編輯:編輯部 HYZ
【新智元導讀】 就在剛剛,RTX 5090震撼釋出,國行版定價16499元!同時震撼亮相的,還有全球最小AI超算Project Digits,在辦公桌上就能跑出數據中心級算力!這一刻老黃擺出別致pose,吸引了全球目光。
他來了,他來了,今天,老黃穿著嶄新的夾克出場了。
剛剛的CES大會上,老黃宣布RTX 5090正式釋出。

50系列GPU,價格如下——
RTX 5090:1999美元 / RTX 5090 D:16499元
RTX 5080:999美元 / 8299元
RTX 5070 Ti:749美元
RTX 5070:549美元

RTX 5090系列和RTX 5080將於1月30日上市,RTX 5070 Ti和RTX 5070將於2月上市,RTX 50系列筆記電腦將於3月推出
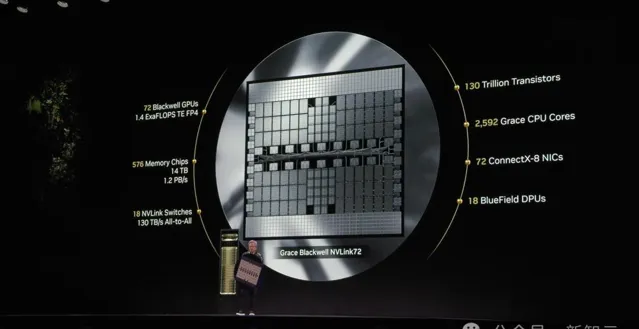
緊接著,老黃以一個別致的「美國隊長」造型贏得全場喝彩,並 揭秘了全新的 數據中心超級 芯片—— Grace Blackwell NVLink7 2。
它配備了72個Blackwell GPU、1.4 exaFLOPS 算 力和130萬億個晶體管, 目標是超越世界最快超算。

隨後,全球首款真正意義上的桌面超算——Project Digits震撼登場。
這款全球最小AI超算,售價僅3000美金。
有了它,200B大模型在辦公桌上就能跑了。
也就是說,它只占用你桌面一個咖啡杯的體積,卻能提供數據中心級的算力!
搭載全新GB10 Grace Blackwell超級芯片的Project Digits,能在FP4計算精度下,提供高達1 PFLOPS的效能。
老黃預言:在未來,每個數據科學家、研究者和學生的桌子上,都會有一台Project Digits這樣的個人AI超算。
AI時代,將屬於每一個人。
RTX 5090首秀,DLSS 4也來了
經過數月的泄密和小道訊息,全新一代的RTX Blackwell GPU終於正式亮相了。
首先來看一波效能參數:
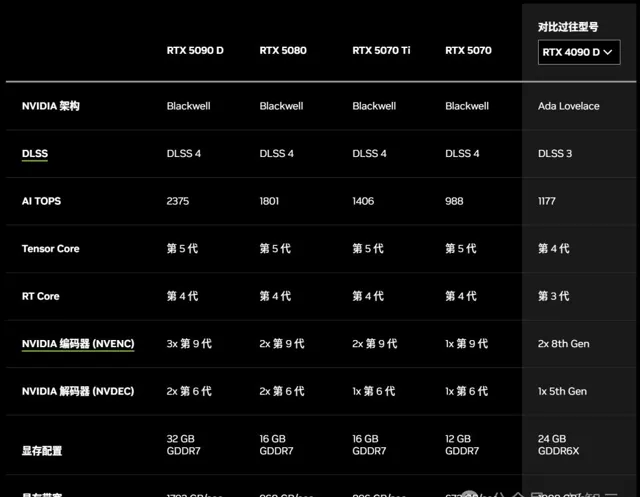
920億個晶體管
4000 TOPS的AI算力
380 TFLOPS的光追算力
125 TFLOPS的著色器算力
32GB的GDDR7視訊記憶體
1792GB/秒的記憶體頻寬
高達21760個CUDA核心
值得註意的是,RTX 5090 D的AI算力只有2375 TOPS。
不過,雖然比滿血版的5090少了一半,但至少比4090 D高了一倍。

