2016年,DeepMind的圍棋機器人AlphaGo在與李世石的第二局對決中第37手落子的瞬間,整個圍棋界都震驚了。評棋人Michael Redmond,一位有著近千場頂級比賽經驗的職業棋手,在直播中目瞪口呆,他甚至把這顆棋子從棋盤上拿下來觀察周邊的情況,仿佛要確認AlphaGo是否下錯了棋。第二天,Redmond告訴美國圍棋E雜誌:「我到現在還不明白這步棋背後的道理。」李世石這位統治了世界棋壇十年的大師,花了 12 分鐘來研究這一棋局,之後才做出回應。圖 13-1展示了這手傳說中的落子。
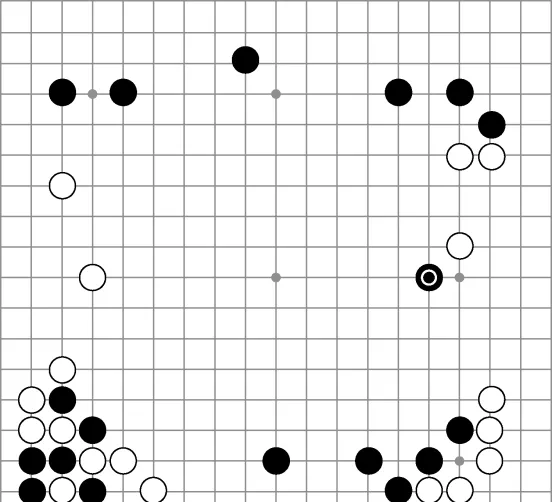
圖13-1 AlphaGo在對陣李世石的第二局中做出的傳奇落子動作。這手落子震驚了許多職業棋手
這手落子完全違背了傳統的圍棋理論。對角落子,或者叫尖沖,會引誘白子沿著邊界繼續長出,並做出一道實墻。人們通常認為這是一個五五開的交換:白方獲得邊界的空點,而黑方則獲得對棋盤中央區域的影響力。但是白棋落在離邊界4格的地方,一旦讓黑方做出實墻,黑方會得到過多的地盤。(我們需要對正在閱讀的圍棋高手表示歉意,這裏的描述做了過多的簡化。)第5行的尖沖看起來有些業余——至少在「AlphaGo教授」最終五局四勝戰勝這位傳奇棋手之前看來確實如此。在這一步尖沖之後,AlphaGo還做出了許多出人意料的落子動作。一年之後,上到頂級職業棋手,下至業余俱樂部棋手,所有人都在嘗試模仿AlphaGo所采用的動作。
【深度學習與圍棋】這本書的第二部份分層次深入介紹AlphaGo背後的機器學習和深度學習技術,包括樹搜尋、神經網路、深度學習機器人和強化學習,以及強化學習的幾個高級技巧,包括策略梯度、價值評估方法、演員-評價方法 3 類技術;第三部份將前面兩部份準備好的知識整合到一起,並最終引導讀者實作自己的AlphaGo,以及改進版AlphaGo Zero。讀完本書之後,讀者會對深度學習這個學科以及AlphaGo的技術細節有非常全面的了解,為進一步深入鉆研AI理論、拓展AI套用打下良好基礎。
小編截選 AlphaGo:全部集結 的部份內容來回答這個問題。
我們將學習組成AlphaGo的所有結構,並了解它的工作機制。AlphaGo是基於職業棋譜的監督深度學習(即我們在第5章至第8章中所學的)與基於自我對弈數據的深度強化學習(即第9章至第12章所介紹的)的一種巧妙結合,然後再創造性地用這兩種深度學習網路來改進樹搜尋。讀者可能會感覺驚奇,原來我們已經對AlphaGo的所有元件都有所了解了。更精確地說,我們將要詳細介紹AlphaGo系統的如下流程工作。
圖13-2歸納了我們剛剛列出的整個流程。在本章中,我們會深入討論圖中的各個部份,並在各節中提供更多的細節。
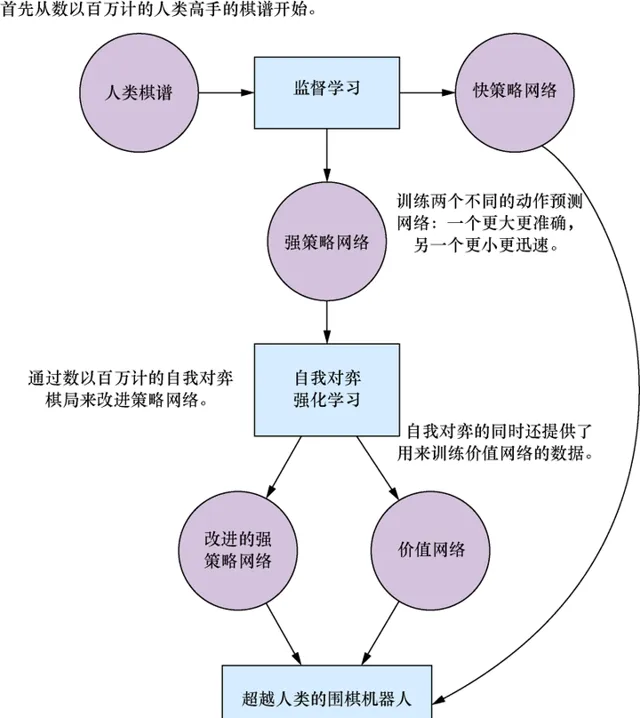
圖13-2 如何訓練AlphaGo AI背後的3個神經網路。首先,從人類棋譜集合開始,訓練兩個神經網路來預測下一步動作:一個網路更小更迅速,而另一個更大更準確。接著,我們可以繼續透過自我對弈來改進較大網路的效能。自我對弈同時也為訓練一個價值網路提供了數據。最後,AlphaGo會在一個樹搜尋演算法中同時采用這3個網路,得到極強的對弈表現
13.1 為AlphaGo訓練深度神經網路
