Thor延期,最有趣的可能是小鵬自己的選擇。
小鵬是Nvidia的Orin X用的最好的那一批,但在端到端年代,Orin X受限於互聯頻寬,端到端技術的能力上線被卡住了。
Thor是緩解當下算力/頻寬瓶頸,實作更強智駕演算法的有效途徑。但Thor 延期了,能大規模上市的時間和小鵬自研芯片的時間,可能相差無幾,甚至算力都可能是接近的。
於是,小鵬面臨——在用的習慣的Thor,和用起來可能沒那麽習慣的自研芯片之間做抉擇,更快更好上自研芯片,似乎成了當下更好的路徑。
1、Orin X的端到端支持不夠好,所以需要Thor。
Orin X被算力和頻寬限制。比如理想說他們用Orin X跑VLM只有3-5Hz(0.2-0.3秒/次)。
而端到端基本只能部署在一顆芯片上(互聯頻寬問題)
所以本來國內這些廠商都在等Thor,用一顆Thor代替兩顆Orin X。
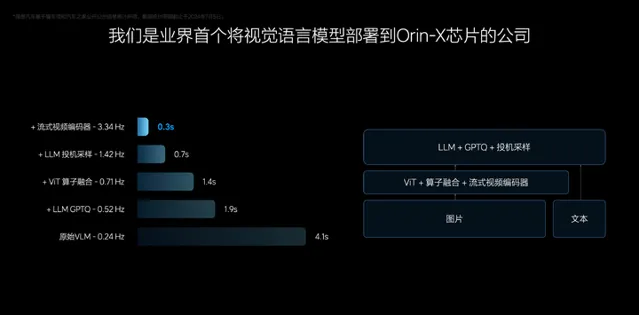
上代BEV+Transformer+OCC的智駕演算法,可以多芯片跑,是用不同芯片處理不同資訊。
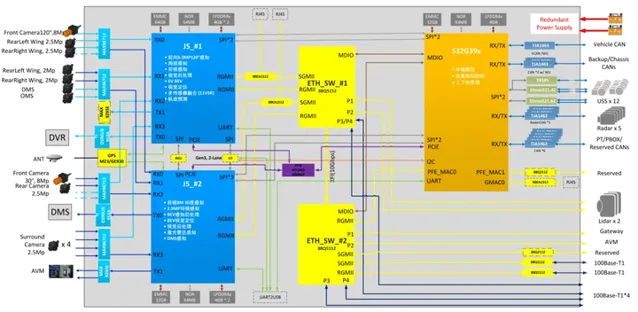
舉個例子,下圖是雙地平線J5的方案,兩顆芯片負責的內容各不相同。
2、Nvidia那邊對Thor的精力不足
NV家近兩年主要精力都在伺服器/大模型領域,汽車業務占比也就不到5%。
但近期的B200延期,以及各家伺服器芯片的ASIC計劃,讓NV重點都在下一代芯片應該怎麽規劃上。
這個並不是NV的芯片設計能力不足,也不是NV水平不行。
要說親戚關系,Thor可能跟任天堂的Switch更近一點。
Thor演進過來的路線不是從顯卡下放,而是移動端處理器升級。路徑大體是Tegra-Tegra 2-Tegra 3-Tegra 4-Xavier-Orin-Thor,Xavier前面的這些處理器資深一點的數碼愛好者應該都熟悉,我還用過Tegra 2的手機——Moto ME860、海信T96。
3、當然,Thor也有自己的問題,還是出在頻寬上。
此前報道中,Thor的頻寬應該是273GB/s,比Orin X沒高太多,可能還是會碰上儲存墻的問題。
當然,這可能也是Thor延遲的原因,由於頻寬的原因(可能還有算子,總所周知,Orin X裏面那個DLA對於Transformer的算子支持不好,Thor的這部份DLA的算力究竟是多少,也沒有公開資料說明),Thor可能還在調整。而這部份調整,又進一步導致了上市時間的延遲。
作為對比,特斯拉HW4用上了GDDR6,記憶體頻寬上升到了448GB/S(單顆芯片正反布置8個 GDDR6 2GB,資深遊戲顯卡佬應該知道我在說什麽),最新一代FSD V13.2也暫時只支持HW4。

4、Thor延期也是小鵬自研芯片的機會。
如果把時間放到2025年,相對好用的智駕芯片就只有Orin系列(400美元左右的X、200-300美元的Y,200+美元級別的N,NV殺價也很猛),以及地平線J6E/M,外加國產化要求,這塊需求應該還是挺大的。
小鵬的芯片——如果按照之前釋出會上的內容,一顆頂三顆的話,大體上應該是400TOPS稠密算力級別(對應Orin X 127TOPS稠密算力)

如果這顆芯片目前流片,最快上車套用可能也是在2026年下半年到2027年
這個時間點差不多和Thor能正式大規模上車差不多,Thor最快明年下半年出來700TOPS級別的Thor S,但模組要大規模上車套用,照樣還得在車企跑完冬測夏測,Thor S要是沒趕上冬測,最快想用就得把車挪去澳洲跑一遍,跑完冬夏兩測,基本也就到了2027年下半年。
如果Thor S這個700TOPS依然是稀疏算力,那實際好用的稠密算力差不多是350TOPS,還不及小鵬自研產品。
所以,Thor延期,最有趣的可能是小鵬自己的選擇。
小鵬是Nvidia的Orin X用的最好的那一批,但在端到端年代,Orin X受限於互聯頻寬,端到端技術的能力上線被卡住了。
Thor是緩解當下算力/頻寬瓶頸,實作更強智駕演算法的有效途徑。但Thor 延期了,能大規模上市的時間和小鵬自研芯片的時間,可能相差無幾,甚至算力都可能是接近的。
於是,小鵬面臨——在用的習慣的Thor,和用起來可能沒那麽習慣的自研芯片之間做抉擇,更快更好上自研芯片,似乎成了當下更好的路徑。