如此豪華的配置,再加上DLSS 4和Blackwell架構的加持,RTX 5090的效能直接達到了RTX 4090的兩倍之多。
然而,這也意味著它的功耗會很高,(RTX 5090的總顯卡功耗為575瓦特,推薦電源供應器功率為1000瓦特)。
demo顯示,在RTX 5090上執行【賽博龐克2077】時,啟用DLSS 4後達到了238幀每秒,而在RTX 4090上啟用DLSS 3.5時,只有106幀每秒。
RTX 5080比RTX 4080快一倍,配備16GB的GDDR7視訊記憶體,記憶體頻寬為960GB/秒,CUDA核心數量為10752個。
RTX 5070 Ti配備16GB的GDDR7視訊記憶體,記憶體頻寬為896GB/秒,CUDA核心數量為8960個。
RTX 5070則配備12GB的GDDR7視訊記憶體,記憶體頻寬為672GB/秒,CUDA核心數量為6144個。
老黃甚至宣稱,RTX 5070將以549美元的價格,提供RTX 4090級別的效能,這無疑是由於DLSS 4的提升。
左右滑動檢視
另外,老黃還展示了RTX Blackwell GPU,並進行了一場即時渲染演示。
他表示,「新一代的DLSS不僅僅是生成幀,它還能預測未來。我們用GeForce推動了AI,而現在AI正在革新GeForce。」
Nvidia全新的RTX神經著色器可用於壓縮遊戲中的紋理,而RTX神經面孔則利用生成式AI來提高面部質素。
下一代DLSS包含了多幀生成技術,可以在每個傳統幀的基礎上生成最多三個額外的幀,使幀率比傳統渲染提高了多至8倍。
並且,DLSS 4還包括了Transformer在即時套用中的使用,能夠提升影像質素、減少鬼影效果,並在動態畫面中增加更高的細節。

值得一提的是,輝達在RTX 50系列的Founders Edition上采用了全新設計。
配備了兩個雙流量風扇、3D均熱板和GDDR7視訊記憶體。RTX 50系列所有顯卡均支持PCIe Gen 5,並配有DisplayPort 2.1b介面,能夠驅動最高8K分辨率和165Hz的顯視器。
令人驚訝的是,RTX 5090 Founders Edition是一款雙插槽顯卡,能夠適配小型機箱,跟RTX 4090的尺寸相比,這是一個巨大的變化。

輝達高級科學家Jim Fan,發現了老黃演講中關於圖形技術的「華點」。
你們都在期待RTX 5090的釋出,關註它的規格參數,但你們是否真正理解黃仁勛關於圖形技術的說法?
新顯卡使用神經網絡來生成遊戲中90%以上的像素!
傳統的光線追蹤演算法只渲染約10%的內容,相當於一個「粗略的草圖」,然後由生成式模型即時地在一次前向傳遞中填充其余的細節。
女士們先生們,AI就是新一代的圖形技術。

50系顯卡首秀之後,老黃提到「Scaling law仍在繼續」:
第一個scaling law是預訓練
第二個scaling law 是後訓練
第三個scaling law是測試時計算
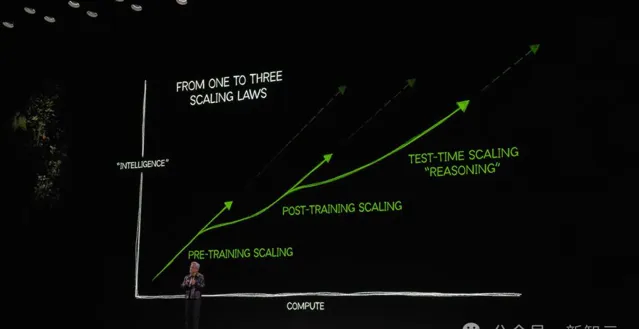
scaling law不斷演進,推動著AI對計算的巨大需求。
令人驚嘆的是,包括微軟、Meta、xAI約15個超算中心,都已經裝上了Blackwell GPU。

