前言
對於近年來出現的各種AI芯片架構,大家經常看到的論述是:AI芯片由於是DSA(Domain Specific Architecture),因此在AI計算領域,擁有比GPGPU架構的芯片更好的能效。這個論述是真的嗎?那各種DSA的AI芯片,實際上究竟有多大的能效優勢呢?主要是從哪些方面提高了能效?「But at what cost?「(玩下BBC的梗)。這應該是一個大家非常感興趣的話題。我把平時看到的一些論文,會議PPT資料,官方文件,網站報道等公開的資訊總結起來,結合自己的經驗,加入一些對相關架構的看法,總結一下給感興趣的朋友。
能效,主要在用的是三個指標:
- TOPS/W ,這是一種靜態的能效參數,通常用Tensor(有的也包括Vector一起)的算力,和TDP的一個比值。TOPS和數據類別相關,推理常用INT8和FP16,不同架構的配比還不一樣,1:1,2:1,4:1比較常見。
- Perf/W ,是實際的端到端的模型推理或訓練的結果和TDP功率的比值。和TOPS/W相比,它包含了整個軟件棧和AI芯片硬件的整體效能,具有更實際的意義。文中主要用 IPS/W 表示。
- Perf/TCO ,從系統層面,考慮效能和總的成本的比,其中成本包含除Power以外的其他相關的整體系統成本,實際主要是數據中心使用得考慮得比較多。比如加上CPU,Video,機櫃組成的全系統成本。
但實際上,我經常在想,作為一個架構師,應該考慮的是更加廣義上的Perf/TCO。這個C(cost)還要包括這個架構的實作(軟硬件開發實作,具體就是硬件開發難度,軟件棧,編譯器,業務邏輯模型支持難度等)。扯遠了。。。
這裏主要分析推理的能效,使用TOPS/W作為基礎,這是比較容易首先獲得的數據,各個芯片一般都有公布,所以可以對比。另外,由於Perf/W能更好的反應實際效能和功率的關系,如果能得到這個數據,我會更加偏向於使用這個數據。
架構選擇上,以GPGPU,Nvidia A100作為對比基礎,分別選擇了Google TPU(Tensor大核代表),Groq TSP(流水線型代表),Tenstorrent Grayskull(manycore小核代表),Qualcomm Cloud AI 100 (DSP+DSA混合),OPPO MariSilicon X(影像專用架構代表)。盡量避免國內同行架構,話題太敏感。另外數據是公開的數據,有些源頭不大一致,不過差距不大,不影響分析。
GPGPU
選NV Ampere A100作為代表,7nm,PCIe,40G HBM2e的版本250W。TOPS/W方面,INT8 : FP16 = 2 : 1。INT8 624TOPS/250W = 2.5TOPS/W 。FP16, (312+78)TOPS/250W = 1.5TFOPS/W 。
Perf/W方面,根據MLPerf結果,Resnet50 32778IPS/250W = 130 IPS/W 。Bert base,2836 IPS/250W = 11 IPS/W 。
根據我的判斷,MLPerf上的結果,應該是沒有加入A100 高級特性的成績,比如:Sparsity,residency control,Compression等。都用起來的話,應該還是小幾十個點的提升。
其他家的GPGPU就不拿出來看了,大致差不多。AMD的MI更註重高精度的AI,因此在INT8方面投入不多,而且也沒有上面的提到的為AI所加的高級特性。
Google TPU
Google是AI芯片裏走在最前面的公司,從第一代開始業務落地,當前已經是第4代了。而且不想一般公司,Google非常開放,把每一代的架構,理念甚至一些詳細設計,參數,結果數據等都公開出來,非常大氣。這些詳細的資料,讓我們從第一代的脈動矩陣設計理念和細節開始,看著它怎麽一步一步擴充套件到訓練,然後在第4代推理/訓練雙產品線。它的架構變化過程,包括脈動矩陣的變化,vector/scalar的變化,memory系統的變化,都是非常有益架構師學習和思考的。所以非常感謝Google的大氣!
