導讀: 什麽樣的模型是好的模型?相信這是每一個數據分析師和大數據AI演算法工程師都曾經默默思考過的問題。
為了更全面地思考這個問題,我們不妨從以下三方面進行討論。
01如何理解「模型」?
「模型」的英文model,究其拉丁詞源,是從modus這個詞演化而來。而modus這個詞在拉丁文中的含義基本可以用「測量」「標準」來概括。在漢語字典中,「模型」這個詞可以分成兩個字來理解:「模」是指規範、標準,「型」是樣式的意思。將兩種語言環境下的含義進行統一,「模型」就是「參照一定規範與標準而形成的樣式」。
為理解「模型」這個概念,有兩點內容是需要著重理解的。
A. 「模型」參照一定的規範與標準,但並不一定要完全復制。例如,依照著實體的飛機,可以制作飛機模型。這個「模型」中,規範與標準是真實的飛機,最終形成的樣式是一個小型的仿照真實飛機樣子制作的模子。這種盡可能仿真無失真地復制規範與標準的樣式是模型。又如,將一些互聯網移動支付行為,以數據關系的形式形成互動行為模型。在這個過程中,規範與標準是真實世界的互聯網移動支付行為,最終形成的樣式是一個反應互動行為的數據表現形式,即互動行為模型。在這個模型中,表現的真實支付行為可能會不太完整,可能僅僅是一小部份支付行為的數據記錄,也有可能是一些經過處理與簡化的抽象表達。這種參照規範與標準,進行抽象、簡化、抽取或組合等方式形成的樣式也是模型。
B. 「模型」落地形成的樣式,可以是物理實體,也可以是靜態的抽象表達,還可以是或靜態、或動態的實體與實體間的影響與關系。例如:上面提到的飛機模型就是一個物理實體;如果把使用者在某網站上的如ID、年齡、職業等資訊以一維表的形式組織,表中每一行記錄代表一個使用者的基本資訊,這裏就是對使用者的抽象表達而形成的模型;如果以一定的形式(圖示、圖表、描述等)將家庭成員中的夫妻、父女、母子、母女、父子等關系進行記錄,該記錄反映的家庭成員間的關系同樣是一種模型;「氣溫升高,冰塊就會融化」,這句話表述的氣溫與冰塊間的影響關系(不論是定性還是定量)也是一種模型……
數據科學領域中的「模型」並不脫離「模型」本質的含義,「規範與標準」可以是非常復雜的現實世界,也可以是一個個具體領域中業務關註的客觀存在。但由於將研究內容確定在了數據科學的範圍內,最終落地的「樣式」多為各種各樣的數據表達。當然,這其中包括靜態表達,也包括動態表達。
在數據科學的相關領域中(包括數據分析、資料探勘、人工智能等數據發揮巨大作用的領域),按照「模型」的使用形態,可以被分成以下三個大類:業務模型,數據模型,函數模型。
1. 業務模型的含義
業務模型是將現實世界、復雜事物、具體問題以某種特定方式進行重塑的模型。業務模型中所謂的「規範與標準」無疑是現實世界、復雜事物、具體問題等客觀反映。而業務模型的「樣式」,是一個抽象的存在,但這個抽象的存在卻有著比較形象的表現形式,這個表現形式是多種多樣的。
