贝叶斯滤波相关可参考:zzg:机器人算法基础:贝叶斯滤波 , 也可以先阅读此文,遇到贝叶斯相关再去参考
数据融合
平均值融合
使用同一台电子称 , 对一个物体进行两次测量 ,得到两次测量结果A , B ,如下图所示
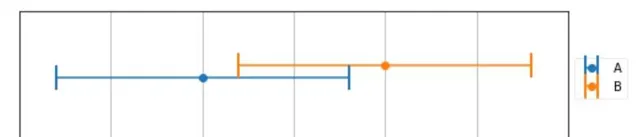
图中用线段表示测量结果而不是点 表明称不是绝对精准的 , 它有一个误差范围 +- 8 kg ,假设在这个范围内 , 可能性都是相同(符合均匀分布,实际上正态分布更合理,但是这里重点不是什么类型的分布),那么我们如何选择最终的测量结果呢?
按照常识我们会对两次结果求平均值 :
M = \frac {A+B} 2\\
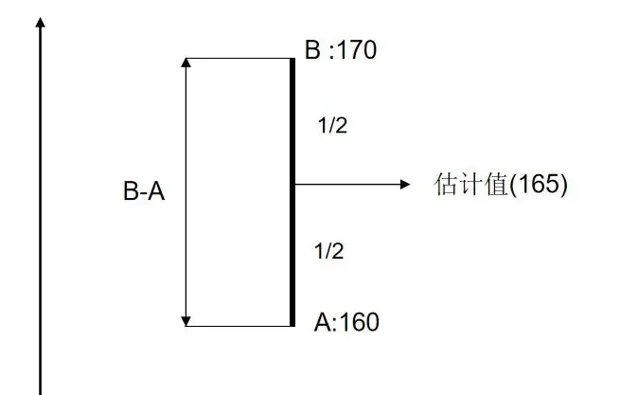
在图中,平均值表示得区域 为重叠部分得中点 165
将上面得计算公式变形,可以更加直观的理解:
M=\frac {A+B} {2} = \frac {A+A+B-A}{2} = A + \frac{B-A}{2}\\
M的结果为 A 加上 AB之间的差值的 一半 , 为何这里刚好选 一半? 因为两次的测量结果来自同一台称 , 我们没有理由更加倾向于 A, 或者B 。
加权平均融合
使用两台精度不同的称 来称同一物体,得到 了测量结果如下图所示
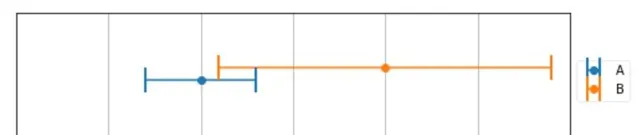
可以很明显的看到 , A 测量精度明显高于 B 的精度,这个时候我们该如何选则测量结果呢? 还是求平均值吗,得到165 的结果?
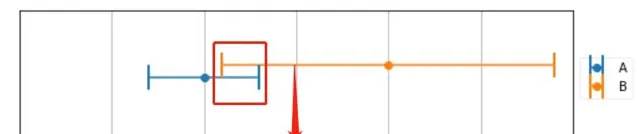
这不符合我们的直观。首先, 真实的结果应该同时满足在两个称的测量结果范围内 , 如图重合部分。至于在重合部分的具体那个地方,我们做一个数值假设:
A 测量结果 为 160 +- 3
B 测量结果 为 170 +- 9
在使用同一个传感器测量时,我们对两次测量结果的倾向性相同 , 各占 1/2 。在这里A 的测量结果精度是 B 测量结果精度的 3倍 ,我们会产生这样的直观 , 根据精度比例 , 我们 \frac 3 4 倾向 A 测量结果 , \frac 1 4 倾向 B结果。
M = \frac 3 4 A + \frac 1 4 B = A+ \frac{1}{4} (B-A) = 161\\
可以看到计算结果在上图中重合部分 , 且满足 了 A 精度是 B 精度的 3 倍这个条件 , 这就是加权平均,A的测量值权重为 \frac 3 4 , B测量值的权重为 \frac 1 4 , 权重 总和 为 1.
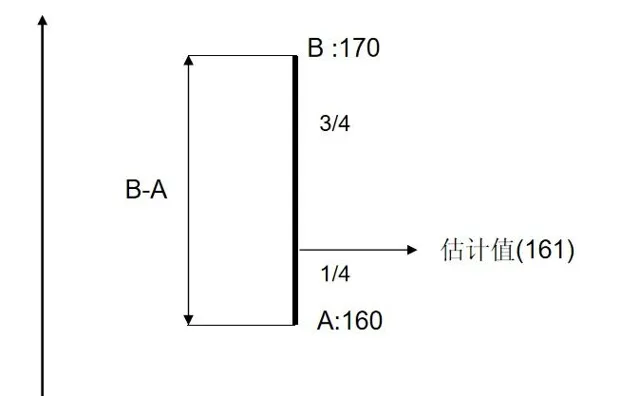
直观上,加权平均基本能说服我们 ,按这种方法得到的估计是最优估计,那有没有理论证明呢?
