或者这篇文章能给提问者一个新的思路,了解一下在自动驾驶领域,决策AI(RL)与SLAM的结合将会碰撞出什么样的火花~衷心希望能够帮助到提问者。
以下是正文部分:
自动驾驶是一项人类憧憬已久的人工智能技术。在许多科幻文艺作品中,自动驾驶都是未来人机共融世界中的「标配」。一百多年前的人们就已经在构想,未来世界完全不需要人类手动控制就可以驰骋在高速公路上的场景。

在学术界和工业界中,虽然自动驾驶已经被研究了数十年,但距离文艺作品中想象的应用能力,仍然有一定的距离。
究其原因,自动驾驶是一个多学科交叉的系统,其中的核心模块可大致划分为三个模块: 感知、决策、和控制 ,而每个模块下都有许多细分的亟待解决的问题。
在感知模块中,空间位置的感知是自动驾驶车辆能够实现自主运动的基石,其对应的学术问题于1986年被明确定义并提出,被称为SLAM。
在决策型AI发展大行其道的当下,SLAM技术能为决策型AI带来哪些耦合影响,二者在自动驾驶任务中的联系和区别又有哪些呢,本文将简单地介绍这些问题。
一、让我们来谈一谈什么是SLAM
从模块功能的角度来说,如果只想知道智能体周围有哪些物体和他们的位置,那么只需要以深度学习为主要技术手段的 目标检测或实例分割 就可以了。但如果还想要智能体能够 自主在环境中运动和避障 ,就需要使用SLAM技术了。
SLAM的全称是simultaneous localization and mapping,即同步定位与建图 ,它解决的是一个智能体在未知环境当中 感知并定位 周围环境和自身,并随着自身运动逐渐掌握所在环境整体地图的能力。
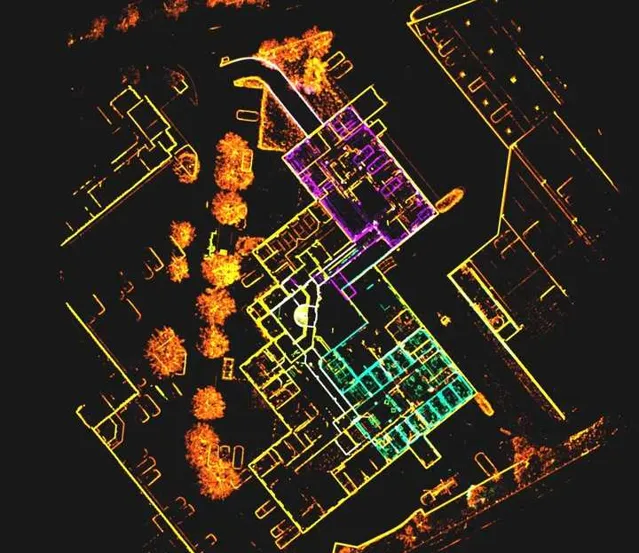
SLAM可以构建世界的3D环境模型,同时确认自身在环境中的位姿,它关注的是 空间几何信息 。这一过程类似于游戏中的「开地图」,一个被控制的单位不仅能感知到周围的一圈地图元素,在行进的过程中也把历史信息融入进来,画成了一个「小地图」。
对自动驾驶任务来说,虽然现在基于卫星定位的高精地图导航可以做到对自车的精准定位,但限于 精度和网络传输问题 ,在驾驶的局部区域还是需要SLAM技术来为车辆的驾驶提供更精细的感知信息。
目前SLAM算法可以分为 跟踪和建图 两个主要部分。
顾名思义, 跟踪部分 主要负责以建立的环境模型或是历史的传感观测为参考系,估计智能体或车辆的位姿;而 建图部分 则是使用已估计的位姿序列将环境的三维模型建立。

