檢視參照/資訊源請點選:映維網
或能套用於增強現實/虛擬現實的部份論文及相關摘要( 映維網 2021年07月07日 )2021年電腦視覺和模式辨識大會(Conference on Computer Vision and Pattern Recognition;CVPR)早前已經公布了收錄的論文,涵蓋物件對映與渲染,3D人類姿態生成,語意分割和透明物件關鍵點估計等一系列的電腦視覺研究。
延伸閱讀 :CVPR2021 Part 1:百篇AR/VR關聯性研究成果匯總延伸閱讀 :CVPR2021 Part 2:百篇AR/VR關聯性研究成果匯總
下面映維網整理了或能套用於增強現實/虛擬現實的部份論文及相關摘要,一共分三篇,這是第一篇:
1. Polka Lines: Learning Structured Illumination and Reconstruction for Active Stereo
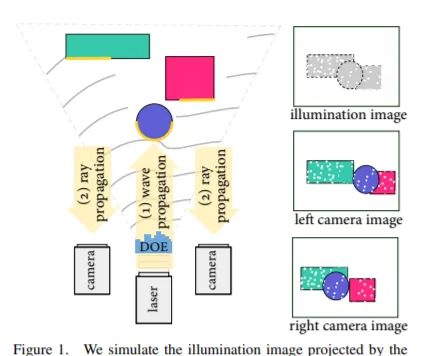
從結構光捕獲中恢復深度的主動立體網絡攝影機已成為三維場景重建和跨套用領域理解任務的基礎傳感器。主動立體網絡攝影機在物件表面投影一個偽隨機點圖案,以獨立於物件紋理提取視差。這種手動制作的圖案是在與場景統計、環境照明條件和重建方法隔離的情況下設計而成。在這項研究中,我們提出了一種方法來共同學習結構化照明和重建。我們提出了一種基於波動光學和幾何光學的主動立體可微成像模型和三目重建網絡。我們將這種聯合最佳化圖案稱為「Polka Line」,而連同重建網絡,它們能夠在整個成像條件下實作精確的主動立體深度估計。
相關論文:Polka Lines: Learning Structured Illumination and Reconstruction for Active Stereo2. Visually Informed Binaural Audio Generation without Binaural Audios
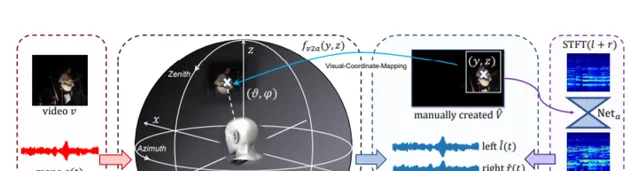
立體聲音訊,尤其是雙耳音訊,在沈浸式環境中起著至關重要的作用。最近的研究探索了透過多聲道音訊采集監督的立體聲音訊。但由於專業記錄器材的要求,現有的數據集在規模和種類方面受到限制,從而阻礙了監督方法在現實場景中的推廣。我們在這項研究中提出了PseudoBinaural,一個無需雙耳錄音的有效管道。關鍵的洞察是仔細建立偽視覺立體對與單聲道數據的訓練。具體來說,我們利用球諧分解和頭相關脈沖響應(HRIR)來確定空間位置和接收到的雙耳音訊之間的關系。然後在視覺模態中,單聲道數據的相應視覺線索手動放置在聲源位置以形成對。與完全監督模式相比,我們的管道在交叉數據集評估中表現出極大的穩定性,並且在主觀偏好下達到了相當的效能。
相關論文:Visually Informed Binaural Audio Generation without Binaural Audios3. Dual Attention Guided Gaze Target Detection in the Wild
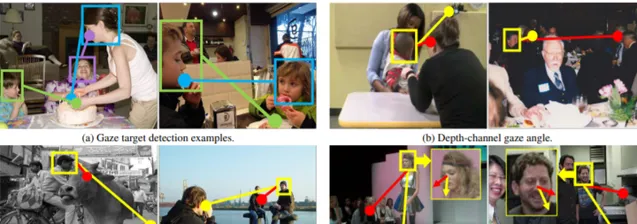
註視目標檢測的目標是推斷場景中每個人的註視點。現有的研究主要集中在二維註視和二維顯著性,沒有充分利用三維背景。在這項研究中,我們提出了一個三階段方法來模擬人類在三維空間中的註視推理行為。在第一階段,我們引入一個由粗到精的策略來穩健地估計頭部的三維註視方向。預測的註視分解為影像平面的平面註視和深度通道註視;在第二階段,我們開發了一個Dual Attention Module(DAM),它利用平面註視產生視場,並根據深度通道註視來遮蔽受深度資訊調節的幹擾物件;在第三階段,我們使用雙註視作為引導以執行兩個子任務:(1)辨識註視目標是在影像內部還是外部,(2) 如果目標在裏面的話,定位目標。
相關論文:Dual Attention Guided Gaze Target Detection in the Wild4. Privacy Preserving Localization and Mapping from Uncalibrated Cameras
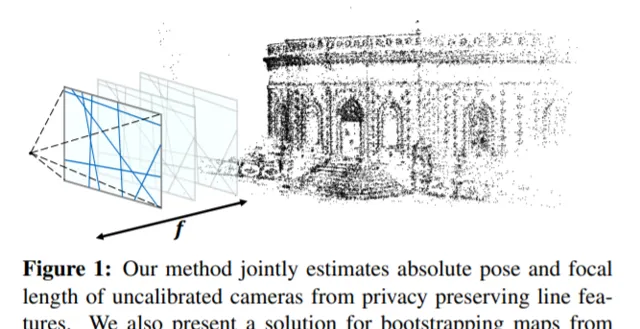
對於解決混合現實和機器人技術中的雲端解決方案所引起的線條特征私密問題,最近的研究在已經取得了重大進展。對校準網絡攝影機的要求是所述方法的一個基本限制,這妨礙了它們在眾多眾包對映場景中的套用。在本文中,我們針對未經校準的私密保護定位和對映問題提出了一個解決方案。我們的方法同時從線條特征恢復網絡攝影機的內在和外在校準。這使得未經校準的器材既可以在現有對映中定位自己,又可以對對映作出貢獻,並且同時保護影像內容的私密。