最优状态估计
在开始证明前 ,我们需要一些期望代数的背景知识 ,如果了解可直接跳过
期望代数
平均值与期望
对于随机变量 x , E(x) = \mu_x , 也就是随机变量的期望 , 等于其平均值。
若随机变量 x 符合概率 分布 P(x) , 则
若 P(x) 离散:
E(x) = \sum xp(x)\\
若 P(x) 连续:
E(x) = \int xp(x)dx\\
方差和标准差
方差用来度量随机变量与其期望值(即随机变量的期望值)之间的离散程度。
标准差是方差的平方根。标准差: \sigma ,方差: \sigma^2
例如,我们想比较两个高中篮球队的身高。下表提供了两支球队的球员身高及其平均值。

如我们所见,两队的平均身高是一样的。现在让我们检查一下高度变化方差。由于方差用来度量随机变量与其期望值(即随机变量的期望值)之间的离散程度,我们想知道数据集偏离其平均值的情况。我们可以通过从每个变量中减去平均值来计算每个变量与平均值之间的距离。我们将用x表示高度,用希腊字母μ表示高度的平均值。每个变量与平均值的距离为:
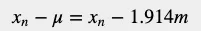
下表给出了每个变量与平均值之间的距离。

下表给出了每个变量与平均值的平方距离。有些值是负数。为了消除负值影响,让我们将高度与平均值的距离平方:
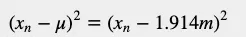

为了计算数据集的离散程度,我们需要从中找出所有平方距离的平均值:
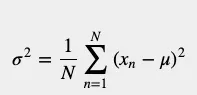
A队的方差是:

B队的方差是:

我们可以看出,虽然两队的平均值相同,但A队的身高分布值高于B队的身高分布值,这意味着A队在控球员、中锋和后卫等不同位置有不同的球员,而B队球员则技能相差无几。方差的单位是平方的;查看标准差更方便。正如我已经提到的,标准差是方差的平方根。

A队运动员身高的标准差为0.12米。
B队运动员身高的标准差为0.036米。
进一步的,现在,假设我们要计算所有高中篮球运动员的平均值和方差。这是一项非常艰巨的任务,我们需要收集所有高中运动员的数据。
但是,我们可以通过选择一个大的数据集并对这个数据集进行计算来估计参与者的平均值和方差。(样本估计全局)
随机选取的100名选手的数据集足以进行准确的估计。
然而,当我们 估计方差 时,方差计算公式略有不同。我们不用N因子归一化,而是用因子归一化:
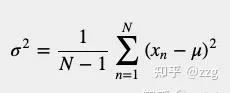
你可以在以下资源中看到这个方程的数学证明:[http://www. visiondummy.com/2014/03 /divide-variance-n-1/ ](
期望代数公式
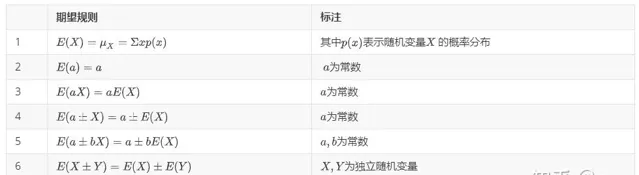

后文中需要用到的公式有:
最优状态估计推导
两个独立的变量 x_1 , x_2 ( x_1 , x_2 为两个精度不同的称称量同一物体得到得测量值), 方差分别为 \sigma_1^2 , \sigma_2^2 ,我们通过加权平均来做估计有:
\hat x = w_1x_1 + w_2x_2\\ w_1+w_2 = 1
其中为 x_1 的权重 w_1 , x_2 为 w_2 的权重 , 根据方差得计算公式可得:
\sigma_1^2 = E((x_1-E(x_1))^2)\\ \sigma_2^2 = E((x_2-E(x_2))^2)
估计值 \hat x 的期望为:
E(\hat x) = E(w_1x_1+w_2x_2) \\ = E(w_1x_1)+E(w_2x_2)\\ =w_1E(x_1)+w_2E(x_2)
估计值 \hat x 的方差为:
\begin{align} \sigma^2 &= E((\hat x - E(\hat x))^2)\\ &= E((w_1x_1+w_2x_2-w_1E(x_1)-w_2E(x_2))^2)\\ &= E(((w_1(x_1-E(x_1)) + w_2(x_2-E(x_2)))^2)\\ &= E(w_1^2(x_1-E(x_1))^2 + w_2^2(x_2-E(x_2))^2 + 2w_1w_2(x_1-E(x_1)(x_2-E(x_2)))\\ & = w_1^2E((x_1-E(x_1))^2) +w_2^2E((x_2-E(x_2))^2) + 2w_1w_2COV(x_1,x_2) \\ & = w_1^2\sigma_1^2 + w_2^2\sigma_2^2 + 2w_1w_2COV(x1,x2) \end{align}
