【论文阅读---深度强化学习打王者荣耀】Parametrized Deep Q-Networks Learning: Reinforcement Learning with Discrete-Continuous Hybrid Action Space
标题 Parametrized Deep Q-Networks Learning: Reinforcement Learning with Discrete-Continuous Hybrid Action Space
论文地址
https:// arxiv.org/abs/1810.0639 4v1
离散连续空间相关实现代码
https:// github.com/cycraig/MP-D QN
关键点 离散连续空间

这篇博客是我在21年3月放在CSDN上的,是一个非常好的通过深度强化学习训练游戏中的Agent进行对抗的例子。
腾讯的 AI Lab 在这篇文章中提出了P-DQN算法, 文章关注 Real Time Strategic (RTS) games 中的应用 (discrete-continuous hybrid action space) 中的问题,并且在旗下的王者荣耀游戏中进行实验测试。
摘要
目前大多数深度强化学习算法要求 action space 要么是离散的 (e.g., Go and Atari) ,要么是连续的 (e.g. MuJoCo and Torcs) , 为解决 Real Time Strategic (RTS) games 中的应用问题,文章提出了一种可以解决离散连续混合空间中问题的P-DQN算法。
在计算完整体的参数后,算法首先从一个 discrete set [K] 中选取一个上层的离散 action , 再选择一个连续的下层 parameter x_k\in \mathcal{X_k} , 这个 parameter 和先前选择的离散动作相关。这里 \mathcal{X_k} 是一个包含所有 k \in [K] 对应的离散集合。 定义动作空间如下:
\mathcal{A} = \{(k, x _k) |x_k\in \mathcal{X_k} \ \rm{for \ all\ } \mathcal{k} \in [K] \} \ \ \ \ (1.1)
该文章的方法可以看成将DQN拓展到混合空间,首先定义了一个 deterministic function ,用于将 state 和每一个 discrete action 映射到 continuous parameter ;文章还定义了一个 action-value function ,用于将 state 和有限的混合动作映射到真实的 values
值得注意的是,下层的 continuous parameter 是可选的,不同的离散 action 之间可以拥有相同的 continuous parameter
Parametrized Deep Q-Networks (P-DQN)

考虑一个拥有(1.1)中 action space \mathcal{A} 的MDP,对于 a \in \mathcal{A} ,有 Q(s, a) = Q(s, k, x_k) 。定义在 t 时刻选择的离散动作为 k_t ,关联的 continuous parameter 为 x_{k_t} ,现在 Bellman equation 变成:
Q(s_t, k, x_k) = \mathop{\mathbb{E}}\limits_{r_t, s_{t+1}}[ r_t + \gamma \ \mathop{\rm{max}}\limits_{k \in [K]} \mathop{\rm{sup}}\limits_{x_k \in \mathcal{X_k}} \it{Q} (s_{t+1}, k, x_k)|s_t = s, a_t = (k_t, x_{k_t})] \ \rm(3.1)
对于等式右边,对每\mathcal{k} \in [K] 先计算 {x_k^ = \rm{argsup}{x_k \in \mathcal{X_k}} \ \it{Q}(s{t+1}, k, x_k)} ,接着选择最大的 Q(s_{t+1, k , x_k^*})
值得注意的是,当 function Q 固定,对于任何 s \in S 以及 k \in [K] ,可以将 \ \rm{argsup_{\it{x_k \in \mathcal{X}_k}} \ \it{Q}(s, k, x_k)} 视作函数 x_k^Q : S \to \mathcal{X}_k ,则(3.1)中的 Bellman equation 可以改成
Q(s_t, k, x_k) = \mathop{\mathbb{E}}\limits_{r_t, s_{t+1}}[r_t + \gamma \ \mathop{\rm{max}}\limits_{k \in [K]} \it{Q}(s_{t+1}, k, x_k^Q(s_{t+1}))|s_t = s]
和DQN的思想一样,用深度神经网络 Q(s, k, x_k; w) 近似 Q(s, k, x_k) 用一个 deterministic policy network x_k(.;\theta):S \to \mathcal{X}_k 来近似 x_k^Q 。当 w 固定的时候,我们希望找到一组 \theta 满足:
Q(s,k, x_k(s;\theta);w) \approx \mathop{\rm{sup}}\limits_{x_k \in \mathcal{X}_k} Q(s, k ,x_k; w) \rm{ \ for \ each \ }\mathcal{k} \in [K] \ \ (3.2)
设 w_t,\theta_t 为 t 时刻的 value network 和 deterministic policy network 的参数,对于固定的 n\ge1 ,定义 n-step 目标 y_t 为:
y_t = \sum_{i=0}^{n-1} \gamma^ir_{t+i}+\gamma^n\mathop{\rm{max}}\limits_{k \in [K]}Q(s_{t+n}, k, x_k(s_{t+n}, \theta_t); w_t) \ \ \ \ (3.3)
定义两个 loss function :
\mathcal{l_t^Q(w) = \frac{1}{2}[Q(s_t, k_t, x_{k_t};w)-y_t]^2} \ \ \rm{and} \ \ \mathcal{l_t^\Theta(\theta) = -\sum_{k=1}^{\rm{K}}\it{Q}(s_t, k, x_k(s_t; \theta);w_t)} \ \ \ \ (3.4)
文章用 stochastic gradient methods 更新 weights 。当 w 固定时,为最小化(3.4)中的 \mathcal{l_t^\Theta(\theta)} ,理想情况下可以通过一个符合 two-timescale update rule 的方式来完成。具体来说,更新 w 的时候用到的 stepsize \alpha_t 和更新 \theta 的 stepsize \beta_t 比较微不足道( asymptotically negligible )。同时需要 {\alpha_t, \beta_t} 满足Robbins-Monro condition
具体算法如下:

需要注意的是,在探索过程中算法需要一个定义在 \mathcal{A} 上的分布 \xi ,实践中可以为 \mathcal{A} 上的均匀分布。
The Asynchronous n-step P-DQN Algorithm
为了加速训练过程,仿照 n-step DQN 文章提出了 asynchronous n-step P-DQN 。考虑一个每一个 process 计算自己的 local gradient 并和全局 「parameter server」 交互的 centralized distributed training framework :每一个 process 运行一个独立的环境产生转移轨迹并用自己的转移来计算 w 和 \theta 的梯度,这些梯度后续被一起用于计算全局的 parameters 。
具体算法如下:

实验
文章一共采用了三个实验场景,分别是:1) a simulation example, 2) scoring a goal in simulated RoboCup soccer, 3) the solo mode in game KOG。
前面两个实验的详细设定和结果可以可以通过阅读论文了解,下面介绍第三个实验:
Solo mode of King of Glory
在实验中, game 的 state 用以179维的特征向量表示,数据由 game engin 直接生成。这些特征包含两个部分( basic attributes of the units and the relative positions of other units with respect to the hero controlled by the player as well as the attacking relations between units )
实验将英雄的 action 简化成 K = 6 的离散动作: Move, Attack,UseSkill1,UseSkill2,UseSkill3,Retreat 。 一些 action 可能拥有额外 continuous parameters 来使行为更加精准。例如 k = Move ,方向由 x_k = \alpha 定义, \alpha \in [0,2\pi] 。值得注意的是,每一个英雄的技能是独一无二的,完整的动作列以及关联的 parameters 如下:

由于 Magic Point 和 Cool Down 的相关限制,实际操作中 max_{k \in [K]} 被替换成 max_{k \in [K] and \ k \ is \ usable} ,多步目标由前文的(3.3)计算
The reward for KoG
相关描述如下:

整体 reward 公式如下:
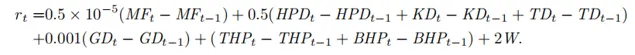
公式中系数只是大概的设定了一下,文章中的实验在一定范围内对这些数据并不是特别敏感。
文章采取了 Algorithm 2 ( with 48 parallel workers ), network x(\theta) \mu(\theta) are both in the size of 256-128-64 nodes in each hidden layer , Q(w) is in size of 256-128-64-64 为了缩短 episode length ,采用了跳帧( frame skipping )技术并设置 frame skipping parameter 为2。
更进一步,对 Algorithm 2 中的参数,有: t_{max} = 20 ;训练用到 \epsilon-greedy(\epsilon = 0.255) 来采样,具体为前五个动作概率为0.005而 Retreat 概率为0.0005;如果采样得到的动作是不可行的,就在可行的动作中用贪心方法选择。 learning rate 设置为0.001
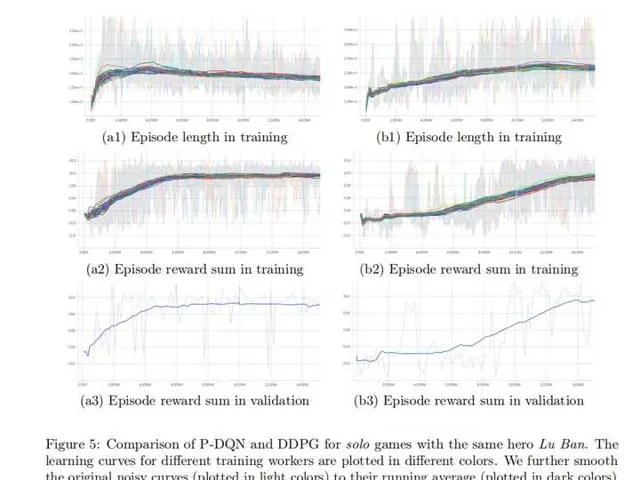
文章中算法与DDPG对比结果如下:
总结
两年前写这篇博客的时候貌似Agent已经可以达到黄金段位了,过了两年应该有新的方法得到段位更高的Agent。