相關論文:Privacy Preserving Localization and Mapping from Uncalibrated Cameras5. Pixel-aligned Volumetric Avatars

圖片真實感人頭獲取與繪制是一個極具挑戰性的研究課題,對虛擬臨場感的實作具有特別重要的意義。對於目前最高質素的方法,其主要是透過在多檢視數據以特定於人的方式所訓練的體三維方法來實作。與更簡單的基於網格的模型相比,這種模型能夠更好地表示頭發等精細結構。體三維模型通常使用一個全域程式碼來表示面部表情,這樣它們就可以由一組小的動畫參數來驅動。盡管這樣的架構實作了令人印象深刻的渲染質素,但它們不容易擴充套件到多標識設定。在本文中,我們設計的方法只需給予少量的輸入即可預測體三維化身的人頭。我們透過一種新的參數化方法來將神經輻射場與直接從輸入中提取的局部像素對齊特征結合起來,從而避免了對深度或復雜網絡的需求。我們的方法是以端到端的方式訓練,完全基於光度重渲染損失,不需要顯式3D監督。
相關論文:Pixel-aligned Volumetric Avatars6. Monocular Depth Estimation via Listwise Ranking Using the Plackett-Luce Model

在許多實際套用中,物件在影像中的相對深度對於場景理解至關重要。目前的方法主要是將單目影像的深度預測問題作為一個回歸任務來處理。在本文中,我們詳細闡述了將所謂的listwise排序作為pairwise方法的泛化。我們的方法是基於Plackett-Luce(PL)模型,一種基於排名的概率分布,並結合最先進的神經網絡結構和簡單的采樣策略來降低訓練復雜度。另外,利用PL作為隨機效用模型的表示,我們提出的預測器提供了一種從訓練時提供的僅排名數據中恢復度量深度資訊的自然方法。
相關論文:Monocular Depth Estimation via Listwise Ranking Using the Plackett-Luce Model7. Holistic 3D Scene Understanding from a Single Image with Implicit Representation
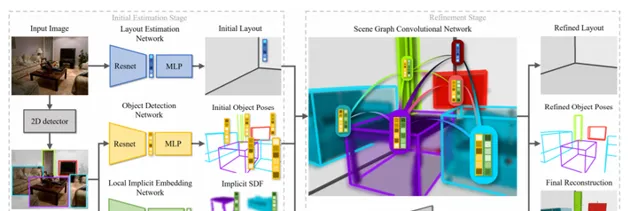
我們為從單張影像理解holistic 3D場景提出了一個新管道,其可以預測物件形狀,物件姿態和場景布局。由於這是一個高度不適定的問題,現有的方法通常會遇到形狀和布局估計不準確的問題,特別是對於雜亂的場景,物件之間存在嚴重的遮擋。我們建議利用最新的深層隱式表示來解決這個問題。我們不僅提出了一種基於影像的局部結構化隱式網絡來改進目標形狀估計,而且透過一種利用隱式局部目標特征的隱式場景圖神經網絡來細化三維目標的姿態和場景布局。另外,我們提出了一種新的物理沖突損失方法,以避免物件間的情景錯誤。
相關論文:Holistic 3D Scene Understanding from a Single Image with Implicit Representation8. DeepI2P: Image-to-Point Cloud Registration via Deep classification

本文提出了DeepI2P:一種新的影像與點雲跨模態配準方法。給定在同一場景中不同位置捕獲的影像(例如來自rgb網絡攝影機)和一般點雲(例如來自3D激光雷達掃描器),我們的方法估計網絡攝影機和激光雷達座標幀之間的相對剛性變換。由於兩種模式之間缺乏外觀和幾何相關性,所以學習公共特征描述符來建立配準對應具有內在的挑戰性。我們透過將配準問題轉化為分類和逆網絡攝影機投影最佳化問題來規避這一困難。我們同時設計了一種分類神經網絡,將其用於標記點雲中每個點的投影是在網絡攝影機截錐體的內部還是外部。這些標記點隨後被傳遞到一個新的逆網絡攝影機投影解算器來估計相對姿態。
相關論文:DeepI2P: Image-to-Point Cloud Registration via Deep classification9. OpenRooms: An Open Framework for Photorealistic Indoor Scene Datasets
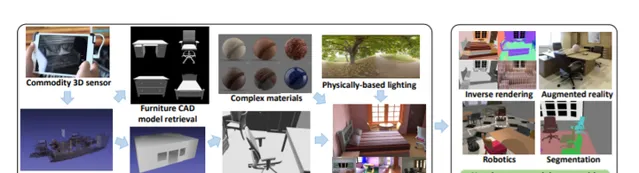