由于 x_1 , x_2 是独立的 ,所以 x_1 , x_2 的协方差 COV(x_1 , x_2) = 0 , 则:
\sigma^2 = w_1^2\sigma_1^2 + w_2^2\sigma_2^2\\
由 w_1 + w_2 = 1 可设 w_2 = w , w_1= 1-w , 代入上式可得:
\sigma^2 = (1-w)^2\sigma_1^2 + w^2\sigma_2^2\\
最优估计,即是让估计的方差 \sigma^2 最小 , 这样估计得结果就更精确 , 上式中,唯一的变量是 w , 因此需要求使得 \sigma^2 最小的 w 值,观察函数 , 发现是一元二次方程,开口向上 , 存在最小值 , 通过求导 ,令导数等于0 得到最小值。
\begin{align} \frac {d_{\sigma^2}}{d_w} &= 2(w-1)\sigma_1^2 + 2w\sigma_2^2 = 0\\ w &= \frac {\sigma_1^2}{\sigma_1^2 + \sigma_2^2} \end{align}\\
将 w 的 值 带入 \sigma^2 的 计算公式中, 得到:
\begin{align} \sigma^2 &= (1-w)^2\sigma_1^2 + w^2\sigma_2^2 \\ &= \frac{\sigma_1^2\sigma_2^2}{\sigma_1^2+\sigma_2^2} = w\sigma_2^2 = (1-w)\sigma_1^2 \end{align}\\
因此,最优状态估计:
\begin{align} \hat x &= (1-w)x_1 + wx_2 = \frac {\sigma_2^2x_1 + \sigma_1^2x_2}{\sigma_1^2 + \sigma_2^2} \\ \sigma^2 &= \frac{\sigma_1^2\sigma_2^2}{\sigma_1^2+\sigma_2^2} \end{align}\\
以上推导完毕。
我们验证一下先前两台不同精度的称 是否 符合 最优状态估计。已知 :
A的测量结果 x_1=160 , 标准差 \sigma_1 = 3
B的测量结果 x_2 = 170 , 标准差 \sigma_2 = 9
按照最优估计公式计算 , 最优估计:
\begin{align} \hat x &= \frac {9^2*160 + 3^2*170}{3^2 + 9^2} = 161 \\ \sigma^2 &= \frac{3^2*9^2}{3^2+9^2} = 8.1 \end{align}\\
结果与我们的直观 估计相同。
在贝叶斯章节,我们知道,两个高斯分布相乘, 其结果为高斯函数。,观察高斯函数相乘的结果可以发现,与最优估计的结果相同,因此可以得出结论: 符合高斯分布的贝叶斯滤波(先验和似然均是高斯分布)得到的后验是最优状态估计,而后面的卡尔曼滤波就是基于高斯分布和贝叶斯的,所以卡尔曼滤波属于最优状态估计的一类滤波器 。
X\sim N(\mu_x , \sigma_X^2)\\ Y\sim N(\mu_y , \sigma_Y^2)\\ \mu = \frac {\sigma_x^2\mu_y+\sigma_y^2\mu_x} {\sigma_x^2+ \sigma_y^2}\\ \sigma^2 = \frac {\sigma_x^2\sigma_y^2} {\sigma_x^2+\sigma_y^2}
g—h滤波器
在前面的章节中 , 我们主要介绍了如何将两个传感器的数据进行融合 , 并进行最优估计的方法。那假设我们只有一个传感器呢 ,有没有办法做类似的估计呢 , 在贝叶斯章节 , 我们经常提到先验概率 , 这个概率在测量之前就有了 , 我们根据先验概率和测量之后得到的似然概率得到后验 。 那么有没有一种办法,在我们还未进行测量前 , 就得到 一个大概的预测, 然后用这个预测和测量值按照上面的步骤,做最优估计呢?
状态外推方程
我们可以通过物理规律 , 对观测物体进行预测,比如运动的物体 , 我们需要对它的位移进行估计 , 在进行测量前,我们可以运用牛顿运动方程推导下一一时刻物体的位置:
\begin{align} x_{predict} &= \hat x + \hat v\Delta t + \frac{1}{2}\hat a\Delta t^2\\ v_{predict} &= \hat v + \hat a\Delta t\\ a_{predict} &= \hat a + f(\Delta t) \end{align}\\
