如果你对数据分析感兴趣,希望学习更多的方法论,希望听听经验分享,
欢迎移步宝藏公众号 「小火龙说数据」 ,无广告、无软文、纯干货,更多精彩原创文章与你分享!
00 序言
在日常产品迭代过程中,我们常常需要去验证某个功能、策略的改动是否符合预期,是否可以完全替代现有的方案。小流量实验往往是最常用、最直接验证因果的方式。然而有些时候,由于忘记开展实验、实验成本较高等因素,没有对策略进行AB实验,但又希望评估策略效果,这个时候,则可以通过其他因果推断方式进行佐证。
因果推断的基石在于尽量保障策略差异是唯一的变量,核心步骤涵盖两点:
其一:构造两组相似的用户群体,群体差异越小越好。
其二:度量策略对群体的影响程度,聚焦核心指标的变化。
以下几类方式是因果推断中常用到的,如下图所示。

下面,将对每个模块的方式进行展开说明。
01 Matching
因果推断的前提条件,是构造两个近似完全一样的样本群体,一般情况下,样本群体=用户群体。保证用户群体一致最直接的方式,则是一一匹配,即:保证微观单体用户一致,扩展到整体也是一致的。这种通过treated用户去匹配no treated用户的方式,称之为Matching,常见的Matching方式有以下几种,如下图所示。
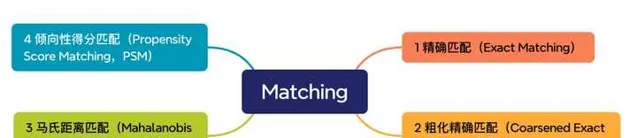
精确匹配(Exact Matching)
最理想的方式是对两组单体用户一一精准匹配,保障单体用户特征完全一样,例如:实验组单体用户「18岁+一线城市+男性+本科+互联网行业」与对照组单体用户「18岁+一线城市+男性+本科+互联网行业」相匹配。
理论上,此种方式匹配出来的用户最为精准,不过其存在一定的局限性。
一方面,需要两组内有足够多的群体用于匹配;
另一方面:适配维度不宜过多,过多的维度会导致很难匹配到完全一致的样本。
粗化精确匹配(Coarsened Exact Matching,CEM)
同学们思考一下,如果是连续特征,要如何进行精确匹配呢?例如:收入、支出、打开软件次数等。涵盖连续特征的用户,找到相同的概率会大打折扣。
这里,可以在精确匹配的基础上做一点改动,将连续特征分段离散化,然后再进行精确匹配。例如:打开软件次数的范围是0→+∞,可将连续变量分段成[0,5),[5,10),[10,+∞)等。
马氏距离匹配(Mahalanobis Distance Matching,MDM)
虽然EM、CEM可以相对精准一一匹配用户,然而随着维度的增加,精准匹配用户的可用性会逐步减弱。
面对这种情况,可以退而求其次,增加兼容机制,通过计算距离的方式,近似匹配相似的用户,如能精准匹配相同用户,则距离为0;如不能精准匹配,则逐一选择距离最近的用户。
此种方式最大的局限性在于效率,假设实验组M个用户,对照组N个用户,则其计算量为M×N,当样本量与特征均较高时,该种方式的效率会非常低(同分类模型KNN原理一致)。
倾向性得分匹配(Propensity Score Matching,PSM)
PSM是在MDM方式上的一种优化,其本质是将高维特征映射到一维倾向分上,然后再在不同label中寻找相近的倾向分用户。这里的倾向分,代表了多维特征整体数值的表现,该值越接近,则两样本的整体特征越相似。
同样,PSM也会有一定的局限性和弊端。
其一:对于样本量有要求,如果样本量过少,会导致匹配的样本距离过远,达不到真实的相似要求。
其二:对于模型的训练要求较高,会出现两用户各特征并不相似,但倾向性分很相近的情况,即:信息折损。
02 Weighting
Weighting的核心思想,是将实验组与对照组用户群体内各类人群比例,调整到同大盘一样的标准,从宏观上保证其样本量的同质。
本质上,Matching是对样本进行重采样和丢弃,同Weighting的核心思想一致,其不一样的地方主要体现在以下两方面上。
其一: Matching是以treated群体为标杆去匹配no treated群体,验证的是treatment给实验组用户带来的影响;而Weighting是以大盘用户为标杆去匹配群体,验证的是treatment给大盘用户带来的影响。
其二: 由于Matching在重采样中存在随机性,因此鲁棒性没有Weighting强。
03 Regressing
Regressing同Matching、Weighting思路完全不同,不再为treated群体样本一一匹配,而是通过预测来估计treated群体样本落在对照组的指标表现情况。其将实验组用户指标Y,拆解为「协变量+treatment」,以此来计算实验组样本在对照组的量级,再通过计算差值得到策略对指标的影响程度。
04 Other Method
其他方式还有很多,如下图所示。

其中应用较多的是双重拆分法、因果森林。
双重拆分法(Difference in Difference,DID)

因果森林
05 总结一下
可能有些同学会问,既然有这么多种因果推断的方式,那为什么还要做AB实验呢?
其实无论是哪种方式,均存在一定的假设和局限性。归总来看,小流量实验仍然是最科学、最直接的方式,因此,在有能力做AB实验的前提下,优先通过此种方式进行验证。
数据分析资料(获取可戳链接):
面试辅导(获取可戳链接):
以上就是本期的内容分享
如果你也对数据分析感兴趣,那就来关注我吧,更多「原创」文章,与你分享!!
微信公众号:小火龙说数据