我們提出了一個新的框架來建立室內場景的大規模照片級真實感數據集,包括ground truth幾何、材質、光照和語意。我們的目標是提高數據集建立過程的可存取性,將掃描轉換為具有高質素外觀、布局、語意標簽、空間變化BRDF和復雜照明的照片級真實感數據集。我們證明,在所提出的數據集上訓練的深度網絡在真實影像的形狀、材質和光照估計方面具有很好的效能。我們同時展示了我們的語意標簽可以用於分割和多工學習。最後,我們證明了我們的框架可以與物理引擎整合。
相關論文:OpenRooms: An Open Framework for Photorealistic Indoor Scene Datasets10. SliceNet: deep dense depth estimation from a single indoor panorama using a slice-based representation

我們提出了一種新的深度神經網絡來估計單目室內全景圖的深度圖。所述網絡直接支持等矩形投影,從而充分利用室內360度影像的特性。從重力在室內場景設計和構建中的重要作用出發,我們提出了一種將場景緊湊地表示為球體垂直切片的方法,並利用切片間的長短期關系來恢復等矩形深度對映。我們的設計使得在提取的特征中保持高分辨率的資訊成為可能。
相關論文:SliceNet: deep dense depth estimation from a single indoor panorama using a slice-based representation11. Pulsar: Efficient Sphere-based Neural Rendering

我們提出了一個基於球體的可微渲染器Pulsar。由於與PyTorch緊密整合,它比競爭技術快幾個數量級,模組化,且易於使用。微分渲染是現代神經渲染方法的基礎,因為它能夠實作從影像觀察到的三維場景表示進行端到端訓練。然而,基於梯度的神經網格、體素或函數表示的最佳化面臨多重挑戰:拓撲不一致、記憶體占用高或渲染速度慢。為了緩解這些問題,Pulsar采用了:1)基於球體的場景表示,2)高效的可微渲染引擎,3)神經著色。使用球體作為場景表示,在避免拓撲問題的同時可以獲得前所未有的速度。Pulsar完全可微,所以可以實作從三維重建到一般神經渲染的大量套用。
相關論文:Pulsar: Efficient Sphere-based Neural Rendering12. STaR: Self-supervised Tracking and Reconstruction of Rigid Objects in Motion with Neural Rendering
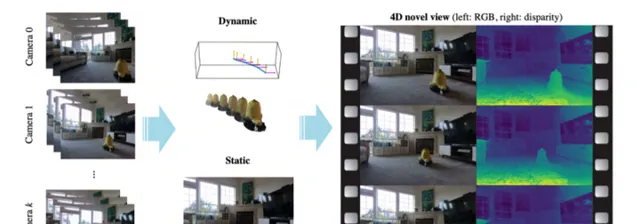
我們提出的STaR可以在不需要任何人工註釋的情況下,從多視點RGB影片中對具有剛性運動的動態場景執行自監督跟蹤和重建。最近的研究表明,神經網絡在將一個場景的許多檢視壓縮成一個學習函數方面是出人意料的有效。遺憾的是,一旦場景中的任何物件發生移動,所述方法就失去了所有的預測能力。在這項探究中,我們顯式建模物件的剛性運動。不需要任何額外的人類指定監督,透過同時將其分解成兩個組成部份,並用自己的神經表示編碼每一個,我們可以重建一個包含單一剛性物件在運動的動態場景。我們透過聯合最佳化兩個神經輻射場的參數和一組剛性姿態來實作這一點。
相關論文:STaR: Self-supervised Tracking and Reconstruction of Rigid Objects in Motion with Neural Rendering13. Monocular Real-time Full Body Capture with Inter-part Correlations

我們提出了一種即時全身捕捉的方法,其可以從一幅單色影像中估計出身體和手部的形狀和運動,以及一個動態的三維人臉模型。我們的方法使用了一種利用身體和手部之間相關性的神經網絡結構,其具有很高的計算效率。與以前的研究不同,我們的方法是在多個分別專註於手部,身體和人臉的數據集上聯合訓練,不需要同時對所有部份進行註釋的數據。這種多數據集訓練的可能性使其具有優越的泛化能力。與早期的單目全身方法相比,我們的方法透過估計統計人臉模型的形狀、表情、反照率和光照參數來捕捉更具表現力的三維人臉幾何結構和顏色。
相關論文:Monocular Real-time Full Body Capture with Inter-part Correlations14. ContactOpt: Optimizing Contact to Improve Grasps
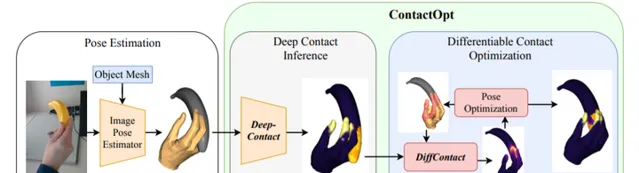
