论文题目: CN-RMA: Combined Network with Ray Marching Aggregation for 3D Indoor Object Detection from Multi-view Images
作者:Guanlin Shen,Jingwei Huang等
作者机构:School of Software, Tsinghua University, China ,Tencent, China等
论文链接:https:// arxiv.org/pdf/2403.0419 8.pdf
代码链接:https:// github.com/SerCharles/C N-RMA
这篇论文介绍了一种名为CN-RMA的新方法,用于从多视角图像中检测3D室内物体。该方法利用了3D重建网络和3D物体检测网络的协同作用,通过重建网络提供的粗略距离函数和图像特征的投票,在解决图像和3D对应关系模糊性的挑战上取得了成功。具体而言,通过射线行进为每条射线的采样点分配权重,表示图像中一个像素对应的3D位置的贡献,并通过预测的有符号距离确定权重,使图像特征只投票到重建表面附近的区域。该方法在ScanNet和ARKitScenes数据集上实现了最先进的性能。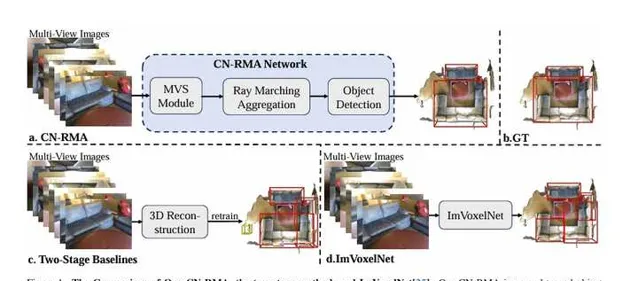
读者理解:
本文介绍了一种名为CN-RMA的新方法,用于从多视图图像中进行室内3D物体检测。该方法通过引入一种名为Ray Marching Aggregation(RMA)的技术,能够有效地将2D特征聚合到3D点云中,并考虑了遮挡情况,从而在性能上超越了先前的方法。作者还对该方法进行了详细的实验验证,并与其他方法进行了比较,结果表明CN-RMA在两个数据集上均取得了优越的性能。
原文链接:清华最新! CN-RMA:CVPR'24 多视角3D室内物体检测我认为这项研究在解决室内3D物体检测问题上具有重要意义。通过有效地利用多视图图像和引入遮挡感知的聚合技术,CN-RMA能够更准确地检测物体,这对于室内环境中的智能机器人和自动驾驶等应用具有很大的潜在应用价值。作者提出的方法也为未来相关研究提供了新的思路和方法,有助于推动这一领域的发展。
1 引言
这篇论文提出了一种名为CN-RMA的新方法,用于从多视角图像中检测3D物体。传统方法是先从多视角图像中重建3D场景,然后从重建的点云中进行物体检测,但这种方法存在两个阶段之间缺乏连接性的问题。本文提出的方法通过将重建网络和检测网络无缝结合,并引入遮挡感知的特征聚合模块,有效地解决了这一问题。具体而言,该方法首先使用多视角立体匹配(MVS)模块重建粗略的场景几何,然后利用名为射线行进聚合(RMA)的遮挡感知聚合模块,在3D空间中聚合图像特征,并在重建表面附近提取具有聚合特征的点云进行物体检测。通过预训练和微调整个网络,使其各组件协同工作,达到最佳性能。该方法在ScanNet和ARKitScenes数据集上取得了显著的性能改进,包括[email protected]和[email protected]方面分别提高了3.2和3.0在ScanNet中,以及在ARKitScenes中分别提高了7.4和13.1。这表明了该方法在室内多视角图像中的3D物体检测任务上取得了最先进的性能。