TPUv4i比較適合拿來對比,因為同是7nm而訓練的v4還沒看足夠資訊。不過TPU主打BF16,它的INT8和BF16是相同的算力。所以INT8的TOPS/W很低,138/175= 0.8 TOPS/W ,當然BF16也能保持在0.8TOPS/W,不過還是低於NV A100的。
從Perf/W上看,沒有看到直接數據,只有和T4的對比,效能差不多是T4的兩倍,Perf/W和T4差不多。從T4推算,Resnet50在
70 IPS/W
上下,Bert在
5 IPS/W
上下。都不及升級後的A100。
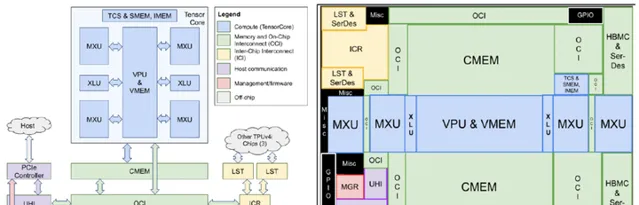
為什麽TPUv4i的效能和能效不如A100 GPGPU?幾點想法:
雖然TPU的超大核的設計,大部份模型可以單核搞定,但也應該做到一定的平衡,支持一定程度的model splitting,也就是小核心的tiling。其實它的TPUv4就是單芯片雙核心。如果TPUv4i也差不多類似的組合,128CMEM給兩個核心共享或者每個64M,BF16的TOPS/W差不多能到276/250=1 TOPS/W。和A100就更接近了。
Groq TSP
Groq TSP和Google TPU有些近親,因為Groq是由TPU團隊的八位核心開發者離職後於2016年創辦的。所以雖然兩者的核心思路完全不一樣,但給人的感覺差不多。嗯,就像西餐裏的牛排和雞胸,簡單,量大。。。,簡單是Groq自己宣傳也這麽說,你看圖
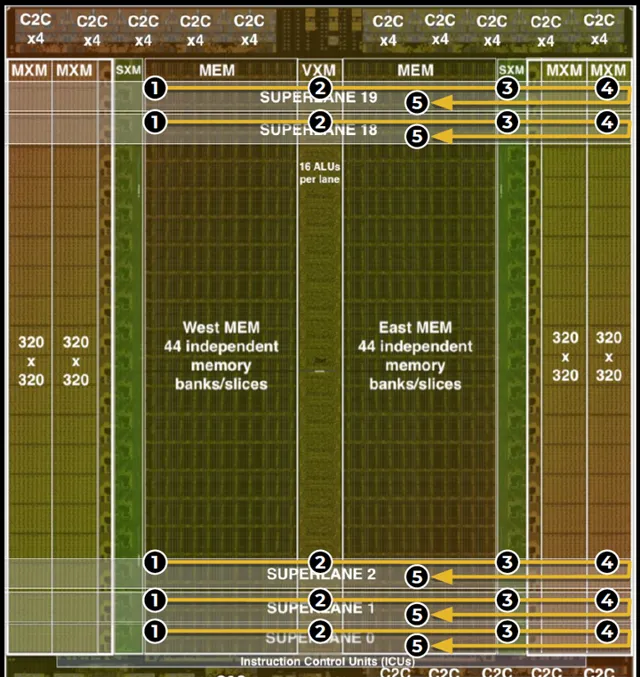
TOPS/W數據,INT8 : FP16是4:1,INT8 820TOPS/300W= 2.7 TOPS/W ,而FP16只有205TOPS/300W= 0.7 TOPS/W ,和TPUv4i還真是差不多了呢。不過它的工藝上要落後吃點虧。
只不過整體的TOPS很高,特別是INT8的,曾經宣傳1000TOPS。220MB SRAM可以容納下Bert base。不過也是利用率很低,實際效能Resnet50 20400 IPS/300W= 68 IPS/W ,沒看到Bert的成績,說明之前軟件還不成熟。總體上說,能效上看起來和TPU差不多。
其實兩年前就在關註TSP,特別是ISC2020上它的詳細介紹,一個原因就是它的算力/功耗和含光800NPU差不多,而且有一些理念也類似。有些方面它還支持更多的特性,比如C2C互聯。但對比Resnet50效能,會發現比含光差得比較多,不到含光的1/3。對比含光的公開的PPT,就會發現主要的區別:TSP的pipeline太過於簡單,和Google TPU的bundle類似,只有大概一個matrix+2個vector的操作,這樣就需要更頻繁的去MEM裏讀/寫數據,導致了3倍的差距。從某個角度看,他們有點限制在了TPUv1的思維裏,換了湯(計算/儲存組織方式,ISA)沒換藥(實質控制和數據流),只不過TPU往訓練方面功能性發展,而TSP往Producer-consumer的流水線固定pipeline模式最大化TOPS方向發展。
想想這是人之常情,很難完全丟掉原來的思維模式。但從另一個角度說,TSP架構還能有比較大的提升空間(比TPU脈動矩陣還是要靈活些),感興趣的話可以去看看它的論文和ISC2020的PPT,拓展一些思路。
下面看看不同的架構模式:manycore
Tenstorrent Grayskull