手部和物件之間的物理接觸在人類的抓握中起著至關重要的作用。我們發現,透過最佳化手部姿態來實作與目標的預期接觸,可以改善透過基於影像的方法所推斷出的手部姿態。給定一個手部網格和一個物件網格,一個基於ground truth接觸數據訓練的深層模型可以推斷出網格表面的理想接觸。然後,ContactOpt使用可微的接觸模型來有效地最佳化手部姿勢以獲得理想的接觸。值得註意的是,我們的接觸模型鼓勵網格穿透來近似手部可變形的軟組織。
相關論文:ContactOpt: Optimizing Contact to Improve Grasps15. Plan2Scene: Converting Floorplans to 3D Scenes
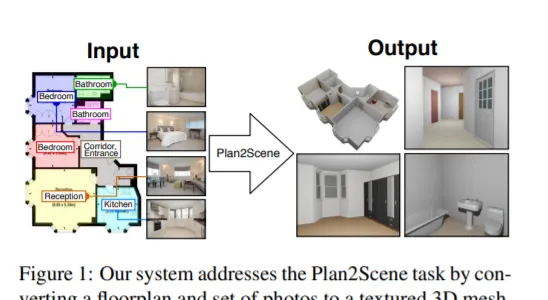
我們要解決的任務是將一個平面圖和一組住宅相關照片轉換成一個具有紋理的三維網格模型,我們將我們的系統稱之為Plan2Scene。我們的系統可以:1)將平面圖影像提升為三維網格模型;2) 根據輸入的照片合成表面紋理;以及3)使用圖神經網絡結構推斷未觀察表面的紋理。為了訓練和評估我們的系統,我們建立了室內表面紋理數據集,並用校正的表面裁剪和附加註釋擴充先前研究的平面圖和照片數據集。定性和定量評估表明,我們的系統產生了逼真的三維室內模型。
相關論文:Plan2Scene: Converting Floorplans to 3D Scenes16. Semi-Supervised 3D Hand-Object Poses Estimation with Interactions in Time

從一幅影像中估計三維手部和物件姿態是一個極具挑戰性的問題:手和物件在互動過程中常常是自遮擋的,而且三維註釋是稀缺的,因為即使是人類都無法直接從一幅影像中完美地標註出ground-truth。為了解決這些問題,我們提出了一個透過半監督學習來估計三維手部和物件姿態的統一框架。我們建立了一個聯合學習框架。在這個框架中,我們透過一個轉換器在手部和物件表示之間進行顯式情景推理。在半監督學習中,我們超越了單一影像中有限的三維標註,利用大規模手部目標影片中的時空一致性作為生成偽標簽的約束條件。透過根據不同影片進行大規模訓練,我們的模型能更好地推廣到多個域外數據集。
相關論文:Semi-Supervised 3D Hand-Object Poses Estimation with Interactions in Time17. Continual Semantic Segmentation via Repulsion-Attraction of Sparse and Disentangled Latent Representations
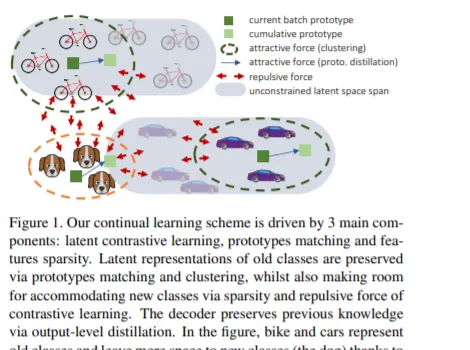
深度神經網絡在學習新任務時存在著遺忘舊任務的缺陷。在本文中,我們主要研究語意切分中的類增量連續學習,其中新類別隨著時間的推移而變得可用,而先前的訓練數據不被保留。所提出的持續學習方案在形成隱空間以減少遺忘的同時提高了對新類的辨識。我們的框架是由三個新元件驅動,我們同時可以輕松地將它們結合到現有技術之上。首先,原型匹配在舊類上強制隱空間一致性,約束編碼器在後續步驟中為先前看到的類生成類似的隱表示。第二,特征稀疏化允許在隱空間中騰出空間來容納新類。最後,采用對比學習的方法對特征進行語意聚類,同時對不同類別的特征進行拆分。對Pascal VOC2012和ADE20K數據集的廣泛評估表明了我們方法的有效性。
相關論文:Continual Semantic Segmentation via Repulsion-Attraction of Sparse and Disentangled Latent Representations18. Self-supervised Geometric Perception
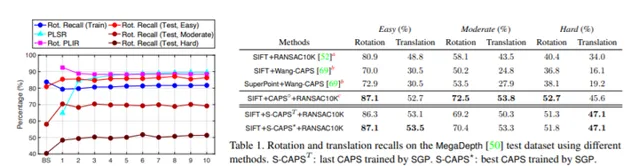
我們提出了一種自監督幾何感知(SGP),這是一個在沒有任何ground-truth幾何模型標簽的情況下學習特征描述的通用框架。我們的第一個貢獻是將幾何感知表述為一個最佳化問題,聯合最佳化了給定大量視覺測量數據的特征描述和幾何模型。在這個最佳化公式下,我們證明了視覺中兩個重要的研究方向,即魯棒模型擬合和深度特征學習,分別對應於最佳化一個未知變量塊和固定另一個未知變量塊。這一分析自然導致了我們的第二個貢獻:SGP演算法,它執行交替最小化來解決聯合最佳化問題。SGP叠代地執行兩個元演算法:一個teacher對給定的學習特征進行穩健的模型擬合以生成幾何偽標簽,另一個student在偽標簽的噪點監督下進行深度特征學習。