本文贡献:
2 方法
2.1 问题表述
本研究旨在利用多视角图像及其相应的相机参数,在复杂的遮挡场景中实现精确的3D物体检测。为此,提出了一个流程,通过结合MVS重建模块和3D检测网络,并引入了遮挡感知的特征聚合方法,实现了该目标。流程包括以下步骤:
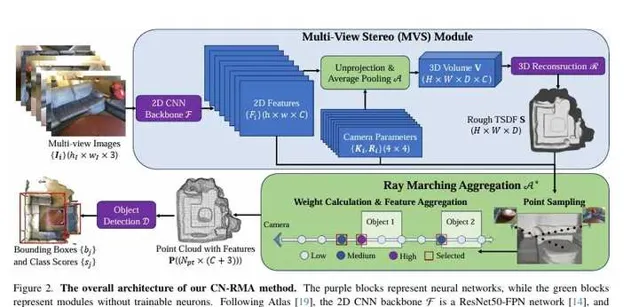
2.2 多视角立体匹配模块
本节介绍了多视角立体匹配模块(MVS),旨在通过多视角图像和相应的相机参数实现精确的3D物体检测。为此,使用Atlas作为MVS模块,它可以以端到端的方式训练和使用来预测重建,包括一个2D骨干和一个3D重建网络。具体步骤包括:
这种方法可以避免遗漏检测,并在训练中提高泛化能力。

2.3 射线行进聚合
本节介绍了射线行进聚合(RMA)方法,用于改进在重建阶段通过直接平均提升的图像特征来预测3D特征体积的方法。由于图像特征可能会投票到未观测到的空间,造成体积特征受到某些视图的污染,因此需要处理遮挡。为了提高鲁棒性,引入了一种软遮挡感知聚合方案RMA,灵感来自于NeRF和NeuS。具体而言,根据NeuS,作者根据TSDF计算体积密度。通过射线行进在每个像素的射线上采样点,并根据NeRF累积透射率来计算每个点的不透明度。因此,可以通过加权平均图像特征来计算3D特征,权重由不同视图的透射率确定。最终,提取接近重建表面的点和聚合特征,并将点云传递给3D检测模块进行物体检测。
2.4 3D物体检测网络
本节介绍了3D物体检测网络,该网络接收重建的点云和聚合特征P作为输入,使用FCAF3D作为检测网络。首先,将P转换为稀疏体素,并传递给FCAF3D以预测每个体素的分类分数、边界框回归参数和3D中心度。检测损失由焦点损失、IOU损失和二元交叉熵损失组成,用于监督网络的训练。
2.5 训练过程
本节讨论了训练过程。由于架构复杂,同时结合了MVS模块和检测网络,因此从头训练可能导致过拟合。为了解决这个问题,采用了预训练和联合微调的方案。首先,对2D骨干和3D重建网络进行预训练,利用重建损失以充分利用3D几何信息。然后,冻结这些网络,进行3D检测网络的预训练,只考虑检测损失。最后,通过联合微调整个网络,平衡重建损失和检测损失,以获得最终的3D检测结果。

3 实验
实验部分主要包括以下内容:
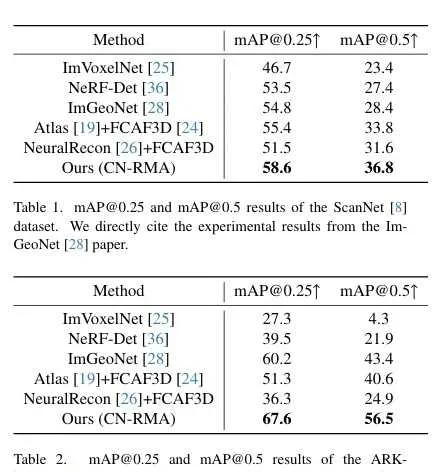
数据集、指标和基线方法:使用了两个室内物体检测数据集,分别是ScanNet和ARKitScenes。ScanNet包含1201个训练扫描和312个测试扫描,检测使用轴对齐边界框(AABB);ARKitScenes包含4498个训练扫描和549个测试扫描,检测使用定向边界框(OBB)。评估指标为[email protected]和[email protected]。基线方法包括ImVoxelNet、NeRFDet和ImGeoNet,以及两阶段基线方法,其中Atlas和NeuralRecon用于重建3D点云,FCAF3D用于3D检测。