其中, \hat x 表示当前时刻对位移的估计 , x_{predict} 表示下一时刻的位移,是一个预测值(还未发生) , \Delta t 表示时间步长(离散的) , f(\Delta t) 表示加速度随时间变化,这样就可以表示任意状态的运动。类似上面的式子被称为,状态外推方程。
状态更新方程
得到了预测值后我们进行测量 , 然后将 预测值 和 测量值 进行加权平均 ,也就是:
\begin{align} \hat x &= (1-w) x_{predict} + wx_{z}\\ &= x_{predict} + w(x_z-x_{predict}) \end{align}\\
我们在最优状态规估计中知道了如何选择 w ,得到最优状态估计 , 但是有的系统可能我们没法得知方差,也就无法 计算 w 值,有个简单的办法,将w值 作为一个定值 ,通过调整 w 的值,让估计值整体变得更合理, 这种方法称为数值法,通过大量的数据,调整w 得到最优估计(类似的算法还有PID,通过数据整定PID参数)。 将 w 改成 g ( 有的地方也称为 \alpha ) ,就得到了 g-h 滤波器 的状态更新 方程:
\begin{align} \hat x &= x_{predict} + g(x_z-x_{predict})\\ \hat v &= v_{predict} + h(\frac{x_z-x_{predict}}{\Delta t})\\ \hat a &= a_{predict} + k(\frac{x_z-x_{predict}}{0.5\Delta t^2}) \end{align}\\
其中: (x_z-x_{predict}) 称为残差 , 解释为一个 时间步长 , 测量值与预测值的差值 , 通过下图理解 , 即为蓝色点减去红色点的值。对速度的预测,只需将位移残差除以时间步长(位移的一阶导数得到速度)即可。加速度是位移的二阶导,因此,可以得到上面3个状态更新方程。

g-h滤波器的工作步骤
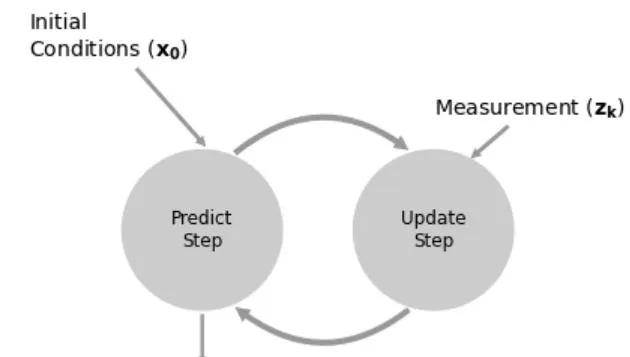
上图表示了g-h滤波器的工作流程。
这种预测和更新的迭代模式有效的 减小了数值的存储问题 , 我们只需要关注当前值,和预测值 ,而不需要考虑过去的历史值 , 如果滤波器表现良好,最终的估计值将慢慢收敛到真实值。下面我们通过几个具体的示例来说明 g-h 滤波器。
示例一:追踪一维匀速飞行器
现在,来看一个随时间改变状态的动态系统吧。在这个例子中,我们用 g-h 滤波器 在一维空间中追踪匀速飞行的飞行器。
假设在一个一维空间,有一架飞行器正在向远离雷达(或朝向雷达)的方向飞行。在一维空间中,雷达的角度不变,飞行器的高度不变,如下图所示。
x_n 代表飞行器在 n 时的航程。飞行器速度定义为航程相对于时间的变化率,即为距离的导数:
\dot x = v = \frac {d_x}{d_t}\\
雷达以恒定频率向目标方向发射追踪波束,周期为 \Delta t 假设飞行器速度恒定,系统的动态模型可以用两个运动方程来描述:
\begin{align} x_{n+1 ,n} &= \hat x_{n,n} + \hat{\dot x}_{n,n}\Delta t\\ \dot x_{n+1,n} &= \hat{\dot x}_{n,n} \end{align}\\
由于需要进行数值迭代,这里将下标改成和 n 相关的,n表示迭代的次数 , 用 \hat{} 表示是估计值,也就是我们关注的经过预测值和测量值融合的结果 ,上式中各项的含义:
上述方程即上面提到的 用于预测的状态外推方程,我们的状态更新方程如下:
\hat x_{n,n} = x_{n,n-1} + g(z_n-x_{n,n-1})\\ \hat {\dot x}_{n,n} = \dot x_{n,n-1} + h(\frac{z_n-x_{n,n-1}}{\Delta t})\\
上式各项的含义:
上面对 n 的设置很合理 n+1 表示将来的,也就是预测 , n 表示当前的 ,也就是当前估计 , n-1 表示之前的,结合 x_{n,n-1} , 则表示n-1 时对 n 的预测。
思考: 为什么追踪匀速的飞行器还需要在状态更新方程里面增加对速度的估计?它不是匀速的吗 ?也就是下面的式子。
\hat {\dot x}_{n,n} = \dot x_{n,n-1} + h(\frac{z_n-x_{n,n-1}}{\Delta t})\\
确实, 对于测量系统 , 已经知道了飞行器是匀速的 ,所以在状态外推方程中,我们进行预测一直是将飞行当成匀速的:
\begin{align} x_{n+1 ,n} &= \hat x_{n,n} + \hat{\dot x}_{n,n}\Delta t\\ \dot x_{n+1,n} &= \hat{\dot x}_{n,n} \end{align}\\
但是这个匀速的速度是多少呢?雷达是不知道的 , 要知道的话就不用进行测量了,我们的预测是100%准确的。雷达只能测距离,通过一个时间步长的位移差来计算当前速度:
\frac{z_n-x_{n,n-1}}{\Delta t}\\
但是,雷达的测量是误差的,这就导致对速度的估计产生了误差,所以每个时间步长对速度的估计都会不同,但在同一个时间步长里还是认为它是匀速的。
数值案例
g-h滤波器参数
设置g-h滤波器的 参数 :
g = 0.2 , h =0.1\\
至于为什么这么多,可以考虑 g 表示是 位移测量值的权重,这说明我们更加相信预测值 , h表示速度测量值的权重,同样更相信预测值,因为我们已经知道系统是匀速的。雷达每5s ,测量一次 , 也就是时间步长:
\Delta t = 5s\\
第0次迭代:
\begin{align} \hat x_{0,0} &= 30000m \\ \hat{\dot x}_{0,0} &= 40m/s \end{align}\\
将数值代入状态外推方程,计算下一时刻位移和速度:
\begin{align} x_{1 ,0} &= \hat x_{0,0} + \hat{\dot x}_{0,0}\Delta t = 30000 + 40*5 = 30200m\\ \dot x_{1,0} &= \hat{\dot x}_{0,0} = 40m/s \end{align}\\
第1次迭代:
y_1 = 30110m\\
进行估计:
\begin{align} \hat x_{1,1} &= x_{1,0} + g(y_1-x_{1,0}) = 30200+0.2(30110-30200) = 30182m \\ \hat {\dot x}_{1,1} &= \dot x_{1,0} + h(\frac{y_1-x_{1,0}}{\Delta t}) = 40+0.1(\frac{30110-30200}{5}) = 38.2m/s\\ \end{align}\\
\begin{align} x_{2 ,1} &= \hat x_{1,1} + \hat{\dot x}_{1,1}\Delta t = 30182 + 38.2*5 = 30373m\\ \dot x_{2,1} &= \hat{\dot x}_{1,1} = 38.2m/s \end{align}\\
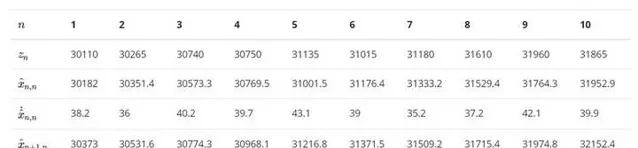
经过10次迭代后 , 得到下表 , 将下表绘制成折线图
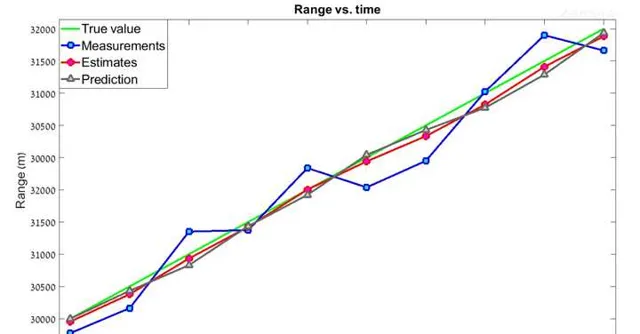
可以看到,估计值比测量值更加平滑 , 而且更加靠近真实值。如果使用更高的 g-h 值呢? g=0.8 , h = 0.5 , 这表明我们更加相信测量值
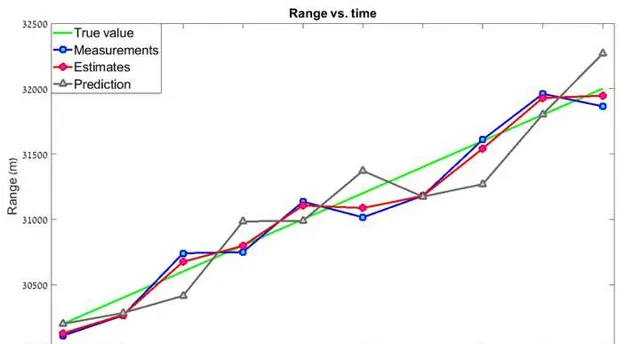
这个滤波器的「平滑度」要低得多,「当前估计值」与测量值非常接近,预测误差较大。那么我们应该一直选择低的 gh 吗?答案是否定的。 gh 的值取决于测量精度。如果我们使用非常精准的设备,比如激光雷达,我们会倾向高 gh ,测量值权重更高,在这种情况下,滤波器会对目标的速度变化作出快速响应。反之,如果测量精度较低,我们会选择较低 gh , 在这种情况下,滤波器将降低测量中的不确定性(误差),然而,滤波器对目标速度变化的反应会慢得多。
示例二:追踪一维匀加速飞行器
如果直接直接用追踪匀速飞行的 g-h滤波器来最终匀加速会发生什么?我们在匀速系统中使用的过程模型,或者说状态外推方程是
\begin{align} x_{n+1 ,n} &= \hat x_{n,n} + \hat{\dot x}_{n,n}\Delta t\\ \dot x_{n+1,n} &= \hat{\dot x}_{n,n} \end{align}\\
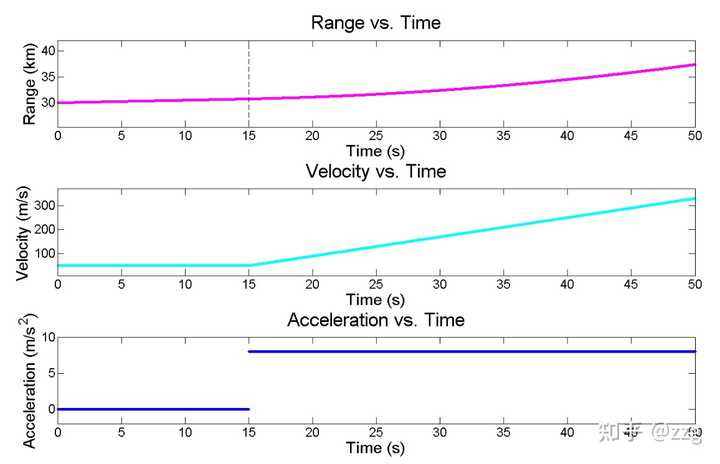
预测下一时刻的速度不变,但实际情况是匀加速的,而我们设置的 g-h参数(0.2 ,0.1)明显是更相信预测值的。因此最终滤波器应该会产生滞后,我们用数值案例来看最终的结果。飞行器的运动情况如下图所示,在0-15 匀速运动,在15-50 匀加速运动。



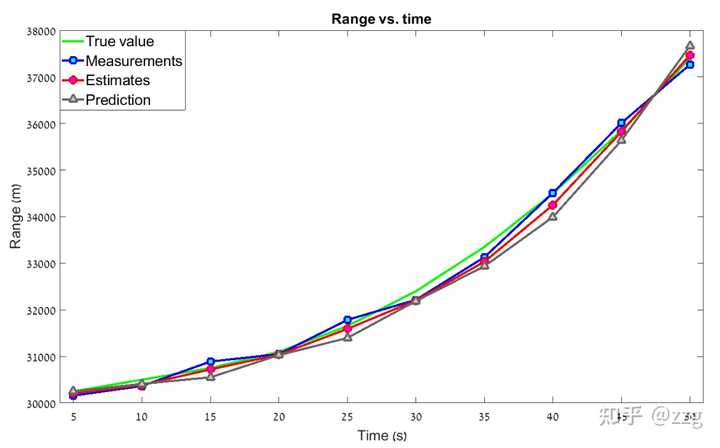