相關論文:Self-supervised Geometric Perception19. Stay Positive: Non-Negative Image Synthesis for Augmented Reality
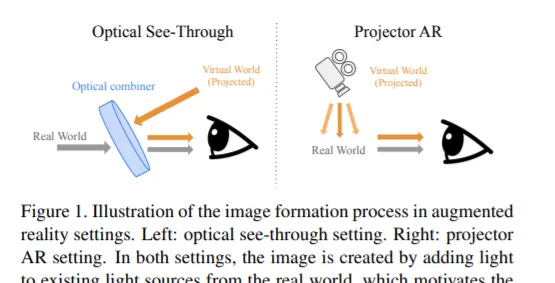
在光學透明和投影機增強現實等套用中,生成影像相當於解決非負影像生成問題,即只能向現有影像添加光。然而,大多數影像生成方法都不適合這種問題設定,因為它們假設可以為每個像素指定任意顏色。我們知道,人類的視覺系統可能會被涉及亮度和對比度的某些空間配置的光學錯覺所欺騙。我們的關鍵洞察是,可以利用這種行為產生高質素的影像與可忽略的偽影。例如,我們可以透過使周圍像素變亮來建立較暗斑塊的假象。我們提出了一個新的最佳化過程來產生同時滿足語意和非負性約束的影像。我們的方法可以結合現有的最先進方法,並在各種任務重表現出強大的效能。
相關論文:Stay Positive: Non-Negative Image Synthesis for Augmented Reality20. 3D-to-2D Distillation for Indoor Scene Parsing
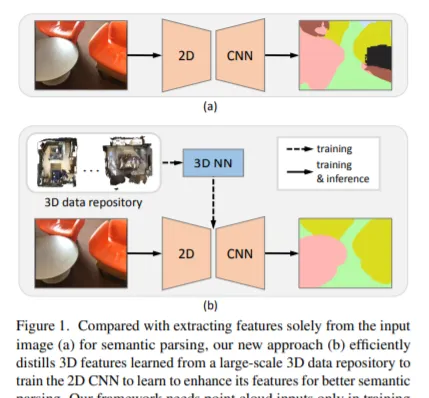
由於遮擋、物件變形和視點變化等原因,從RGB影像中進行室內場景語意分析具有非常大的挑戰性。我們提出了一種新的方法3D到2D蒸餾框架,它使我們能夠利用從大規模三維數據儲存庫中提取的3D特征來增強從RGB影像中提取的2D特征。我們的工作有三個新穎的貢獻。首先,我們從預先訓練好的3D網絡中提取3D知識,監督2D網絡在訓練過程中從2D特征中學習模擬的3D特征,這樣2D網絡就可以在不需要3D數據的情況下進行推理。第二,我們設計了一個兩階段的維度標準化方案來校準2D和3D特征,以便實作更好地整合。第三,我們設計了一個語意感知的對抗性訓練模型來擴充套件我們的框架,並用於訓練不成對的三維數據。
相關論文:3D-to-2D Distillation for Indoor Scene Parsing21. Large-scale Localization Datasets in Crowded Indoor Spaces
利用視覺定位來估計網絡攝影機的精確位置可以實作有趣的套用,如增強現實或機器人導航。這在其他定位技術(如GNSS)無法支持的室內環境中尤其有用。室內空間對視覺定位演算法提出了有趣的挑戰:人的遮擋、無紋理的表面、大的視點變化、低光、重復的紋理等。現有的室內數據集要麽相對較小,要麽僅涵蓋上述挑戰的一個子集。在本文中,我們介紹了5個新的室內數據集,並用於在具有挑戰性的真實環境中進行視覺定位。為了獲得精確的ground truth網絡攝影機姿態,我們開發了一種魯棒的激光雷達SLAM。它提供初始姿態,然後使用基於運動最佳化的新結構對初始姿態進行細化。
相關論文:Large-scale Localization Datasets in Crowded Indoor Spaces22. Scene-aware Generative Network for Human Motion Synthesis
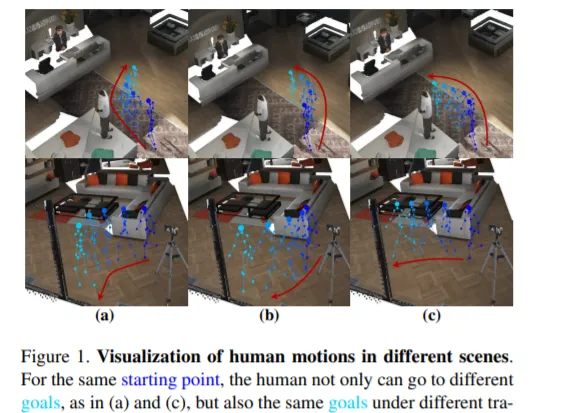
人體運動合成對一系列的現實世界套用非常有用。盡管已有許多方法用於這一任務,但它們通常局限於兩個方面:關註姿態而忽略位置運動,以及忽略環境對人體運動的影響。在本文中,我們提出了一個新的框架,其考慮了場景和人體運動之間的相互作用。考慮到人體運動的不確定性,我們將這一任務描述為一個生成性任務,其目標是在場景和人體初始位置上生成合理的人體運動。所述框架將人體運動的分布分解為以場景為條件的運動軌跡分布,以及以場景和軌跡為條件的人體姿態動力學分布。我們進一步推導了一種基於GAN的學習方法,使用鑒別器來增強人體運動和背景場景之間的相容性,以及3D到2D的投影約束。
相關論文:Scene-aware Generative Network for Human Motion Synthesis23. Exploring Sparsity in Image Super-Resolution for Efficient Inference
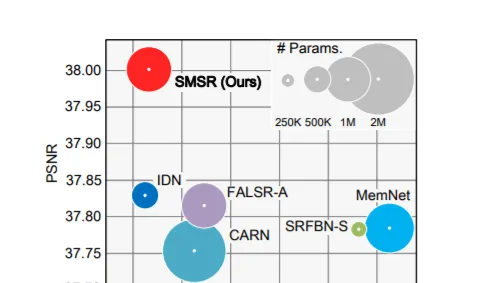
在空間上均勻分配計算資源的情況下,基於CNN的現有超分辨率(SR)方法對所有位置進行平均處理。然而,由於低分辨率(LR)影像中的細節缺失主要存在於邊緣和紋理區域,相關區域只需要較少的計算資源。所以,基於CNN的現在方法在存在冗余計算,增加了計算量,限制了其在流動通訊器材的套用。為了提高隨機共振網絡的推理效率,本文研究了影像隨機共振的稀疏性。具體地說,我們開發了一個Sparse Mask SR(SMSR)網絡來學習稀疏掩碼,從而減少冗余計算。在我們的SMSR中,空間掩碼學習辨識「重要」區域,而通道掩碼學習標記那些「不重要」區域中的冗余通道。