接下來,他又提到了智能體AI,是測試時scaling完美的套用範例。
同時,他還宣布推出了一系列開放特許的基礎模型—— Llama Nemotron,能夠在各類智能體任務中提供極高的精度。
老黃稱,「AI智能體可能是下一個機器人產業,可能是價值數萬億美元機會」。
左右滑動檢視
此外,輝達NIM Blueprint即將在PC上線,借助這些藍圖,開發者能夠基於 PDF 文件建立播客、生成由 3D 場景引導的令人驚艷的影像等。
左右滑動檢視
桌面級AI超算,可跑4050億LLM
CES大會收尾前,老黃還揭開了一款革命性的壓軸產品——Project Digits,一台真正意義上「桌面超級電腦」!
它專為AI開發者、數據科學家、學生等,那些從事AI工作的專業人士而設計。

這款小型電腦是「全球最小」可執行200B參數模型的AI超級電腦,售價3000美金(約21986元)。
正如老黃所展示的那樣,這款緊湊型台式系統提供強大算力的同時,僅占用了極小的桌面空間——
寬度大約相當於一個普通咖啡杯的長度,高度也僅有其一半左右。
想象一下,你的辦公桌上放置一個微型器材,卻能提供堪比數據中心級算力。
這就是Project Digits帶來的革命性突破!
Project Digits搭載了全新的GB10 Grace Blackwell超級芯片,能在FP4計算精度下,提供高達1 PFLOPS(千萬億次浮點運算/秒)的AI效能。

這顆強大的芯片,還搭載了20個ARM核心的Grace CPU。CPU和GPU透過NVIDIA NVLink C2C技術實作高速互聯。
每個Project Digits都配有128GB低功耗統一的高一致性記憶體,以及最高4TB的NVME儲存。
有了它,開發者可以直接在桌面上,執行高達2000億的大模型。
令人驚喜的是,透過ConnectX網絡芯片,可以將2台Project Digits超級電腦互聯,能夠執行高達4050億參數的模型。
此外,Project Digits預裝了NVIDIA DGX基礎作業系統(基於Ubuntu Linux)和NVIDIA AI軟件棧,為開發者提供了一個開箱即用的AI開發環境。
開發者可以隨插即用,快速啟動AI專案的開發。
對於數百萬開發者來說,它將成為一款改變遊戲規則的創新產品。
尤其是,Project Digits特別適合處理,需要依賴雲端運算/數據中心資源才能執行的AI大模型。
這款桌面AI超算套用場景非常廣泛,AI模型實驗和原型開發、AI模型微調和推理(用於模型測試或評估),以及本地AI推理服務(如聊天機器人或程式碼智能助手)。
此外,數據科學家還以利用系統執行NVIDIA RAPIDS,直接在桌面就能高效處理大規模數據科學工作流。