环境模型根据地图的尺度绝对性可以划分为 栅格地图、拓扑地图和米制地图 ;根据环境信息的表征层级可以划分为物体(语义)级地图和特征地图,后者又可以根据点的稠密程度可以划分为稀疏地图和稠密地图。目前SLAM算法仅考虑自身的参考定位需求,往往仅构建稀疏点特征地图。
传统的SLAM算法仅需将对输入的传感量测序列映射为位姿轨迹序列和环境模型即可。 但在实际应用中,人们发现某些运动过程不利于定位跟踪,比如快速的旋转运动;环境中的部分区域往往需要更完备地传感观测才能建立出满足应用需求的环境模型;以及采集到的传感数据并不能覆盖整个需要探索感知的环境等等。
因此,有学者提出了 主动SLAM 的概念,即智能体在进行SLAM的同时,根据当前定位和所建模型的不确定性,主动控制自身的运动以提高环境探索效率,定位和建模精度。就好比为了更好的探索未知的或不确定的环境,派一个「小弟」专门前去看看,对建图问题的解决更加有益。
二、决策AI,全自动驾驶离不开的关键技术
决策AI是以 强化学习 为代表的,不同于感知型AI的新型人工智能技术。强化学习是机器学习方法的一种,其基于本体于环境交互过程中获得的反馈指导策略模型为进化方向。因此,强化学习一般用于处理决策规划型的问题,比如代替游戏玩家、控制智能汽车、构建推荐系统等等。
标准化的强化学习算法由 环境、状态、行动、奖励和智能体 五个元素构成。
环境 是智能体所处的空间; 状态 是指智能体进行决策时所需要的信息集合,一般既包括智能体所处环境的描述,也包括智能体自身境况的描述,比如位置、速度等等; 行动 是智能体所能和环境进行交互的方式,也可理解为所能选择的决策集合; 奖励 则是由环境对智能体所选择的行动给出的反馈。

随着深度学习所展现出的强大的从高维数据中寻找到低维结构的能力,当前强化学习算法所使用的模型一般为神经网络模型。于是强化学习也就变成了深度强化学习。
虽然强化学习已经被研究多年,但其距离实际应用依然有一定距离。以本文所关注的自动驾驶为例,自动驾驶车辆所搭载的传感器一般以视觉系统为主。
然而,虽然从传感到动作这种端到端的处理方式备受追捧,但是如果直接将原始获得的视觉观测图像作为强化学习的状态输入智能体,往往并不能将模型训练得多好。
这主要是由于视觉图像本身就处于 高维流形 上,视觉模型的训练需要大量的数据,而强化学习方法的标签比监督学习要稀疏的多。到目前为止,用强化学习方法从视觉图像中提取有价值的信息并没有完全解决,无论是是重建出图像所拍摄场景的三维模型,亦或是估计观察到该幅图像所可能的空间位置。
即便是检测图像中是否存在目标物体,在目标检测各类榜单已经被刷爆的当下,采用强化学习,这种以环境反馈为为指引模型进化方向的学习方式下,依然困难重重。
三、决策AI与SLAM结合,会产生怎样的火花
经过以上介绍,我们想到,是否可以利用SLAM这项成熟的技术与强化学习方法结合来更好的解决二者的问题呢?答案是肯定的,大体上来说,二者的结合在以下两个层面可以发挥作用,为自动驾驶应用中的一些问题提供解决方案。
1. SLAM建模的环境可考虑作为强化学习的状态输入
为了应对前文所介绍的使用强化学习端到端地处理原始传感数据遇到的问题,目前许多研究者已经转向了多层次强化学习的构建。
如TRO20年的一篇研究[1]提出将智能体的视觉导航解耦为两个阶段解决,第一阶段使用目标网络,将视觉传感观测转为所要运动到的目标点。而第二阶段,则是使用探索网络,控制智能体到达目标点。这样就将原本状态量中的高维图像矩阵映射为仅有几位数值即可表征环境信息和智能体状态信息的地位向量。
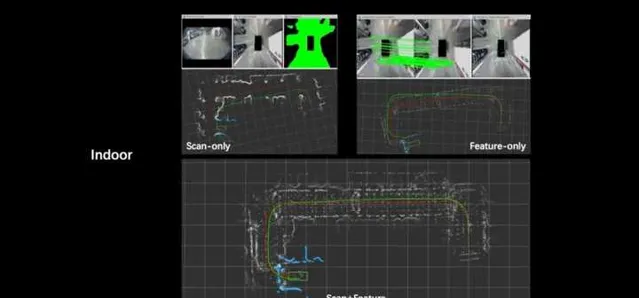
诸如此类的体系设计还有很多。然而使用网络对环境建模的方式看似「智能「,但实际上效率较低,可解释性也欠缺。在实际应用中的建模精度、路径规划安全性和可执行性都无法保证。
而SLAM模块已经具备解析地重建环境模型的能力。完全可以取代前文中第一阶段的模型,完成任务的需求。
具体说来,可以设计相应的SLAM建图模块,使得SLAM所建立的环境模型能够标准化、统一地作为状态集合中的子集,并被强化学习模块所直接使用。此外,强化学习在完成任务规划决策时, 可以同时将自身定位和环境模型的不确定度纳入考虑 (这些信息也是SLAM算法可以提供的)。这样做也更加符合智能体实际的传感感知能力。
2.强化学习的动作选择可提升SLAM建模环境的效率
目前主动SLAM所需要具备的智能体探索路径规划和运动控制,仍然缺少好的解决思路。 强化学习作为决策模型中最具有智能化潜质的一种,完全具备应用在主动SLAM中扮演规控大脑的能力。
Botteghi[2]已经在这个方向上做了探索,基于简单的DQN和特别设计的奖励函数,便提高了主动SLAM探索环境并建立模型的效率。
事实上,在SLAM建立未知环境的地图时,智能体的运动路径不仅会影响其所建的环境地图是否将整个环境都覆盖,还会直接影响智能体定位的精度,从而间接决定了环境重建的质量。

