Lechner, M., Hasani, R., Amini, A. et al. Neural circuit policies enabling auditable autonomy. Nat Mach Intell 2, 642–652 (2020). https:// doi.org/10.1038/s42256- 020-00237-3
pdf: https:// publik.tuwien.ac.at/fil es/publik_292280.pdf
code: https:// github.com/mlecp6l/ker as-ncp
文章概括
文章作者致力於構建一種腦啟發的人工智能代理能夠透過相機的輸入來完成自動駕駛。現在端到端的機器學習並沒有充分的準確性以及可解釋性,這也就帶來了對端到端演算法的安全性的考慮。
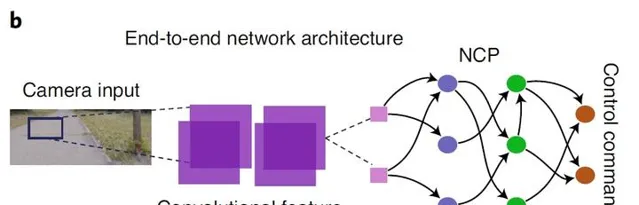
作者團隊驚奇的發現像 Caenorhabditis elegans 等少細胞動物,可以透過近乎最佳的神經系統結構來完成執行運動、控制運動以及導航等行為。作者提出了 Neural circuit policies (NCP)透過將摺積提取到的32個特征透過253個突觸與19個神經元相連線,並將提取到的特征轉化為智能體的決策。
自動駕駛任務
文中理想的自動駕駛需要滿足以下幾個條件:
- 學習到觀察到的駕駛場景和它們相應的最佳轉向指令(智能體的特定任務)之間真正的因果結構
- 在現實環境中可以得到與虛擬環境中相同的效果
- 對於車道保持任務,智能體可以關註在道路的horizon
端到端的自動駕駛
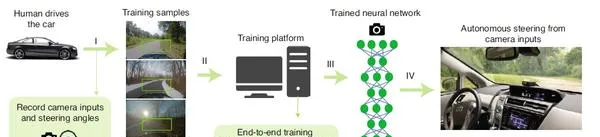
端到端的自動駕駛任務中沒有關註 temporal 特性,並過濾掉了真實情況下雜訊的幹擾。在短時的陽光的幹擾下,基於視覺的自動駕駛是不可靠的。
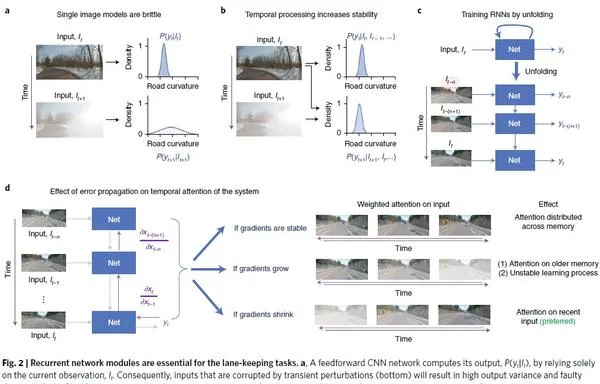
基於 RNN 訓練的端到端的自動駕駛,會訓練出更可靠的智能體(Fig2.a -> Fig2.b)。然而,人在駕駛的過程中不會回憶前幾秒的道路的影像,這也是和基於LSTM 的RNN 相違背的。LSTM 會建立當前時刻與前幾秒時刻的 long-term dependents,這與任務與影像之間的關系並不相符。
The development of a single, task-specific algorithm that universally satisfies the representation-learning challenges described above has been a central goal of artificial intelligence。Neural Circuit Policies (神經回路策略)
作者希望能夠在 the neural computations 中汲取靈感,並建立了 NCPs。
線蟲的神經機制
多種生物的神經回路,包括線蟲的神經回路都是由四層網絡拓撲結構組成的。線蟲將從傳感器得到的輸入,傳遞給中間神經元以及 command 神經元,並生成決策。最後決策會控制肌肉的運動。線蟲的神經網絡結構較為簡單,線蟲神經網絡的探究曾經登上了Nature。
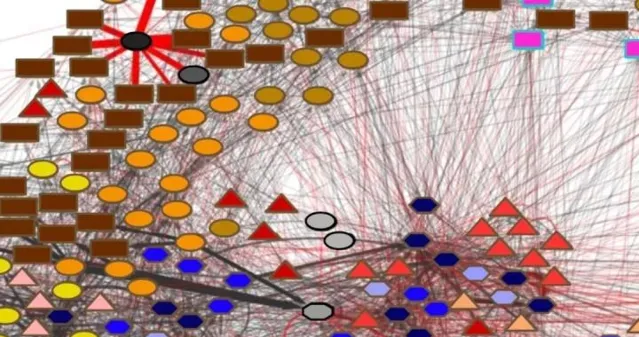
NCPs 的基本神經元模型
Many neural circuits within the nematode's nervous system are constructed by a distinct four-layer hierarchical network topology.