知乎上挺多人談起過這個芯片和架構,Tenstorrent 2016初就成立了,Jim Keller加入,名聲大作。在它的宣傳中,已經不是強調」 Spatial computing 」,這個理念不新鮮,已有挺多的芯片了。它強調的是」 The first conditional execution architecture for AI 「。猜測Jim加入應該也是被這個架構的原始理念所吸引,然後可以在後續的架構和高級特性上充分發揮了一把,這個架構的靈活度和發揮空間非常大。
先把能效數據列一下:
TOPS/W方面,8bit,368TOPS/75W= 4.9 TOPS/W ,FP16,92TOPS/75W= 1.2 TOPS/W 。可以看得出,16bit數據和A100差不多,但8bit基本上是A100的兩倍。看了一下第三代的訓練Wormhole在FP16的算力和功耗都x2了,所以還是相同的184TOPS/150W= 1.2 TOPS/W。
Perf/W方面表現更出色。Resnet50 22431 IPS/75W=
300 IPS/W
,Bert 2830 IPS/75W=
38 IPS/W
。下圖是它的宣傳文用到的Resnet50的能效對比圖。
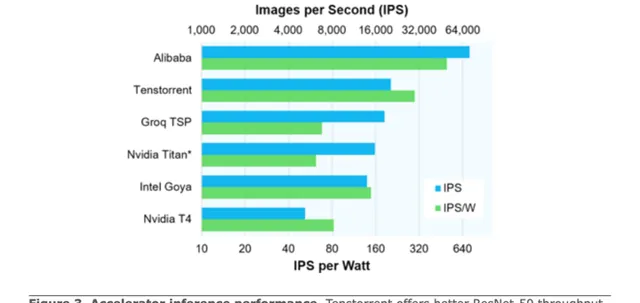
Perf/W的數據對比,基本上是A100 GPGPU的3倍上下。這個結果是不包含conditional execution的最佳化提升的,可以假定需要做的計算量和GPGPU差距不大,那它的能效提高,應該是由軟硬件結合的,以可配置Spatial Dataflow的方式獲得的。具體的說,
這裏各家的做法可能有些區別,和各自的tiled core的微架構相關。Graphcore IPU的應該是最成熟,在中國業務落地做得最好的。有熟悉的同學方便的話可以分享一下。從GPGPU的角度,硬件排程block/warp,以硬件資源和時間利用率為主要因素,很難考慮cache locality方面。想要好的memory(shared+cache)使用,大部份依靠kernel寫法,以及task graph,residency control等結合起來,效果編譯器能幫的比較少。而且由於GPGPU的shared memory + residency memory都不大,操作空間很有限。而manycore架構多了編譯器根據graph,考慮計算/儲存/依賴等因素來最佳化布局,分配排程資源,提高能效。
Tenstorrent更大膽的創新是,聚焦在Dynamic Execution,看起來比其他家做的更激進,能大幅地減少一些模型的計算量。Dynamic Execution包括幾個軟硬件結合的最佳化:control flow, compression, sparsity, dynamic precision and conditional execution。
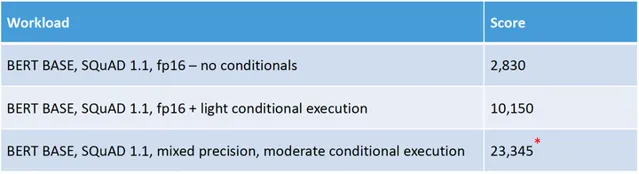
Tenstorrent透過core內的5個RISC-V CPU做復雜的控制流,實作了細粒度的條件執行,動態稀疏等特性,讓一些比較稀疏模型的能效可以在軟件最佳化配合下提高一個數量級。特別是套用在Bert中效果非常好,因為模型是固定sequence length,但實際輸入長度短很多,有很多0。但conditional execution的套用場景也應該比較有限(看起來比如Resnet50這類網絡可能就收益很小)。而且軟硬件的復雜度感覺很大,我是基本想不清楚它的一整套工作流程,比如這5個CPU和主compute單元之間的編程和執行互動機制。後面繼續學習,說不定能產生一些對專案有用的靈感。