比如,在环境纹理稀疏时,处于转弯角度较大的拐角时,甚至是相机视角狭窄的配置下,如果智能体运动速度过快,往往都会导致特征点跟踪丢失,从而使得整个SLAM算法失效。
另外,对于SLAM算法来说,如果能够及时地构成运动路径闭环,对于消除定位过程中的累积误差,避免视点漂移都有极大的利好。
上述这些需求就不再是简单的规划位移级的路径,而需要到速度级甚至是加速度级。而另一方面,目前尚没有成熟的算法能够寻找到视觉观测到基于其进行理想的SLAM任务所需要的运动状态之间映射关系。但运动动作所导致的定位和建图结果则能直接地提供反馈,而这恰恰符合强化学习所能解决的问题的特征。
OpenDILab目前就正在做一款自动驾驶领域的研究平台: DI-drive ,支持各种模仿学强化学习等决策算法,支持 多模态类型的输入输出,支持高度定制的可视化模块 ,为自动驾驶和决策 AI 搭建了至关重要的桥梁。DI-drive 尝试构建了一些以俯视图作为输入状态的决策AI驾驶环境,这与SLAM想要构建的环境模型与地图理解有共同之处,可以作为SLAM与决策AI结合的一个切入点,欢迎大家体验使用。


⭐️ 欢迎大家体验DI-drive:
总结 可以想象,有了强化学习的参与,SLAM过程的定位会更精确,重建模型的质量更高;而有SLAM帮助解析的环境和智能体自身训练,由强化学习训练得到的用于生成自动驾驶路径规划轨迹的模型训练可以更简单,也就更容易收敛,从而让决策AI 能够更高效地解决自动驾驶任务。
参考文献
[1] Devo, Alessandro,et al. "Towards generalization in target-driven visual navigation by using deep reinforcement learning." IEEE Transactions on Robotics 36.5 (2020): 1546-1561.
[2] Botteghi,N.,et al. "Reinforcement learning helps slam: Learning to build maps." The International Archives of Photogrammetry, Remote Sensing and Spatial Information Sciences 43 (2020): 329-335.
✨运营:mugicaxu
✨排版:yicc












