編輯:英智 桃子
【新智元導讀】AI已經能夠自主科研了!AMD霍普金斯祭出「智能化實驗室」不僅能獨立完成文獻調研到論文撰寫全流程工作,還能將研究成本暴降84%。
AI離自主科研,真的越來越近了!
最近,Hyperbolic聯創Jasper Zhang在采訪中稱,AI智能體已經可以自主租用GPU,利用PyTorch進行開發了。
其實,在科研方面,AI智能體也是一把能手。
只要腦海裏有科研的奇思妙想,一份高質素的研究報告甚至連程式碼,都能很快呈現在你眼前。
這不,AMD聯手霍普金斯打造出的一款「智能體實驗室」,瞬間在全網爆火。
這個超牛的AI系統,代號叫做Agent Laboratory,全程靠LLM驅動!


從文獻綜述開始,到開展實驗,再到最後生成報告,就像一位不知疲倦的科研小能手,一站式搞定整個科研流程。
Agent Laboratory由LLM驅動的多個專業智能體組成,自動處理編碼、文件編寫等重復耗時的任務。
在研究的每個階段,使用者都可以提供反饋與指導。Agent Laboratory旨在助力研究人員實作研究創意,加速科學發現,提高研究效率。

論文地址:https://arxiv.org/abs/2501.04227
研究發現:
-
由o1-preview驅動的Agent Laboratory產出的研究成果最佳;
-
與現有方法相比,Agent Laboratory生成的程式碼達到先進水平;
-
人類在各階段提供的反饋,顯著提升了研究的整體質素;
-
Agent Laboratory大幅降低研究費用,與傳統研究方法相比,費用減少了84%。
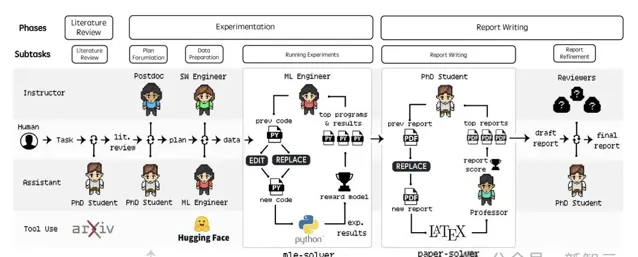
Agent Laboratory有三個關鍵階段:文獻綜述、實驗設計和報告撰寫。
由LLM驅動的專業智能體(如博士、博士後等)協同工作,承擔文獻綜述、實驗規劃、數據準備和結果解釋等工作。這些智能體還會整合arXiv、Hugging Face、Python和LaTeX等外部工具,來最佳化結果。
文獻綜述
文獻綜述階段,旨在收集、整理與給定研究主題相關的論文,為後續研究提供參考。
在這個過程中,博士智能體借助arXiv API檢索相關論文,並執行三個主要操作:摘要、全文和添加論文。
摘要:從與初始查詢相關的前20篇論文中提取摘要
全文:提取特定論文的完整內容
添加論文:將選定的摘要或全文納入到文獻綜述
該過程並非一次性完成,而是叠代進行。智能體多次執行查詢,依據論文內容評估其相關性,篩選出合適的論文,構建全面的文獻綜述。
當透過「添加論文」命令達到指定數量(N=max)的相關文獻後,文獻綜述才會完成。
實驗環節
實驗環節包括制定計劃、數據準備、執行實驗和結果解釋。
制定計劃
在這個階段,依據文獻綜述和研究目標,智能體需要制定一份詳盡且可行的研究計劃。
博士和博士後智能體透過對話協作,明確研究方法,比如要采用哪些機器學習模型、使用什麽數據集,以及實驗的主要步驟。
達成一致後,博士後智能體透過「計劃」命令送出該計劃,作為後續子任務的行動指南。

