最近给团队来了一个三卡2080Ti、双CPU、512GB内存的训练机,大概46000左右。配置单如下,详细见如何配置一台5W左右的深度学习工作站?。
======= 03/09/2019 的分割线和更新 =======
挺感慨的。上次写这个问题的答案还是在快2年前(2017年)。现在(2019年)2年过去了,人也从美国搬回了北京,C'est la vie...
好了不偏题。再重申一遍,主要就 还是以下几点 :
- 如果是自己做深度学习工作站的话,适当捡一下洋垃圾能够 非常有效 地降低系统成本。
- 除非在过去型号的GPU上已有投资,否则对于新的配置请 无脑上最新版 。
- GPU上的投资回报比基本 呈线性变化 ,因此可以按照自己的(显存)需要量力而行。
- 最容易被忽视的是电源,一定要注意总体功耗,不可 过载 。
基于上面的回复,有篇好文章(Roison An:洋垃圾工作站 惠普 HP Z420 Z620 装机经验记录,你想知道的都在这里),这里主要有几个有意思的点,平时大家不太会注意到的:
- BIOS请上3.91版。这样可以回避CPU安全补丁带来的性能影响。
- NVMe启动请上对应品牌有Option ROM的SSD。
最后,我做了一个偏重型工作站的配置(时间02/04/2019),以供大家参考:
- 准系统 HP Z820 x1 原生支持V2系列CPU,且1125w大功率电源
- CPU Intel E5-2697v2 12核24线 2.7/3.5G x2
- 内存 32GB DDR3 1600 x16 = 512GB
- 显卡 GeForce RTX 2080 (8GB) 涡轮版 x3
- 系统盘 Samsung P953 960GB x1 加个转接卡
- 数据盘 Seagate ST6000NM0034 6TB x4 (RAID10) = 12TB
这个配置有以下几个特点:
- CPU和RAM都配得比较足,为的是a) 尽量把模型带进内存;b) 做GBDT、随机行走等CPU计算密集的操作,c) 用CPU做模型推理。
- 显卡上的是RTX 2080,为的是平衡性价比。这里显存上有些吃亏。
- 空间、电源都发掘到了极致。这套系统最多支持3块全速PCI-E 3x16(CPU0 x2, CPU1 x1),这下全用上了。另外官方手册上明确说明,支持至多2块共600w显卡、或3块<225w显卡,这里也是极致。
- 总价格较低,大概是3万元出头吧。
我打算给团队先配个2-3台,之后能充分使用了,再给他们上10卡服务器(配置以后写)...
另外我还有个两卡1万出头的配置,回头有空了再放上来。
======= 02/04/2019 的分割线和更新,以下为原回答 =======
谢邀。以下答案只针对工作站的情况。
在具体的论述之前,先说几个结论:
- 如果是自己做深度学习工作站的话,适当捡一下洋垃圾能够 非常有效 地降低系统成本。
- 除非在过去型号的GPU上已有投资,否则对于新的配置请 无脑上Pascal 。
- GPU上的投资回报比基本 呈线性变化 ,因此可以按照自己的需要量力而行。
- 最容易被忽视的是电源,一定要注意总体功耗,不可 过载 。
关于洋垃圾
洋垃圾是个好东西,价格便宜量又足。尤其是在淘汰下来的工作站上常用Xeon级别的单/多路CPU,而它在极其低廉的成本下提供了:a) 多核大缓存,b) 大内存支持,c) 多PCI-E通道,以及 d) 多路NUMA支持。牙膏厂(Intel)体系架构更新对于性能的优化已经很微小了,它主要是制程带来的能耗优化。所以哪怕是早个一两代的CPU,比如2012年发布的Sandy Bridge EP,做个深度学习的主机CPU也是绰绰有余。