關於這些創新,要說還是有些工程上的疑問,一個是精度,推理結果的精度還是很重要的,我們接觸下來的客戶大都很在乎這個。一個是適用性,就是有多少套用收益。還有一個是復雜度,感覺用於訓練復雜度還會劇增,復雜度對應的是人才,資金和時間。在了解RISC-V CPU和計算模組的協作方式後,我會去嘗試寫寫這種模式下的偽代碼,琢磨一下軟件棧的實作,看能不能預估一下工程上的難度。
看了幾個國外比較有特色的AI芯片架構。基本上startup比較傾向於創新架構,他們也有比較充分的時間去慢慢打磨架構。像Groq/Tenstorrent,5年多時間還沒有業務落地。而相對傳統的企業,因為有市場的壓力,有每年的叠代的要求,所以會選擇一些比較穩妥的架構逐步演進方式,比如下面的高通。
Qualcomm Cloud AI 100
Qualcomm AI加速引擎發展到現在已經是第7代了。從最原始的Hexagon DSP,一代一代的,從VLIW,HW multi-threading,然後加Vector SIMD,然後加上Tensor Unit,配上比較大的VTCM (Vector Tightly Couple Memory,也就是shared memory)。和NV/AMD發展路線圖差不多,但聚焦在移動和推理,所以也有區別。一路下來,高通AI引擎發展迅速,手機8Gen1 NPU效能已經遙遙領先,更是快速殺入數據中心和車載芯片市場。特別是在車載方面,好多汽車大廠合作,後起之秀啊!
以Cloud AI 100為例看看Qualcomm的AI引擎,能效表現和Tenstorrent Grayskull差不多,還稍微好一點。
TOPS/W方面,INT8 400 TOPS/75W= 5.3T OPS/W ,FP16 200 TOPS/75W= 2.7 TOPS/W , 是2:1的比例,因此FP16方面比Grayskull高。
Perf/W方面,直接上圖,它可能用的是實際功耗,我換成TDP,Resnet50 22252 IPS/75W=
297 IPS/W
,Bert 3688 IPS/75W=
49 IPS/W
。註意Bert使用的是混合精度。這個能效很高了,低功耗版本的還要更高。
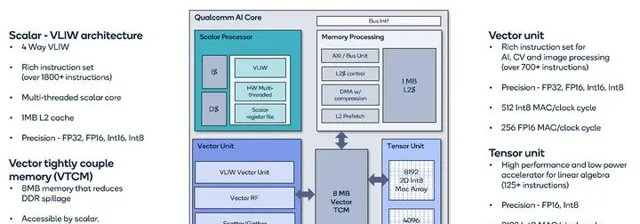
粗看它的架構設計,大概會覺得沒什麽特別的,scalar+vector+tensor+shared memory。就是軟硬件的長時間打磨,很多細節一點一點累加起來才能得到好的能效。詳細的材料可以看它的介紹,很多東西和GPGPU其實是差不多的。那為什麽它的能耗表現比NV A100要好很多(2-3倍)?至少幾個可見的因素:
當然還有就是NV GPGPU有更多的特性和使用場景,會增加面積,消耗和犧牲能效。另外Qualcomm這個對軟件要求也會比較多。需要針對不同結構的模型細調。但看AI benchmark的分數,Snapdragon 8 Gen 1的得分已經是麒麟9000達芬奇的2.5倍,因此Qualcomm的軟件棧應該還是比較成熟了。
OPPO MariSilicon X
最後關註一下DSA架構的另一個方向,就是 極致的Domain Specific 。以OPPO剛釋出的MariSilicon X為例,它是一個影像專用NPU。
直接看報道的數據,
TOPS/W數據:18 TOPS,
11.6TOPS/W
。這個靜態數據已經是A100的4倍多,Qualcomm AI 100的2倍多。
Perf/W方面,還沒有具體的數據,專用的影像NPU,肯定不是跑Resnet50/Bert了。報道裏提到一個有意思的對比,用的是OPPO自研的AI降噪模型, Find X3 Pro(驍龍888)[email protected],馬利安納[email protected],馬利安納的效能達到20倍,能效達到40倍。

我來理解的話,TOPS/W的兩倍提升比較好理解,來源於它特定的業務流水線:
至於20倍的效能,我想就來自於專用演算法了。他提到的是自研降噪模型,要不就是用了比較特別不適合矩陣計算的算子,要不就是用了很多大尺寸摺積,比如AI benchmark裏有一個Image Deblurring的PyNET模型(PyNET:Replacing Mobile Camera ISP with a Single Deep Learning Model )。然後MariNeuro計算單元裏直接實作了特殊的摺積演算法,比如變換域的摺積演算法等等,國內做相關演算法硬件的人還是挺多的。所以它實際的計算量就減少了很多很多。有20倍的效能提升就不足為奇了。
對於20倍效能,40倍能效的提升,讓一個幾乎不能套用的演算法能用起來(>30FPS),所以額外增加了一個芯片,這個代價似乎是值得的?但這個實質的對比是,有沒有一個能在通用NPU,比如最新的Qualcomm AI core上跑出差不多效果(可以差一點)的 其他演算法模型 做替代?如果有,就是獨立芯片就沒太大的意義。不過是在剛開始還沒足夠能力做一個完整手機SoC的情況下,先跨一小步,做一個技術積累。
總結
本想簡單地比較比較各種架構的能效,發現寫起來就剎不住。稍微總結一下我的觀點,純粹個人見解,歡迎討論:

- TOPS/W稍微有些欺騙性,比如同一架構透過核心數和電壓等調節,可以獲得兩倍以上的TOPS/W指標。它和能效不能線性掛鉤,受到計算單元利用率和演算法的影響比較大。
- Perf/W相對來說更有意義。它體現了完整的端到端架構,軟件和硬件實作的能效高低。
- NPU和TSP的架構沒能顯示出比GPGPU更好的能效,體現了這種架構做高能效是比較難的。當然不是說這種架構都不能超過GPGPU,至少類似架構的含光800NPU在Resnet50能效上是3倍於A100的。
- Qualcomm Cloud AI 100和Tenstorrent grayskull能效比較接近,是A100的2-3倍。它們都非常依賴於編譯器和軟件棧的最佳化以配合才能保證高能效。但它們主要的實作思路不一樣。
- Qualcomm Cloud AI 100主要是透過推理專用的DSP+DSA架構最佳化,結合軟件棧的Depth first scheduling,將一個tiled的多層算子fused執行,即減少了memory存取,又增加了pipe的並列度。
- Tenstorrent grayskull主要透過Spatial Dataflow的方式,將Graph的多層算子最佳化布局在tiled Tensix core,將計算以mini-tensor的粒度打包傳輸(broadcast),同樣的能實作了類似Depth first scheduling的算子fused效果。更有創新的是,透過core內RISC-V CPU實作復雜的控制流,實作了細粒度的條件執行,動態稀疏等特性,讓一些比較稀疏模型的能效可以在軟件最佳化配合下提高一個數量級。
- OPPO Marisilicon X透過影像專用,演算法專用,對特定的演算法是能達到幾十倍的能效提升。
最後再展開一點,基於密集矩陣計算的數碼電路芯片的AI加速架構,在能效上的上限比較低,相同工藝上看,看起來在GPGPU的5倍以下。這還是有很多的其他代價的前提下才能得到的,包括更少的功能和特性,更低精度,更復雜的編譯器,軟件棧等。
想要突破上限的兩種思路:
- 減少運算量,
2. 改變計算電路模式,還在探索階段。
其實不論選擇哪一種架構方向,都是要靜下心來慢慢地打磨架構,硬件和軟件。能效是一點一點積累的,很難有捷徑。
聲明:文章僅表達本人個人觀點, 數據來與網上公開文件 。











