想是逆向的模擬光線傳播的過程。虛擬的光線從相機出發,由電腦檢測射線和場景內物體的碰撞。按照碰撞物件的材質、顏色等紋理資訊,對光線進行折射、反射以及衰減。由於一副圖片上的每一個像素都對應著至少一束光線,而且光線需要多次反射才能達到較好的渲染效果,因此光線追蹤的運算量巨大,往往難以用於即時渲染。github上有一個非常經典的光線追蹤教程:一個周末實作光線追蹤(Ray Tracing in One Weekend) [1] 。我在原作者的基礎上做了一些修改,引入了一些基本的第三方庫,使得這個精簡版CPU光線追蹤引擎能夠渲染一些帶紋理的三角形網格(Triangle Mesh)模型。用貝茲曲線簡單地拉了一個「水滴」的輪廓,測試了下渲染結果:

完善了三維光線追蹤引擎的基本功能後,接下來就是考慮如果把維度從三維擴充套件至四維。
四維相機與三維「視網體」
在擴充套件四維視覺前,有必要對三維世界的針孔相機(Pinhole Camera)模型進行簡單地介紹。人類能透過二維的視網膜感受到三維的世界,能透過相機將三維世界的美好瞬間記錄在二維的像素平面內,都借助了針孔相機模型。眼睛的晶狀體或者相機的鏡片組將三維世界的光線投射在二維的成像平面上,損失了一個軸的資訊。
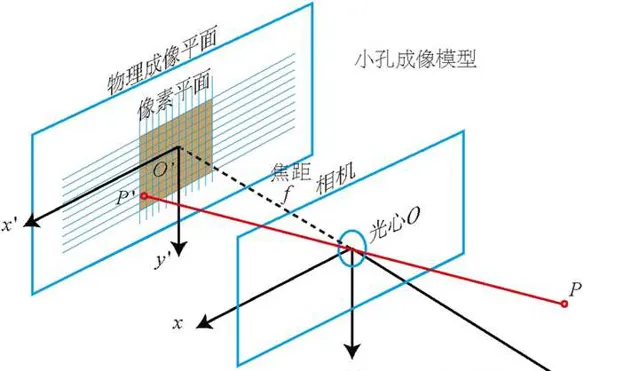
在數學上,針孔相機模型可以表述為:
\left[ \begin{matrix} f_x & 0 & c_x \\ 0 & f_y & c_y \\ 0 & 0 & 1\\ \end{matrix} \right] \left[ \begin{matrix} \frac{x}{z} \\ \frac{y}{z} \\ 1\\ \end{matrix} \right] = \left[ \begin{matrix} u \\ v \\ 1\\ \end{matrix} \right] \tag{2-1}
其中 f 為相機的焦距, c 為相機的光芯。 x,y,z 為點在三維相機座標系下的座標, u,v 為點在像二維素平面內的像素座標。那麽如果存在四維相機的,它的針孔相機模型就應該是:
\left[ \begin{matrix} f_0 & 0 & 0 & c_0 \\ 0 & f_1 & 0 & c_1 \\ 0 & 0 & f_2 & c_2 \\ 0 & 0 & 0 & 1\\ \end{matrix} \right] \left[ \begin{matrix} \frac{p_0}{p_3} \\ \frac{p_1}{p_3} \\ \frac{p_2}{p_3} \\ 1\\ \end{matrix} \right] = \left[ \begin{matrix} u \\ v \\ w \\ 1\\ \end{matrix} \right] \tag{2-2}
這裏 p_0, p_1, p_2, p_3 來表示點在各個軸下的座標,u,v,w 表示像素座標。這裏我們很快註意到,像素平面是三維的,而人的視網膜是二維的。如果我們直接將三維的像素資訊,都往 w = 0 的平面上疊加,從而得到一個二維影像。那麽這個影像將是「重疊」的,將是文中所說的「透視」,將不再有 無限細節 。因此,對於地球文明的人類為何能借助二維的視網膜感受到四維世界的影像,這裏給出一種解釋:
地球文明原來是一個四維空間中的文明,在和邊緣文明的戰爭中主動或被動地接受了降維打擊。地球文明將自己壓縮至三維空間下生存。但地球上人類仍然保留著第四個維度上的厚度(可能是一個較小的值,比如0.1mm)。因此地球人眼球是一個四維橢球,內部有一個三維的視網體,能夠感知三維像素資訊。由於我們生活的三維世界的光線沒有第四個維度的分量,因此只有當人類進入四維碎塊時,才會第一次感受到四維視覺。因此,針孔相機模型(2-2)的「升維」完成。在C++實作時,直接將相機模型封裝為帶維度參數的類,見camera.h。為驗證實作的正確性,將虛擬世界 降維打擊 至二維,在視野中防止四個二維的圓形,用線性相機拍攝可得一維影像:

再將虛擬世界 升維 至四維,在視野中放置一個四維球體和一個四維超立方體框架,用四維相機拍攝可得三維影像:

四維空間的相機所拍攝的照片,分辨率是三維的。遺憾地是作為三維世界的生物,我們的顯視器都是二維的,因此我只能把第三個維度放在時間軸上。本文使用gif格式的圖片來展示四維相機所拍攝的照片。
可以看到四維的球體在三維世界的投影是一連串大小均勻變化的三維球體,而且我們 不能看到球體內部結構 。而四維的超立方體,其實是兩個三維立方體,然後把它們各自8個頂點連線。正如三維世界的立方體是兩個正方形,然後把它們各自4個頂點連線。
四維剛體運動學
三維歐氏空間的大部份向量運算,如向量加法、內積等,都能透過直接增加向量維度來擴充套件至四維。三維向量叉積(Cross Product)無法直接擴充套件,卻又是剛體運動學中非常重要的一種運算。比如速度與半徑的叉積就是角速度。此外,剛體的旋轉變換(Rotation Transformation)在三維空間下有多種參數化方法,對於正交矩陣的參數化方法,可以簡單地擴充至四維,但是四元數(Quaternion)*、軸角法(Axis-angle)等更精簡的參數化方式卻無法擴充套件。
按照維基百科對四維旋轉的描述可以發現,向量叉積和軸角法的不適用源自於同一個問題:
在四維空間下,一個二維平面的正交補餘空間(Orthorgonal Complement Space)是二維的。即一個二維平面有無數個不平行的單位法向量。再究其本質,旋轉或者角速度這樣的物理量,只能在三維空間下與單一向量保持對映關系。在高於三維的空間中,借用Clifford代數 [2] 的概念,表示為雙向量(Bivector)。因此,本文使用四維正交矩陣來描述剛體的旋轉。而使用「旋轉平面-旋轉角」的參數化方式來生成一些基礎的旋轉。
\huge R = (I - 2vv^\top)(I - 2uu^\top) \tag{3-1}
其中 R 為繞平面 A 旋轉 \theta 弧度的旋轉矩陣,向量 u,v 為平面 A 內,夾角互成 \frac{\theta}{2} 的兩個單位向量 [3] 。公式(3-1)的另一種解釋是:兩個反射變換(Householder Transformation)構成一個旋轉變換。
* 其實四元數能擴充套件到四維旋轉。但是相比之下雙向量(Bivector)能應對更高維的旋轉。
四維視角下的三維封閉容器
在完成了針孔相機模型和剛體運動學的「升維」後,便可以利用這兩個規則解答一個問題: 在四維視角下,觀察者為何能夠在不破壞容器的情況下得到三維封閉容器的內部資訊 。我們可以在四維空間中建立一些簡單的幾何形狀,或者匯入一些常見的三維模型。透過剛體變換改變這些物件的姿態後,再用四維的相機拍攝下物件的「照片」。
首先把一只小黃鴨放入一個開口的容器:

蓋上蓋子後,理所當然地,觀察者無法觀察到容器中的任何資訊:

下面使用分辨率為640x480x64的四維相機進行拍攝。


需要註意的是,雖然四維照片是一個動圖,但所有幀都是在同一時刻被記錄下的。所以整個影像沒有任何物件在運動。為了模擬真實的四維視覺,三維世界的讀者可以記憶下動圖的每幀內容,然後閉上眼睛,讓每一幀在大腦中同時出現,或鋪展開來。
可以看到四維視角下的三維物體均薄如一張平面(其實是我在程式中給定了一個非常小的厚度,否則光線追蹤演算法無法判斷光線與物體相交)。但是物體的每一個斷層都清晰可見。由於小黃鴨的內部是均勻材料,所以相比書中藍色空間號的四維視角下的影像,資訊更少。
小結
透過簡單地仿真可以看到,三維封閉容器的內部資訊在四維視角下暴露無遺。上文的場景,相機第三軸的分辨率僅為64像素,且模型物件材料單一。如果能突破這兩個限制,則可以渲染出書中所說的 無限細節 。本文所使用的程式碼放在github上,歡迎有興趣的讀者深入討論!
一些書中場景的補充:
擊落水滴

—— 褚巖
魔戒(墓地)
[開發中……]
這是人類第一次近距離看到四維物體,與高維空間感相似,他們感受到了被稱為高維質感的宏偉。「魔戒」是全封閉的,看不到內部,但能感覺到一種巨大的縱深感和包容性。在來自三維世界的眼光中,所看到的「魔戒」不是一個「魔戒」,而是無數個「魔戒」的疊加,這種四維質感攝人心魄,是真正的納須彌於芥子的境界。參考
- ^ Ray Tracing in One Weekend https://raytracing.github.io
- ^ Clifford Algebra, wikipedia https://en.wikipedia.org/wiki/Clifford_algebra
- ^ Two Reflections is a Rotation https://www.youtube.com/watch?v=Hy2gbdbrJZ8&list=PLpzmRsG7u_gqaTo_vEseQ7U8KFvtiJY4K&index=5