舉例來講,圖1是某電商APP的業務邏輯模型圖。該圖描述的是該電商APP使用者下單後的整個業務流程。在這個業務模型中,「規範與標準」是使用者從支付到發貨再到收貨的整個現實環節,「樣式」是抽象的,也就是一個非常虛擬的業務流程概念,下面的這張流程圖僅僅是該業務模型的一種具體表現形式。可以把該表現形式下的業務模型稱作一個完整的業務模型。但讀者應該知道,這樣的業務模型,實際上是一種抽象的(或產品的、流程的、組織的、邏輯的)存在,這種表現形式並不是業務模型的全部。

圖1 某電商APP的業務邏輯模型圖
2. 數據模型的含義
雖然說透過流圖、流程圖、結構圖等方式可以將業務模型形象化,但業務模型的本質是抽象的。所有的業務模型都要被落地處理,在不同的領域就會有不同的表現方式。在數據科學方面,業務模型是以數據模型的形式落地的。
數據模型是對現實世界以數據方式描述的模型。與業務模型一樣,數據模型的「規範與標準」同樣來源於現實世界中的各種場景,但數據模型的表現「樣式」更加具體一些,它是以組織化的數據形式來表現的。在數據模型的組織與處理過程中,最重要的工具就是數據庫和資料倉儲。
一般認為,數據模型包含的內容主要有三方面:數據結構、數據操作、數據約束。
數據結構是指要描述的數據的類別、內容、性質以及數據相互間的聯系等。數據結構是數據模型的基礎,數據操作和約束都基本建立在數據結構上。不同的數據結構具有不同的操作和約束。
數據操作是指用於要描述的數據的各項操作。具體包括每個操作的操作類別和具體操作方式。數據操作的若幹操作連帶上隱含於其中的推理規則,用以對目標類別的有效數據物件集合進行操作。
數據約束是指數據結構內部的或數據與數據之間的組織規則、相互聯系、制約和依存關系,以及數據動態變化的規範。數據約束的目的是保證數據在儲存與處理過程中的正確性、一致性和相容性。
以數據結構、數據操作、數據約束為底層邏輯基礎,形成了當前常見的三種數據模型:層次數據模型,網狀數據模型,關系數據模型。
3. 函數模型的含義
函數模型是表示實體變量與實體變量間變換關系的模型。
與業務模型和數據模型不同的是,函數模型幾乎只用來表示實體變量之間的關系,這種關系以數學函數的形式表達,表達更加精準、多樣、簡潔且不失豐富。函數模型的「規範與標準」是現實世界與業務中的實體變量間的真實關系。而它的「樣式」是函數。在數學中,函數有三個元素:定義域、值域、對應法則,這些也是函數模型的前提與要素。
定義域規定了函數的輸入範圍,值域定義了函數的輸出範圍,對應法則確定了從輸入到輸出的對映關系。對於函數模型來講,這個對映關系可以是事先指定好的,指定的內容既包括函數形式,也包括參數值。也可以是先確定好函數形式,而不指定參數值,在使用時再確定其參數值。
一般情況下,函數模型在使用時首先要確定函數形式。而函數參數的確定則可以有兩種思路:一種是直接指定這些函數的參數,或是在經過一定程度的分析後,指定函數模型的參數;另一種思路是假定當前數據的輸入與輸出的對映結果是已知的,或是輸出的目標形式是已知的,根據輸入與輸出的關系,設定一定的目標,透過一定的機制,自動計算這些參數。後面這種確定函數形式後,透過數據計算參數的整個流程,常常被稱作機器學習。用數據來計算參數的函數模型就是機器學習模型,而透過數據來電腦器學習模型參數的動態過程被稱作模型參數訓練,簡稱訓練。
常見的機器學習模型(包括深度學習模型)都是函數模型。
02如何理解「好」?