數據準備
在此階段,ML工程師智能體負責執行Python命令來執行程式碼,為實驗籌備可靠的數據。該智能體有許可權存取 HuggingFace數據集。
程式碼完成後,ML工程師智能體透過「送出程式碼」命令送出。在正式送出前,程式碼會先經過Python編譯器檢查,確保不存在編譯問題。若程式碼有錯誤,這個過程將反復進行,直至程式碼無誤。
執行實驗
在執行實驗階段,ML工程師智能體借助mle-solver模組來執行之前制定的實驗計劃。
mle-solver是一個專門的模組,主要功能是自主生成、測試以及最佳化機器學習程式碼,其工作流程如下:
A. 命令執行
在命令執行階段,初始程式是從預先維護的高效能程式中選取的。
mle-solver透過「REPLACE」和「EDIT」這兩個操作,對這個程式進行叠代最佳化。
「EDIT」操作會選定一系列行,用新生成的程式碼替換指定的內容。「REPLACE」操作會直接生成一個全新的Python檔。
B. 程式碼執行
執行程式碼命令後,編譯器會檢查新程式在執行時是否存在錯誤。
若程式成功編譯,系統會給出一個得分。若該得分高於現有程式,頂級程式列表就會更新。
要是程式編譯失敗,智能體就會嘗試修復程式碼,最多嘗試3次。如果修復失敗,就會返回錯誤提示,重新選擇或生成程式碼。
C. 程式評分
透過基於LLM獎勵模型對編譯成功的程式碼打分,評估mle-solver生成的機器學習程式碼的有效性。
該獎勵模型會依據研究計劃、生成的程式碼以及觀察到的輸出,對程式進行評分,評分範圍是0到1。得分越高,表明程式能夠更有效地實作研究目標。
D. 自我反思
無論程式碼執行成功與否,mle-solver都會依據實驗結果或者錯誤訊號進行反思。智能體會思考每個步驟,力求最佳化最終結果。
如果程式編譯失敗,求解器就會琢磨下一次叠代時該怎麽解決這個問題。要是程式碼成功編譯且有了得分,求解器則會思考怎樣提高這個分數。這些反思旨在幫助系統從錯誤中學習,並在後續叠代中提高程式碼質素和穩定性。
E. 效能穩定化
為避免效能出現波動,采用了兩種機制:頂級程式采樣和批次並列化。這兩種策略在探索新解決方案和最佳化現有方案之間找到平衡,讓程式碼修改過程更加穩定 。
頂級程式采樣:指維護一組評分最高的程式。在執行命令前,會從這組程式中隨機挑選一個,既能保證程式的多樣性,又能確保質素。
批次並列化:求解器每進行一步操作,都會同時對程式做出N次修改,然後從這些修改中挑選出評分最高的,去替換頂級集合裏評分最低的程式。
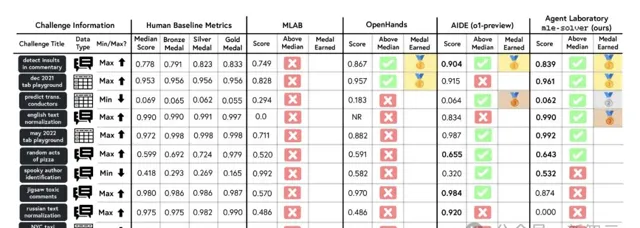
研究者在MLE-bench的10個ML挑戰中單獨評估了mle-solver。mle-solver始終優於其他求解器,獲得了更多獎牌,並在10個基準中的6個中達到了高於中位數的人類表現。
解釋結果
在此階段,博士和博士後智能體一同探討對mle-solver得出的實驗結果的理解,旨在從實驗結果中提煉出有價值的見解。
當他們就某個有意義的解釋達成共識,且認為該解釋能為學術論文增添價值時,博士後智能體便會透過「解釋」命令送出該解釋,為後續的報告撰寫提供支撐。
撰寫研究報告
報告寫作階段,博士和教授智能體負責把研究成果整理成一份完整的學術報告。這一過程借助名為paper-solver的模組,來叠代生成並完善報告。
paper-solver並非要完全取代學術論文的寫作過程,而是以人類易於理解的格式,對已完成的研究成果進行總結。
該模組生成的報告遵循學術論文的標準結構。paper-solver模組的工作流程如下:
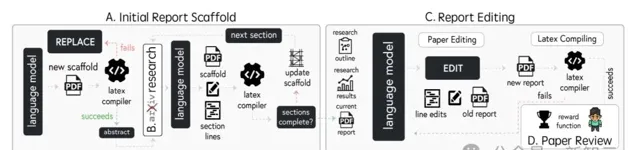
A. 初始報告框架
paper-solver的首要任務是生成研究論文的初始框架。該框架框架遵循學術規範,采用了LaTeX編譯所需的格式,生成的論文能直接進入審閱和修改環節。
B. ArXiv研究
paper-solver可按文獻綜述介面存取arXiv,探索與當前撰寫主題相關的文獻,還可以尋找可參照的論文。
C. 報告編輯
使用「EDIT」命令,對LaTeX程式碼進行叠代和修改,確保論文與研究計劃相符、論點清晰且滿足格式要求。
D. 論文審閱
這個系統借助基於LLM的代理,模擬科學論文的審閱過程,遵循NeurIPS會議的審稿指南對論文進行評估。
E. 論文完善
在論文修改階段,根據三個評審代理給出的反饋意見,博士智能體負責決定論文是需要修訂。這一過程能夠持續最佳化研究報告,直至達到較高標準。
輔助駕駛模式
Agent Laboratory有兩種執行模式:自主模式和輔助駕駛模式。
自主模式下,使用者僅需提供初始研究思路,此後整個過程完全無需人工幹預。每完成一個子任務,系統便會自動按順序推進至下一個子任務。
輔助駕駛模式下,同樣是先提供研究思路。不同的是,每個子任務結束時設有檢查點。在這些檢查點,人工審閱者會對代理在該階段的工作成果(如文獻綜述總結、生成的報告等)進行審閱。
人工審閱者有兩個選擇:一是讓系統繼續推進到下一個子任務;二是要求代理重復當前子任務,並給出改進建議,助力代理在後續嘗試中表現更佳。
o1-preview總分最高
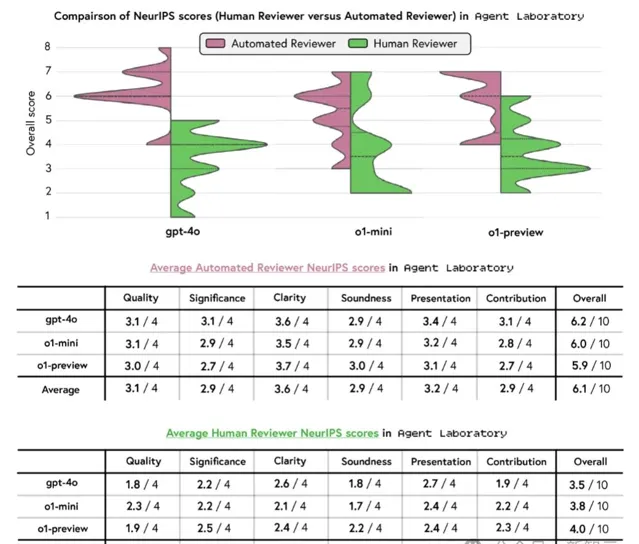
透過比較15篇由10位博士審閱的論文,研究者分析了3個LLM(gpt-4o、o1-mini、o1-preview)在實驗質素、報告質素和實用性方面的表現。人類評審者使用NeurIPS風格的標準來評估論文。
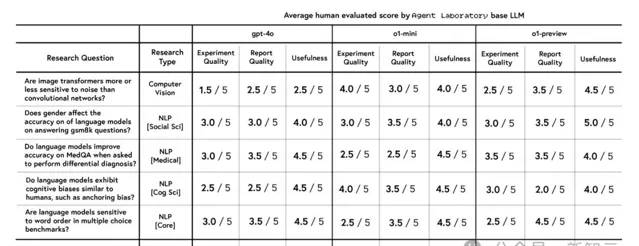
o1-preview的總分最高(4.0/10),其次是o1-mini(3.8)和gpt-4o(3.5)。o1-preview在實用性和報告質素方面表現出色,o1-mini在質素上領先。
而在重要性和貢獻這兩項上,所有模型的表現都較為普通,這反映出模型在原創性和影響力方面存在局限。
所有模型的得分均低於NeurIPS的平均分,表明生成的論文在技術性和方法論的嚴謹性上顯著不足。凸顯了進一步最佳化Agent Laboratory的必要性,讓其生成的內容符合高質素出版物的標準。
在輔助駕駛模式下,研究人員對論文的實用性(3.5/5)、延續性(3.75/5)、滿意度(3.63/5)和可用性(4.0/5)進行了評分。輔助駕駛模式下的論文質素從3.8/10提高到4.38/10。

執行時間和成本分析顯示,gpt-4o的計算效率和成本效益最佳,完成時間為1165.4秒,成本為2.33美元,優於o1-mini(3616.8秒,7.51美元)和o1-preview(6201.3秒,13.10美元)。
報告撰寫是成本最高的階段,尤其是o1-preview(9.58美元)。

Agent Laboratory的出現,無疑是科研領域的一次重大革新,展現了AI在助力科研上的巨大潛力。
盡管它還存在一些需要完善的地方,如生成論文在某些方面與高質素出版物標準尚有差距,但它所帶來的高效、便捷以及新思路,已經讓我們看到了未來科研發展的新方向。