现在(2017.04)我强烈推荐HP的Z420和Z620。前者带上单路E5-1650(6核3.2Ghz)、32G内存和600w高质量电源大概$380,后者在这个基础上再加个$20-$40同时把电源更新成800w。这两款洋垃圾均支持双PCI-E x16 Gen3卡,而且你基本上不会碰到任何PCI-E通道之类的坑。
关于GPU的代际更新
黄老板在Pascal这一代上发飙了。我收集整理了Kepler (GTX 7xx),Maxwell (GTX 9xx),Pascal (GTX 10xx) 这三代的性能数据(数据来源主要是wikipedia)如下:https:// docs.google.com/spreads heets/d/111PwO4C4Clp6nUaAKACx46scQKaEntd6QGua8_pyIw/edit#gid=968981801 。各位伸手党们可自取。
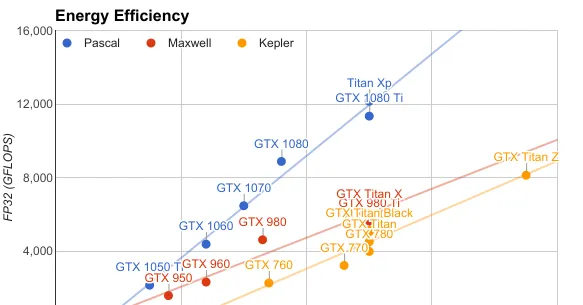
从能耗比上看,Kepler到Maxwell基本上是个渐进式的变化,越往高端走改进越不明显。这也从一个侧面说明了为啥在Maxwell的时代有人还用着老Kepler Titan「再战几年」。新的Pascal架构甩了上两代几条街,在能耗比上完全碾压。有人会问——我在实验室电费不要钱,是不是就可以用旧架构了?完全不是。第一,除去Titan Z这样的2合1怪物以外,前两代的单卡性能被从GTX 1070到Titan Xp全线碾压,而每个工作站上能插的 PCI-E通路数量是有限的 。第二, 电源的功率输出是有限的 ;在同等算力下老架构需要更多电力,因此如果是洋垃圾或者自组平台的极端情况(4槽全满)下,电源根本没法提供这样的功率输出。

从价格上看,常常有一些小伙伴猜测,在同等算力的情况下,上一代产品或许会更便宜。很不幸,上图反驳了这种观点。本图中的价格(横轴,取了log以方便显示)来自于eBay上二手卖家的出价,或者 http:// Jet.com (一个奇葩购物网站) 上的新品折扣价格。可以明显地看出, 在同等算力的情况下新一代Pascal架构产品的二手价格要低于老架构产品的二手价格 。
另外,在上图中没有显示的是,新架构的产品往往具有 更大的显存容量 ,例如GTX 1060有6G显存,GTX 980有4G显存,而GTX 780 Ti/GTX Titan分别提供了3G和6G的显存。最后,新架构的产品支持更新的CUDA功能集以及GPU加速库版本,从而也会获得另一些额外的性能提升。因此在不同GPU架构间,无脑选Pascal。
关于量力而行
前两图中的直线(第二张图因为横轴是log scale所以有变形)是对于各点的线性拟合。可以看出无论是功耗还是定价,它们基本上都和计算能力保持了线性相关。这也就意味着老黄的刀砍得非常的准,除了Titan这类高端货外完全是 一分钱一分货 ,不大存在捡便宜的可能。另外,在GPU的世界里投资折旧率很高(看看这三代GPU就知道了),因此有多大的需要就弄多大的卡吧。如果是严肃的科研工作者建议还是上大一些的卡,毕竟在现在多机分布式训练扩展性做得还不大好的时候,什么也比不过在一个卡上算起来快。
关于电源
电源是 最容易被忽视 的一个问题!很多小伙伴常常是满心欢喜地把大把显卡、CPU装好,然后发现——电源过载了。而最蛋疼的是一般工作站主机的电源是最高1600w到头,也就是将将撑住4块250w不超频的显卡。关于电源功率的计算我推荐 OuterVision Power Supply Calculator。它的Expert模式极其强大。
说回到Z420/Z620上的电源,Z420上搭配的是台湾台达电子生产的DPS-600UB A电源,这里( DPS-600UB A - Plug Load Solutions )有它的介绍。不得不说工作站上的电源就是扎实,不虚标且稳定。
总结
最后,总结一下整个配置。
希望对你有帮助。