可以看到真实值或测量值与估计值之间存在一个固定的差值,这个差值被称为 滞后误差lag error 。滞后误差的其他常见名称有:
我们更正系统模型 , 为系统增加加速度 , 因此状态外推方程如下:
\begin{align} x_{n+1 ,n} &= \hat x_{n,n} + \hat{\dot x}_{n,n}\Delta t + \frac{1}{2} \hat{\ddot x}_{n,n} \Delta t^2\\ \dot x_{n+1,n} &= \hat{\dot x}_{n,n} + \hat{\ddot x}_{n,n}\Delta t\\ \ddot x_{n+1,n} &= \hat{\ddot x}_{n,n} \end{align}\\
式子中,速度用位移的一阶导数表示 : \hat{\dot x}_{n,n} , 加速度用位移的二阶导表示 : \hat{\ddot x}_{n,n} 状态更新方程我们增加对加速度的估计:
\begin{align} \hat x_{n,n} &= x_{n,n-1} + g(z_n-x_{n,n-1})\\ \hat {\dot x}_{n,n} &= \dot x_{n,n-1} + h(\frac{z_n-x_{n,n-1}}{\Delta t})\\ \hat {\ddot x}_{n,n} &= \ddot x_{n,n-1} + k(\frac{z_n-x_{n,n-1}}{0.5\Delta t^2})\\ \end{align}\\
经过数值案例迭代,最终得到的曲线如下图所示:
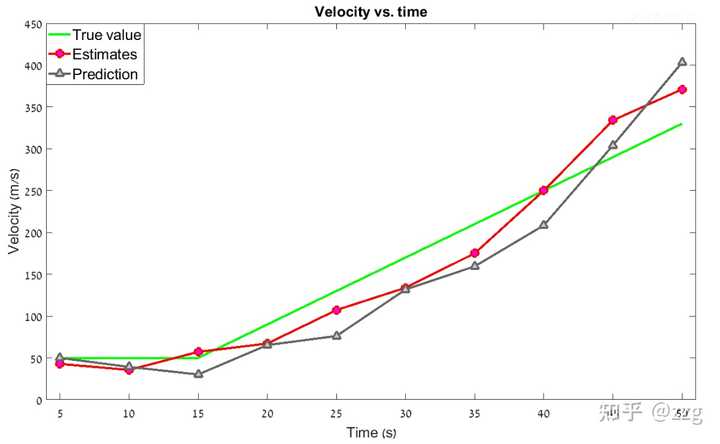
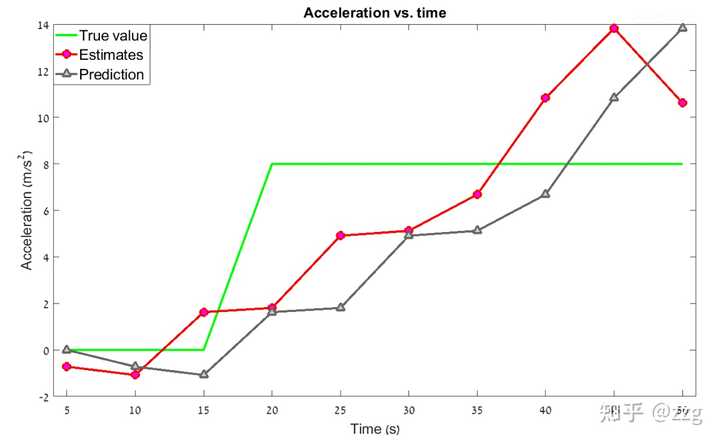
如图所见,包含加速度动态模型的 g-h-k 滤波器可以追踪匀加速运动的目标,并且消除滞后误差。但是如果目标的运动状态是高度变化的呢?目标可以通过转弯突然改变飞行方向,真实的目标动态模型可能包括一个突然加速(改变加速度),在这些情况下,具有恒定 g-h-k 系数的 g-h-k 滤波器会产生估计误差,在某些情况下甚至会追踪失效。
通用g-h滤波器Python实现
import numpy as np
def g_h_filter(zdata, x0, dx, g, h, dt=1.):
x_est = x0 #初始化的估计值
results = []
for z in zdata:
# prediction step
x_pred = x_est + (dx*dt)
dx = dx
# update step
residual = z - x_pred #残差
dx = dx + h * (residual) / dt
x_est = x_pred + g * residual
results.append(x_est)
return np.array(results)
这里 dx 表示 x 的变化率 , 是一个抽象的变量 , 我们前面的粒子就是速度,当然这里也可以增加x的二阶导数。 对于一个动态系统,可以用状态的多阶导数来表示,这一点在后面多维卡尔曼滤波中会介绍。
g-h参数调节
g是系统测量值的权重,需要根据传感器的精度和系统模型的精度共同来确定 , 比如你对系统模型不那么确定, 大致上是匀速,可能会有小的扰动,而传感器的精度很高,那就选择较高的g 值, h反应的系统状态变化的测量值权重 , 可以发现,h越大过滤器越灵敏 , 但太过灵敏可能导致滤波器过分偏向测量值,或者错误值。
g-h滤波器与卡尔曼滤波器的联系
看到这里,你可能会觉得,接下来终于可以学习卡尔曼滤波了。但其实 ,卡尔曼滤波 的 5个方程我们前面已经都使用过了,并且证明了它的由来 , 你知道是哪几个吗?如果没有深刻的印象 , 可以回过头再去看看贝叶斯滤波 和 上文。
g-h滤波器和卡尔曼滤波器有什么联系?我们知道g-h 滤波器的参数是通过 数值进行调整,从而得到适合参数,这种前提意味着,当系统变化较大时,有需要重新调节g-h 参数 ,才能达到理想的效果。就拿前面匀速和匀加速的例子来说,系统模型不可能这么完美 , 有时会出现大幅度的变化,比如突然转向,这个时候我们的g-h参数已经不太适合当前的变化了,就需要动态调整了,怎么去动态调整呢?这就是卡尔曼滤波做的事了。
我们在最优状态估计的证明中,提到了如何设置 g-h 值达到 最优估计 , 但是由于上面的例子没有引入概率(期望和方差),导致无法计算,只能通过数值迭代,来观察曲线,调整g-h 达到理想值。而卡尔曼滤波在g-h滤波器的基础上,引入概率,从而得到了最优状态估计。