实现细节:使用MMDetection3D框架实现CN-RMA方法,设置特征通道数为32,聚合方法的权重阈值为0.05,损失权重为0.5。在射线行进中,为每个像素采样300个点,最大t设置为体积V的对角线长度。所有实验在4个NVIDIA A6000 GPU上进行,批大小为1。
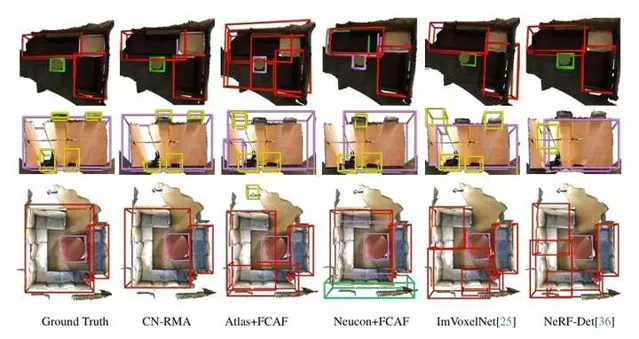
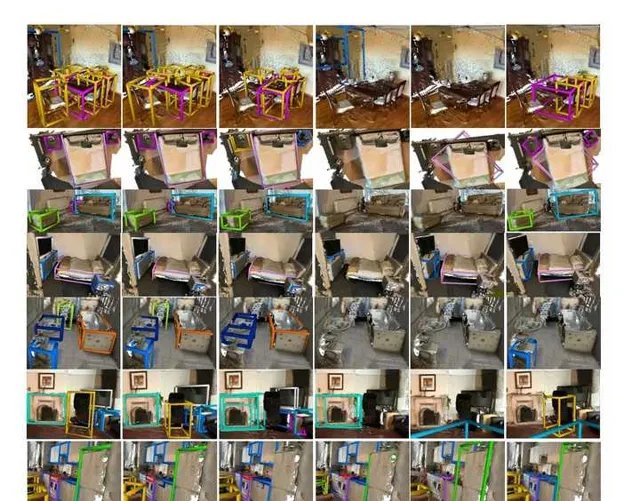
比较结果:在ScanNet和ARKitScenes数据集上,CN-RMA方法表现优异,[email protected]和[email protected]均优于其他方法。与ImGeoNet相比,在ScanNet上[email protected]提高了3.8,[email protected]提高了8.4,在ARKitScenes上[email protected]提高了7.4,[email protected]提高了13.1。与Atlas和FCAF3D组合的两阶段基线相比,在ScanNet上[email protected]提高了3.2,[email protected]提高了3.0,在ARKitScenes上[email protected]提高了16.3,[email protected]提高了15.9。
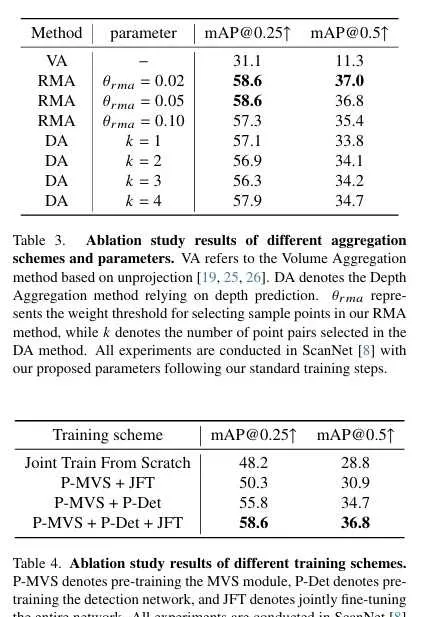
消融研究:对不同聚合方案和超参数进行了消融研究,结果表明RMA方法在选择样本点的权重阈值为0.05时表现最佳。另外,对不同训练方案进行了消融研究,结果表明预训练MVS模块和检测网络,然后联合微调整个网络可以取得最佳性能。
4 总结
本文介绍了一种新颖的从多视图图像中进行室内3D物体检测的方法CN-RMA。作者的方法超越了先前的最先进方法,并优于两阶段基线。作者还提出了一种有效的考虑遮挡的技术,通过粗糙的场景TSDF将2D特征聚合到3D点云中,这对于将其整合到其他从多视图图像中理解3D场景的任务中具有潜力。未来的工作应集中于探索进一步提高CN-RMA性能的技术,例如研究替代的聚合方案或整合额外的上下文信息,这可能是有益的。作者期待通过解决这些限制并建立在我们的研究成果基础上,进一步推动3D室内物体检测和相关研究领域的进展。

移步公众号「3D视觉工坊」第一时间获取工业3D视觉、自动驾驶、SLAM、三维重建、最新最前沿论文和科技动态。
推荐阅读
1、基于NeRF/Gaussian的全新SLAM算法
2、移动机器人规划控制入门与实践:基于Navigation2
3、自动驾驶的未来:BEV与Occupancy网络全景解析与实战
4、面向三维视觉的Python从入门到实战
5、工业深度学习异常缺陷检测实战
6、Halcon深度学习项目实战系统教程