可見,模型是現實世界的濃縮和模仿,一個好的模型,就一定是一個可以以盡可能低的成本,同時盡可能真實地反映客觀世界概況的模型。
但是,此話說得簡單,而在面對實際場景時,關於「好」的具體形態,往往又令我們感到力不從心。
這不得不提到數據科學領域非常流行的一句話:「好的數據勝於好的特征,好的特征勝於好的演算法。」套用於機器學習時,這句話還有另一種表達形式:「數據和特征決定了機器學習的上界,模型只是在不斷逼近這個上界而已」。因此,不管是在推薦領域,還是在廣告領域;不管是在電商系統,還是在Feed流……一定業務場景確定了,數據規模、數據維度確定了,「最好」模型可以達到的最佳能力幾乎就可以確定了。只是說,要找到這樣的模型,會特別特別困難。
1. 好的模型,是一個可以達到更好業務效果的模型。
不同的業務場景中,數據形態各不一樣。即便是同樣的業務場景下,由於數據量的規模有大有小,數據維度有多有少,「上界」就會不一樣。有時,我們會認為可以取得更好業務效果的模型就是更好的模型,認真來講,有時這個鍋真不應該模型來背。一個好的模型,應該是在一定的數據規模和數據維度的條件下,可以最接近上界的對映反應。
2. 好的模型,是一個可以反映真實業務關系的模型。
靠近數據與特征確定的上界,主要依賴模型自身透過參數的調節能力。但另一個影響模型業務效果的因素也不能被忽略:模型的歸納偏置。模型的歸納偏置在數據科學的理論中,被當作反映數據樣本的先驗假設。歸納偏置本是一個數學與邏輯學中比較正式的概念,但在數據科學中,這個概念與函數模型得到很好的解耦。歸納偏置是一些簡單的邏輯表述,這些邏輯並不應該被憑空構想,而應該基於實際的業務場景進行提煉。
例如,在SVM模型中,我們會認為不同分類之間的分類超平面應該距兩個分類的支持向量間的距離是相等的並且是最大的。但是為什麽?這是因為我們認為兩個分類間的間隔就應該如此,這是在「業務」上帶入的假設。但如果是在下面的場景中,兩個分類之間的平面應該更靠近A還是更靠近B?方塊樣本的數量非常多,如此多的樣本集中分布在一片空間,我們也有理由相信,B更有可能是分類的分界超平面。當然,這也是一個假設。
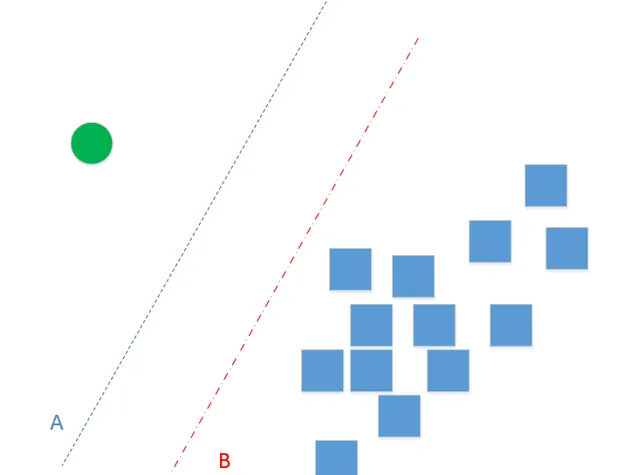
在考慮模型構建時,不用太多考慮歸納偏置的問題。真正需要考慮歸納偏置應該是在模型構建之前(即選擇模型時)進行。歸納偏置在選擇模型或設計模型時是非常重要的考慮因素。有些模型甚至就是基於特定的歸納偏置而設計的,如果歸納偏置本身就與業務現實差距很大,那基於該歸納偏置設計的模型也將失去意義。
3. 好的模型,有時也需要更好的可解釋性。
一般來講,用數據訓練一個機器學習模型,這個機器學習模型就可以被當作一個「黑盒」,使用這個模型時,只需要關註輸入與輸出就可以了。但在很多場景中,人們在關註輸入與輸出的關系時,也非常關註造成輸出結果的原因。例如,建立起一個醫療智能診斷模型,當輸入一個人的各項身體機能指標後,它會輸出身體的健康狀態,以及如果身體狀態不佳時,最可能患上哪種疾病。如果有一個參與者,使用該模型後,被診斷出身體狀態不佳,近期最可能患上感冒。此時參與者自我感覺良好,想知道自己身體狀態不佳是為什麽,表現在哪裏。此時,如果模型可解釋性不強,就得不到相應的衍生結論。
模型的可解釋性同時也可以為接下來業務的提升與改進提供非常有意義的指導與借鑒。例如,如果透過一個金融風控模型準確高效辨識出有金融欺詐意圖的使用者,模型的可解釋性可以對接下來如何進一步保障服務安全,從哪裏入手,采取措施後預計會有什麽樣的後果等都有非常可靠的指導與評價。
一些模型本身帶有表達特征重要性的因子,如很多的樹型結構的模型(決策樹、隨機森林、GBDT等)、線性模型(特征參數的絕對值大小)、LR模型等。這些表達重要性的因子可以提供一定的模型解釋能力。
有些模型雖然不包含表達重要性的因子,但它的結構是透明的,可以透過解析模型結構,提煉輸出的可解釋原因。例如,KNN、很多聚類模型等。
像人工神經網絡這樣的模型,從結構上很難獲得模型的可解釋依據,它的可解釋性就非常差。這也是制約人工神經網絡在結構化數據的業務中被進一步套用的一個很大原因。
03有萬能的模型麽?