有了輝達AI完整技術棧的加持(框架、工具、API),Project Digits成為了邊緣計算套用的理想開發平台,特別適用於機器人技術、VLM等領域。
Project Digits的出世,標誌著個人AI計算進入了一個全新的時代。
它能讓全世界開發者能夠在自己的辦公桌上,執行超大規模的AI模型,補充了現有的雲端運算資源,極大地提升了AI開發效率。
物理AI新紀元,世界基礎模型全開源
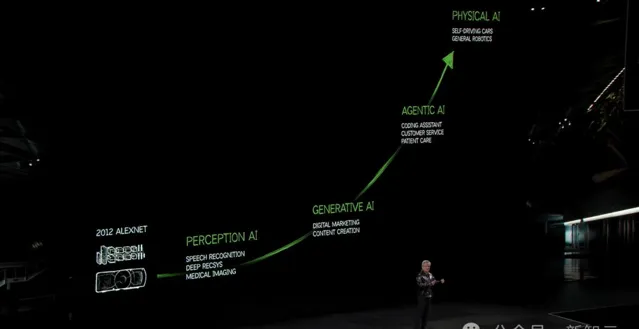
智能體AI之後,老黃又將話題引到了「物理AI」。在他看來,「AI的下一個前沿就是物理AI」。
大模型的工作原理是,根據提示一次生成一個token產生輸出。
如果這個上下文變成了現實周圍環境,如果提示問題變成了請求,大模型需要從生成「內容token」轉變為生成「動作token」。
而現在,我們需要做的是建立有效的「世界模型」,而不再是GPT系語言模型。
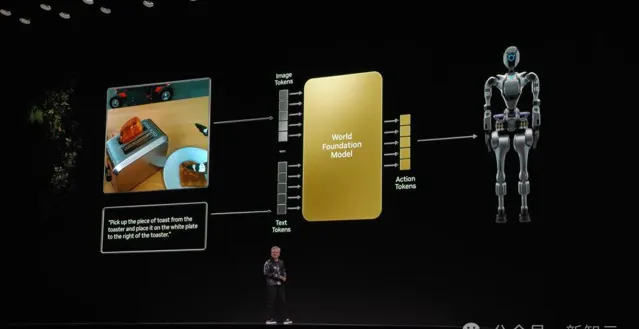
這個「世界模型」必須理解世界的語言,必須理解物理動力學,比如重力、摩擦,必須理解幾何和空間關系,理解因果關系,理解物理永恒性......
CES現場,老黃官宣了革命性世界基礎模型開發平台——Cosmos,旨在理解物理世界。
它基於2000萬小時數據集完成訓練,能夠將文本、影像、影片作為輸入,可以生成虛擬世界狀態、影片。
該平台包含多個功能模組,比如擴散模型、自回歸模型、影片分詞器,開發者可以根據具體需求選擇使用。
值得一提的是,老黃現場直接將Cosoms全部開源,Nano、Super、Ultra全部公開可下載。
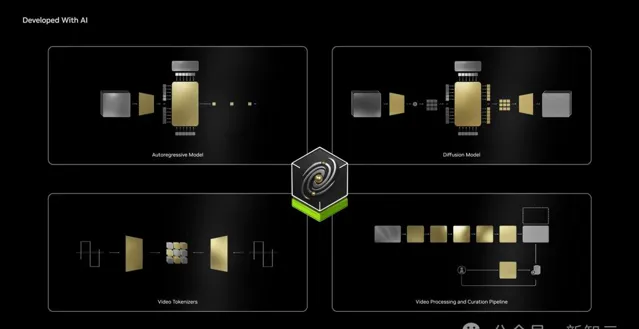
此外,Cosoms還能與Omniverse兩者結合使用,能夠提供一個物理真實的多元生成器。
也就意味著,物理模擬世界的一切,都可以透過Cosoms一次性生成出來。
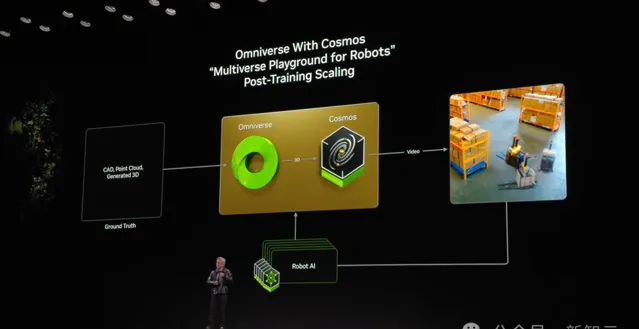
老黃還提到了三台電腦——一台DGX用來訓練AI,另一台AGX用來部署AI,最後一台便是Omniverse+Cosmos。
若是連線前兩者,我們就需要一個數碼孿生。
老黃認為,「未來,每一個工廠都有數碼孿生,你可以將Omniverse 和Cosoms結合,生成一大堆未來場景」。
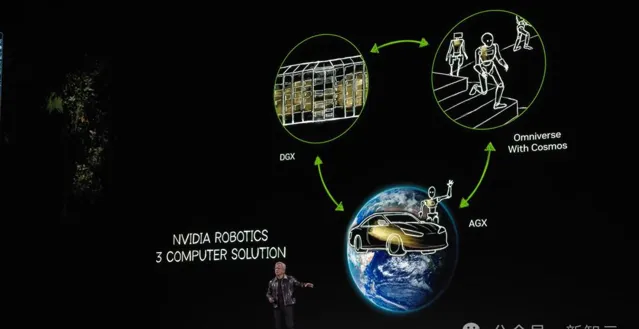
自動駕駛汽車+機器人
制造自動駕駛汽車,就像機器人一樣,同樣需要這三台電腦。
截至目前,每年生產1億輛車,全球有數十億輛車,都將在未來逐步變成高度自動化、完全自動化駕駛系統。
老黃預測道,這將會成為首個價值數萬億美金的機器人產業。
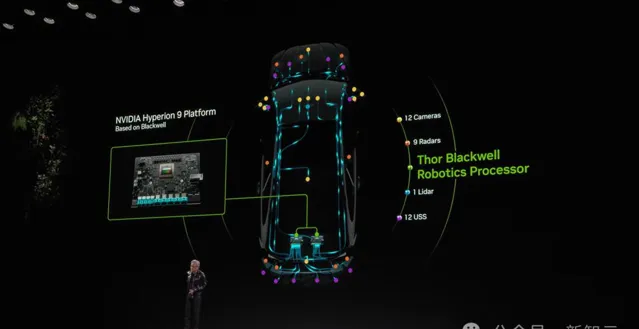
同時,他釋出了下一代汽車處理器——Thor,處理效能比上一代Orin飆升20倍,而且也是通用機器人處理器。