NCPs的神經元模型如下圖所示:
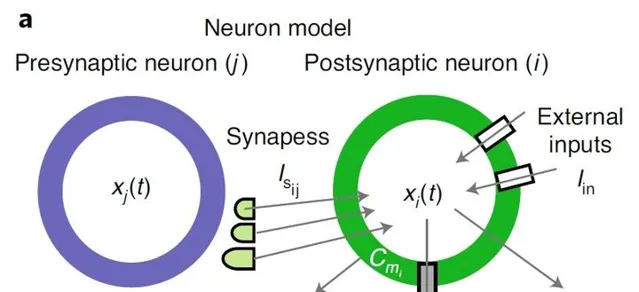
神經元模型的計算可以表示為continuous-time ordinary differential equations (ODEs) 連續時間常微分方程式:
\dot{x}_{i}=-\left(\frac{1}{\tau_{i}}+\frac{w_{i j}}{C_{\mathrm{m}_{i}}} \sigma_{i}\left(x_{j}\right)\right) x_{i}+\left(\frac{x_{\text {leak }_{i}}}{\tau_{i}}+\frac{w_{i j}}{C_{\mathrm{m}_{i}}} \sigma_{i}\left(x_{j}\right) E_{i j}\right)
LTC neural model 與生物神經網絡中的 Leaky integrate-and-fire model 膜電位的計算類似。但是脈沖神經網絡的輸出是離散的二值脈沖,LTC 神經元模型是連續的時域輸出。NCPs的核心是一種非線性時變突觸傳遞機制,與深度學習相比,這種機制提高了它們在建模時間序列時的表達能力。
NCPs 的網絡結構
文中的網絡結構遵循了四條規則:
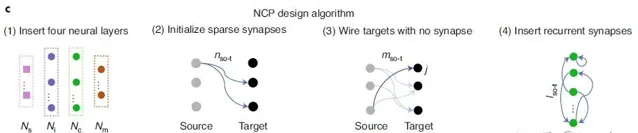
- 網絡中共有四種神經元,包括:感覺神經元、中間神經元、指令神經元以及運動神經元。四種神經元模型的分配方式如圖所示。
- 在任意兩層神經元中間,突觸行程所需要的極性(興奮或者是抑制)以及目標神經元的選擇都是滿足二項分布的。
- 任意沒有突觸的目標神經元,與前一層的神經元建立突觸,前一層神經元的選擇記憶突觸的極性都是滿足二項分布的。
- 對於 command 神經元,層之間建立突觸,目標神經元以及突觸極性的選擇滿足二項分布。
NCPs 網絡的訓練
-
訓練數據:真實的駕駛中的觀測值以及決策值
> A large-scale selection of labelled training data were collected by recording the observations and actions of a human driver (see Methods for more details). -
訓練方式:semi-implicit ODE
> Given a designed NCP network, we apply a semi-implicit ODE solver to obtain a numerically accurate and stable solution of the system.
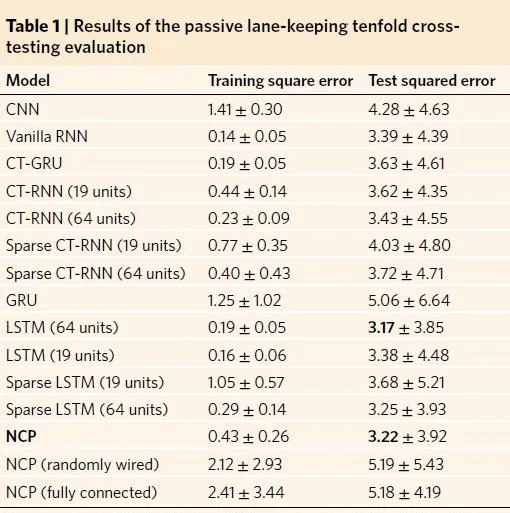
訓練結果與其他模型進行了對比,其中在對比的過程中摺積部份是固定的。對標其他的RNN網絡,NCP 網絡在測試數據集以及訓練數據集中的差距較小。