很難對這樣的一個問題,給出肯定的答案。因為一個萬能的模型,就一定會照顧到這個世界上幾乎所有的數據,所有的特征,以及所有的業務知識。這是非常困難的一件事。
但對於某一個具體的業務場景與一定的條件約束,找到那個最合適的模型也並不是沒有思路。奧卡姆剃刀就是這其中的一個非常重要的指導思想。
「如無必要,勿增實體」,這是奧卡姆剃刀原則的全部。
試想一下,從拿到數據,再到根據這些數據訓練模型,並輸出結果,這其中導致模型輸出特定結果發生的原因可能來自哪裏?這個原因毫無疑問會來自數據攜帶的資訊,也會來自在特征工程時做過的處理,還會來自模型本身帶有的歸納偏置。
如果一個對數據科學與數據處理原理不是很明白的人,或者是一些模型的探索者、業務的實踐者,看到了模型的執行機制,強行修改模型,這等同於在這個數據資訊處理的過程中,加入了除數據規律、特征工程提取、模型歸納偏置之外的其他資訊。例如,在CART決策樹模型中,某建模人員把按照Gini系數減少最多的決策特征排列,強行變換了其中兩個中間節點的特征位置,這就人為地加入了對特征重要程度的判斷。當然,如果建模人員有非常非常非常確定的把握,經過了改造的模型也是有可能表現出更好的泛化能力的。但考慮到很多情況,人總是經不住拍腦袋做決定的沖動,強行改造模型都是一種業務上的嘗試,改造後的模型基本沒有復用性。對整體業務結果與效能的提升程度,其實不如好好研究怎麽選擇樣本,怎麽進行特征工程來得實在。
奧卡姆剃刀原則在底層邏輯上對沒有根據就隨意修改模型的行為說了「不」,即使是為了嘗試。不過,這並不是說在選擇模型時不應該嘗試去,而是說可以去嘗試各種模型隱含的假設的合理性,嘗試某個特征工程環節的有效性,而不應該去嘗試「任意改造模型」的可行性。
數據科學,其實就是一場資訊遊戲。
雖然很難透過一個萬能的模型整合世界上所有數據帶有的資訊,但透過遷移的方式對領域內的資訊進行整合,並套用於更多相關業務場景,卻是一個非常有效的折中。近幾年,在NLP領域中大行其道的BERT等帶有預訓練機制的模型,充分整合了自然語言中的先驗資訊,讓模型在非常多的場景下都可以得到「屠榜」的業務效果。同樣神奇還有另一個模型——GPT3。在整合了極其巨量的互聯網數據資訊,並以1750億參數為調整空間,它可以幫助人們完成設計原型圖、制作資產負債表、查到某些名人的社交賬號等等。
萬能的模型雖然很難構建,但是不是我們已經可以看到它的身影了?
今天的分享就到這裏,謝謝大家。
文章作者:途索 阿裏巴巴 演算法專家
內容來源:【數據分析通識】