相關論文:Exploring Sparsity in Image Super-Resolution for Efficient Inference24. stylePeople: A Generative Model of Fullbody Human Avatars
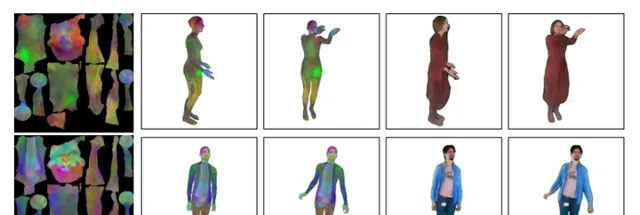
我們提出了一種基於參數化網格的人體模型與神經紋理相結合的新型全身人體化身。我們表明,借助於神經紋理,這樣的化身可以成功地模擬衣服和頭發。我們同時展示了如何使用反向傳播從影片的多個幀中建立所述化身。然後,我們提出了一個生成模型,其可以從影像和影片數據集中訓練化身。生成模型允許我們采樣隨機化身,或可以從一張或幾張圖片中建立穿衣化身。
相關論文: stylePeople: A Generative Model of Fullbody Human Avatars25. SOE-Net: A Self-Attention and Orientation Encoding Network for Point Cloud based Place Recognition

針對點雲數據的位置辨識問題,我們提出了一種基於自註意和方向編碼的網絡SOE-Net。這個網絡充分挖掘了點與點之間的關系,並將長程情景引入到點域描述中。PointOE模組捕獲八個方向上每個點的局部資訊,而局部描述符之間的長程特征依賴關系則使用自關註單元捕獲。另外,我們提出了一種新的損失函數 Hard Positive Hard Negative quadruplet loss (HPHN quadruplet),它比常用的度量學習損失具有更好的效能。在各種基準數據集的實驗表明,這個網絡的效能優於目前最先進的方法。
相關論文:SOE-Net: A Self-Attention and Orientation Encoding Network for Point Cloud based Place Recognition26. DeepVideoMVS: Multi-View Stereo on Video with Recurrent Spatio-Temporal Fusion
我們提出了一種基於姿態影片流的線上多視點深度預測方法,所述方法將前一個time step中計算出的場景幾何資訊以一種有效且幾何合理的方式傳播到當前time step中。我們方法的核心是一個即時的、輕量級的編碼器-解碼器,它依賴於從影像對計算出的成本量。我們透過在瓶頸層放置一個ConvLSTM單元來擴充套件它。我們方法的新穎之處在於,透過考慮time step之間的視點變化來傳播單元的隱藏狀態。給定time step,我們使用先前的深度預測來將先前的隱藏狀態扭曲到當前攝影頭平面。我們的擴充套件只帶來了很小的計算時間和記憶體消耗開銷,同時顯著提高了深度預測。
相關論文:DeepVideoMVS: Multi-View Stereo on Video with Recurrent Spatio-Temporal Fusion27. CodedStereo: Learned Phase Masks for Large Depth-of-field Stereo
傳統的立體影像在成像體積和訊噪比(SNR)之間有一個基本的權衡。受擴充套件景深網絡攝影機的啟發,我們提出了一種基於端到端學習的技術,透過在立體成像系統中的網絡攝影機光圈平面引入相位掩模來克服這一限制。相位掩模建立了一個依賴於深度,但在數值上可逆的點擴充套件函數,這允許我們恢復銳利的影像紋理和立體對應。相位掩模模式、EDOF影像重建和立體視差估計都使用端到端學習的深度神經網絡進行訓練。我們同時構建了一個實驗原型,並利用原型系統獲得的實際結果對方法進行了驗證。
相關論文:CodedStereo: Learned Phase Masks for Large Depth-of-field Stereo28. Continuous Face Aging via Self-estimated Residual Age Embedding