假设你不知道有卡尔曼滤波,能否根据下面的一些启发推导出来?(体验一下卡尔曼老爷子是如何将两者关联起来的)
g-h滤波器给我们的启发
\begin{align} \hat x &= (1-w)x_1 + wx_2 = \frac {\sigma_2^2x_1 + \sigma_1^2x_2}{\sigma_1^2 + \sigma_2^2} \\ \sigma^2 &= \frac{\sigma_1^2\sigma_2^2}{\sigma_1^2+\sigma_2^2} \end{align}\\
贝叶斯滤波高斯分布给我们的启发
\begin{align} X \sim& N(\mu_X , \sigma_X^2)\\ Y \sim& N(\mu_Y , \sigma_Y^2)\\ Z =& X+Y \end{align}\\
则
\begin{align} Z \sim N(\mu_X+\mu_Y , \sigma_X^2 + \sigma_Y^2) \end{align}\\
X\sim N(\mu_x , \sigma_X^2)\\ Y\sim N(\mu_y , \sigma_Y^2)\\
则
\mu = \frac {\sigma_x^2\mu_y+\sigma_y^2\mu_x} {\sigma_x^2+ \sigma_y^2}\\ \sigma^2 = \frac {\sigma_x^2\sigma_y^2} {\sigma_x^2+\sigma_y^2}\\
\begin{align} P(post) =& \frac{P(Z|prior)P(prior)} {P(Z)}\\ =& \frac{\mathcal N(\mu_z, \sigma_z^2)*\mathcal N(\mu_p ,\sigma_p^2)}{Normal}\\ =& \mathcal N(\frac {\sigma_z^2\mu_p+\sigma_p^2\mu_z} {\sigma_z^2+ \sigma_p^2} , \frac {\sigma_z^2\sigma_p^2} {\sigma_z^2+\sigma_p^2})/Normal \end{align}\\
我们的后验估计结果:
\begin{align} \hat x &= \frac {\sigma_z^2\mu_p+\sigma_p^2\mu_z} {\sigma_z^2+ \sigma_p^2} \\ \sigma^2 &= \frac {\sigma_z^2\sigma_p^2} {\sigma_z^2+\sigma_p^2} \end{align}\\
结合两者得到卡尔曼滤波
\begin{align} x_{n+1 ,n} &= \hat x_{n,n} + \hat{\dot x}_{n,n}\Delta t \space\space \space\space \space\space\space\space (1) \\ \end{align}\\
进行预测 , 这里有很重要的一点,估计值 \hat x_{n,n} , \hat{\dot x}_{n,n} 符合高斯分布 , \Delta t 是常数 , 因此 状态外推方程是2个高斯函数相加 , 根据高斯函数的特点 ,结果仍为高斯函数,设状态变量的估计值的方差为 P , 状态变量的变化量的估计值方差为 \Delta P ,则可得到:
P_{n+1 , n} = P_{n,n} + \Delta P_{n,n}\\
这就是卡尔曼滤波方程的 : 协方差外推方程,至于为什么叫协方差而不是方差,是因为在多维的情况下,变量与变量之间还有关系,而且期望代数中可知,方差是协方差的特例。 协方差外推方程计算的是预测值的方差 , 或者说不确定度。往往更一般的形式会在预测中加入噪声,噪声的方差为Q , 则
\begin{align} x_{n+1 ,n} &= \hat x_{n,n} + \hat{\dot x}_{n,n}\Delta t +w\\ P_{n+1 , n} &= P_{n,n} + \Delta P_{n,n} + Q \space\space\space\space\space\space\space\space(2) \end{align}\\
我们已经得到了两个卡尔曼滤波方程 : 状态外推方程 , 协方差外推方程 ,到这里还只是运用了g-h 滤波器 和 高斯分布的加法特性 , 还没有结合贝叶斯滤波,很明显,贝叶斯滤波是在更新的过程中使用的。