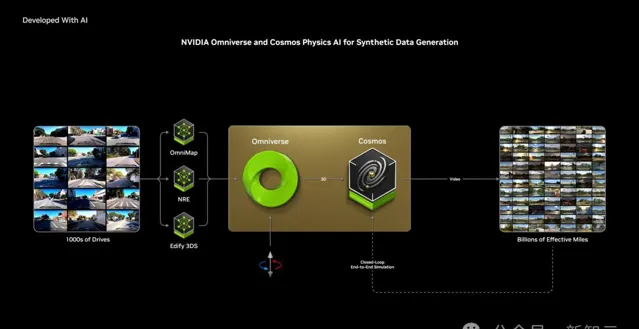
那麽,在自動駕駛背景下,Omniverse+Cosoms能做什麽?
它能夠生成無限駕駛場景,加速短尾、無法收集數據等場景的自動駕駛的研發。
接下來,老黃召喚出所有機器人登台,並表示「通用機器人的chatGPT時刻到來」。
他稱,「目前有三種機器人——智能體AI、自動駕駛汽車、機器。如果我們擁有解決這三個問題技術,機器人時代就在眼前」。
在釋出會最後的最後,老黃總結道,我們現在共有三台全新Blackwell系統正在生產中。
除了Grace Blackwell NVLink72超算,還有一個是物理AI基礎模型,另一個是在智能體AI上研發的三類機器人。

而就在剛剛,輝達股價再次創下歷史新高。
一夜間,輝達股價大漲超3%,以每股超150美元的價格收盤,超過11月創下的每股148.88歷史最高收盤紀錄。
現在,如今,輝達的最新估值已經達到了3.66萬億美元。