人臉合成,特別是人臉老化,已經成為一個主要的主題。大多數現有的人臉老化方法將數據集劃分為多個年齡組,並利用基於組的訓練策略,這在本質上缺乏提供精細控制的連續老化合成能力。在這項研究中,我們提出的網絡結構可以將線性年齡估計器嵌入到基於GAN的模型中。其中,嵌入的年齡估計器與編碼器和解碼器聯合訓練,以估計人臉影像的年齡,並為年齡進行/回歸提供個人化的目標年齡嵌入。個人化目標年齡嵌入是透過結合當前年齡的個人化剩余年齡嵌入和目標年齡的樣本人臉老化基來合成。相關公式提供了估計年齡和生成個人化老年人臉的統一視角,每個年齡都可以學習自估計年齡嵌入。對不同數據集的定性和定量評價進一步證明,與最新技術相比,持續面部老化方面有顯著改善。
相關論文:Continuous Face Aging via Self-estimated Residual Age Embedding29. DI-Fusion: Online Implicit 3D Reconstruction with Deep Priors
以前的線上3D密集重建方法難以在記憶體儲存和表面質素之間取得平衡。本文提出了一種基於Probabilistic Local Implicit Voxels (PLIVoxs)的DI-Fusion(DI-Fusion)方法。我們的PLIVox編碼場景先驗同時考慮了局部幾何和由深度神經網絡參數化的不確定性。有了這樣深度先驗知識,我們能夠進行線上隱式三維重建,並達到最先進的網絡攝影機軌跡估計精度和對映質素,同時實作了更好的儲存效率。
相關論文:DI-Fusion: Online Implicit 3D Reconstruction with Deep Priors30. ChallenCap: Monocular 3D Capture of Challenging Human Performances using Multi-Modal References
捕捉具有挑戰性的人體運動對於許多套用來說都至關重要,但它在單目環境下具有復雜的運動模式和嚴重的自遮擋。在本文中,我們提出了ChallenCap。這是一種基於樣版的方法,其借助多模態參考和一個新穎的學習和最佳化框架來使用單個RGB網絡攝影機捕捉具有挑戰性的3D人體運動。我們提出了一種混合運動推理平台,其使用時間編碼-解碼器從成對稀疏檢視參考中提取運動細節,並使用運動鑒別器以數據驅動方式來提取特定的運動特征。透過利用從監督的多模態參考中學習到的運動細節,以及從輸入影像參考中獲得的可靠運動提示,我們進一步采用穩健的運動最佳化階段來提高追蹤精度。
相關論文:ChallenCap: Monocular 3D Capture of Challenging Human Performances using Multi-Modal References31. Zillow Indoor Dataset:Annotated Floor Plans With 360o Panoramas and 3D Room Layouts
我們介紹了Z Zillow Indoor Dataset(ZInD):這個大型室內數據集包含1524個無家具家庭的71474幅全景圖。ZInD提供了三維房間布局、二維和三維樓層平面、樓層平面中的全景位置、以及窗門位置的註釋。 ground truth建設花了1500多個小時的註釋工作。據我們所知,ZInD是具有布局註釋的最大真實數據集。它的一個獨特內容是房間布局數據,其遵循真實世界的分布,而不是當前公共可用數據集中的主要長方體或曼哈頓布局。同時,本文所提供的比例尺和註釋對房間布局和樓層平面分析的有效研究有一定的參考價值。為了證明ZInD的優點,我們對單全景和多檢視配準的房間布局估計進行了基準測試。
相關論文:Zillow Indoor Dataset:Annotated Floor Plans With 360o Panoramas and 3D Room Layouts32. Ego-Exo: Transferring Visual Representationsfrom Third-person to First-person Videos
我們介紹了一種利用大規模第三人稱影片數據集對自我中心影片模型進行預訓練的方法。從純粹以自我為中心的數據中學習受到數據集規模和多樣性的限制,而使用純粹以外部為中心(第三人稱)的數據則會帶來很大的領域不匹配。我們的想法是,在第三人稱影片中發現隱訊號,而這些訊號可以預測關鍵的自我中心特性。將這些訊號作為預訓練過程中的知識提取損失,可以得到既能從第三人稱影片數據的規模和多樣性中獲益,又能捕獲顯著自我中心特性的表示的模型。實驗表明,我們的「Ego-Exo」框架可以無縫地整合到標準影片模型中。
相關論文:Ego-Exo: Transferring Visual Representationsfrom Third-person to First-person Videos33. Uncertainty-Aware Camera Pose Estimation from Points and Lines