我们学习了两种数据融合的方法,最终形成估计的方法, 一种是g-h 滤波器,加权平均进行更新 , 令一种是贝叶斯滤波 ,结合先验和测量得到后验。既然引入了概率 , 那么我更加希望使用贝叶斯滤波,我们在之前有见识过概率的力量 :我们得到的估计值有一个精度可以参考 , 比如温度 是95℃+-0.1 。而g-h滤波器呢 , 只有一个估计值,没有精度信息。但是按照g-h 滤波器使用加权平均方法 , 我们可以得到最优状态估计,前面也证明这一点 , 因此我们在引入概率后,可以从两个方面 来得到卡尔曼滤波方程。由g-h滤波器 的最优状态估计得到 , 由贝叶斯滤波方法得到。
g-h滤波器最优化角度得到:
最优化更新方程由前面证明得:
\begin{align} \hat x &= x_1 + w(x_2-x_1) = \frac {\sigma_2^2x_1 + \sigma_1^2x_2}{\sigma_1^2 + \sigma_2^2} \space\space\space\space\space\space\space\space(3)\\ \sigma^2 &= \frac{\sigma_1^2\sigma_2^2}{\sigma_1^2+\sigma_2^2} \end{align}\\
我们令 :
K_n = w = \frac {\sigma_1^2}{\sigma_1^2 + \sigma_2^2}\\
K_n 称为卡尔曼增益 ,其实就是先前的g , 只不过在g-h滤波器中 , g 是定值 , 而这里得卡尔曼增益是一个变值,其中 \sigma_1 ,\sigma_2 具体是预测方差和测量方差(因为 x_1 和x_2 这里具体指的是预测值 和测量值 , 由协方差外推方程可得到预测值方差 , 测量方差可根据传感器参数得到为 R , 则:
K_n = \frac {P_{n ,n-1}}{P_{n,n-1} + R_n} \space\space\space\space\space\space\space\space(4)\\
估计值的方差用 K_n 来表示:
P_{n,n} =\sigma^2 = \frac{\sigma_1^2\sigma_2^2}{\sigma_1^2+\sigma_2^2} = (1-K_n)P_{n,n-1}\space\space\space\space\space\space\space\space(5)\\
以上5个公式即为卡尔曼滤波公式 , 2个预测 , 2个更新 , 一个卡尔曼滤波增益。
从贝叶斯滤波的角度得到:
在预测步骤中 , 我们 通过状态外推方程和协方差外推方程得到了预测值 , 和预测值的方差 , 且由高斯函数的加法特性得知,预测值也是高斯函数。这个预测值在贝叶斯滤波中我们称为先验 , 表示出来 就是:
X_{predict} \sim \mathcal N(\mu_p ,\sigma_p^2)\\
经过测量后,得到测量值符合高斯分布 :
R \sim \mathcal N(\mu_z ,\sigma_z^2)\\
通过贝叶斯公式我们得到后验估计值:
\begin{align}3P(post) =& \frac{P(Z|prior)P(prior)} {P(Z)}\\4=& \frac{\mathcal N(\mu_z, \sigma_z^2)*\mathcal N(\mu_p ,\sigma_p^2)}{Normal}\\5=& \mathcal N(\frac {\sigma_z^2\mu_p+\sigma_p^2\mu_z} {\sigma_z^2+ \sigma_p^2} , \frac {\sigma_z^2\sigma_p^2} {\sigma_z^2+\sigma_p^2})/Normal\end{align}\\
可以观察到,最终的估计值,有一个不可思议的巧合。对比g-h 滤波器推导出的 加权平均最优估计的结果 , 会发现惊人的相同 。 估计值和方差 都一样,很好奇当时卡尔曼老爷子到底是为什么选择高斯分布 ? 是从g-h滤波器最优估计得到卡尔曼滤波方程的还是先通过贝叶斯滤波得到估计值 , 然后发现居然结果和g-h滤波器的最优状态估计结果相同的?
到这里,相信已经能够理解卡尔曼滤波和贝叶斯滤波 ,g-h滤波的关系了。 卡尔曼滤波 基础主要是 3大块 , 贝叶斯 , 高斯 , g-h 滤波器。如果还不能理解,建议反复阅读读懂的章节。
下节预告:一阶线性卡尔曼滤波
主要说应用相关,以及为何上述的卡尔曼滤波只能在线性系统中使用 , 若是非线性的系统会造成什么 , 什么情况下会引入非线性。
参考资料
https://www. kalmanfilter.net/defaul t.aspx
https:// github.com/rlabbe/Kalma n-and-Bayesian-Filters-in-Python