Perspective-n-Point-and-Line(PnPL)演算法是現代機器人和AR/VR系統中的一個重要組成部份,其目標是從2D-3D特征對應中快速地、準確地、魯棒地定位3D模型。目前基於點的姿態估計方法只使用2D特征檢測的不確定性,而基於直線的姿態估計方法沒有考慮不確定性。在我們的設定中,特征的3D座標和2D投影都被認為是不確定的。我們提出了基於EPnP和DLS的PnP解算器,並用於不確定性感知的姿態估計。我們同時修改了僅運動束調整以考慮3D不確定性。我們在兩個不同的視覺裏程計數據集進行了詳盡的實驗。
相關論文:Uncertainty-Aware Camera Pose Estimation from Points and Lines34. High-fidelity Face Tracking for AR/VR via Deep Lighting Adaptation
3D影片化身可以透過提供壓縮、私密、娛樂和臨場感來增強通訊能力。特定於人像的圖片真實感3D模型對光照不魯棒,所以它們的結果通常會遺漏細微的面部行為,並導致偽影。這是所述模型的一個主要缺點。本文透過學習深度學習光照模型,並結合高質素的3D人臉跟蹤演算法來解決以往的局限性,並提供了一種從普通影片到3D照片逼真化身的精細人臉運動轉換方法。
相關論文:High-fidelity Face Tracking for AR/VR via Deep Lighting Adaptation35. Multi-View Multi-Person 3D Pose Estimation with Plane Sweep Stereo
現有的多視點多人三維姿態估計方法明確建立了多個網絡攝影機檢視的二維姿態檢測組的交叉視點對應關系,並解決了每個人的三維姿態估計問題。建立跨檢視通訊是多人場景中的一個挑戰,而不正確的通訊會導致多級管道的次優效能。本文提出了一種基於平面掃描立體影像的多視點三維姿態估計方法,其將交叉視點融合和三維姿態重建結合起來,實作了單鏡頭的三維姿態重建。具體地,我們建議對目標網絡攝影機檢視中每個二維姿勢的每個關節執行深度回歸。透過平面掃描演算法,多個參考網絡攝影機檢視隱式強制交叉檢視一致性約束,以便於精確的深度回歸。采用粗到細的方法,首先對人的水平深度進行回歸,然後進行人均關節水平相對深度估計。三維姿態是從給定估計深度的簡單反投影中獲得。
相關論文:Multi-View Multi-Person 3D Pose Estimation with Plane Sweep Stereo36. Neural Deformation Graphs for Globally-consistent Non-rigid Reconstruction
我們引入神經變形圖來進行非剛性物件的全域一致變形跟蹤和三維重建。具體地說,我們透過一個深層神經網絡隱式建模一個變形圖。這種神經變形圖不依賴於任何特定物件的結構,因此可以套用於一般的非剛性變形跟蹤。我們的方法在給定的非剛性運動物件的深度網絡攝影機觀測序列上全域最佳化這個神經網絡圖。基於顯式視點一致性和幀間圖面一致性約束來對底層網絡進行自監督訓練。另外,我們利用隱式可變形multi-MLP形狀表示法對物件的幾何結構進行了最佳化。我們的方法不假設連續的輸入數據,因此能夠對快速運動甚至暫時斷開的記錄進行魯棒跟蹤。我們的實驗表明,我們的神經變形圖在定性和定量上都優於最新的非剛性重建方法,重建效率提高了64%,變形跟蹤效能則提高了62%。
相關論文:Neural Deformation Graphs for Globally-consistent Non-rigid Reconstruction37. Lighting, Reflectance and Geometry Estimation from 360◦ Panoramic Stereo
我們提出了一種從360度影像中估計場景的高清晰度空間變化照明、反射率和幾何結構的方法。我們的模型利用了360度輸入觀察整個場景的幾何細節,然後聯合估計場景的物理約束內容。我們首先重建一個近場環境光來預測場景中任何三維位置的光照。然後,我們提出了一個深度學習模型,利用立體資訊來推斷反射率和表面法線。最後,我們結合光照和幾何體之間的物理約束來細化場景的反射率。
相關論文:Lighting, Reflectance and Geometry Estimation from 360◦ Panoramic Stereo
---
原文連結:https://
news.nweon.com/87275