在前面的介紹中我們已經了解到,AlphaGo使用了3個神經網路:2個策略網路和1個價值網路。雖然看起來有點多,但在本節中我們將會看到,這幾個網路以及它們的輸入特征在概念上是很接近的。而關於AlphaGo所用的深度學習技術,最令人驚奇的地方反而是我們對它們的熟悉程度,本書在第5章至第12章已經對它們做了大量的介紹。在深入介紹這幾個神經網路的構建和訓練的細節之前,讓我們先討論一下它們在AlphaGo系統中所扮演的角色。
13.1.1 AlphaGo的網路架構
現在我們已經基本了解了這3個深度神經網路在AlphaGo中的作用,下一步接著展示如何在Python的Keras庫構建它們。在深入討論程式碼之前,我們先概述這幾個網路的架構,如下所示。如果讀者需要溫習摺積網路的術語,請再次閱讀第7章。
可以看到,在AlphaGo中策略網路和價值網路采用的正是第6章所介紹的深度摺積神經網路。這兩個網路非常相似,我們甚至可以直接用一個Python函式來定義它們。在此之前,我們先看看Keras的一種特殊用法,它可以顯著地縮短網路的定義。第7章中講過,我們可以使用Keras的
ZeroPadding2D
實用工具層來對齊輸入影像。這樣做完全沒問題,但如果把它的功能移入
Conv2D
層中,就能在模型定義時節省許多筆墨。在價值網路和策略網路中,可以對齊每個摺積層的輸入,使它們的輸出過濾器的尺寸與輸入
相同
(19×19)。例如,按照我們以往的做法,第1層有19×19輸入,第2層核心尺寸為5,輸出是19×19過濾器,需要將第1層對齊成23×23的影像。而現在我們可以直接讓摺積層維持輸入尺寸,只需在定義摺積層時提供參數
padding='same'
,它就能夠自己處理對齊操作了。有了這種快捷定義,接下來我們就可以方便地定義AlphaGo的策略網路與價值網路所共有的11個層,如程式碼清單13-1所示。讀者可以在GitHub程式碼庫中的dlgo.networks模組中的alphago.py檔中找到這個定義。
程式碼清單13-1 為AlphaGo的策略網路和價值網路初始化神經網路
from keras.models import Sequential
from keras.layers.core import Dense, Flatten
from keras.layers.convolutional import Conv2D
def alphago_model(input_shape, is_policy_net=False, ⇽--- 這個布爾值選項用來在初始化時指定是策略網路還是價值網路
num_filters=192, ⇽--- 除最後一個摺積層之外,所有層的過濾器數量都相同
first_kernel_size=5,
other_kernel_size=3): ⇽--- 第1層的核心尺寸為5,其他層都是3
model = Sequential()
model.add(
Conv2D(num_filters, first_kernel_size, input_shape=input_shape,
padding='same',
data_format='channels_first', activation='relu'))
for i in range(2, 12): ⇽--- AlphaGo的策略網路和價值網路的前12層完全一致
model.add(
Conv2D(num_filters, other_kernel_size, padding='same',
data_format='channels_first', activation='relu'))
註意,我們還沒有指定第1層的輸入形狀。這是因為這個形狀在策略網路和價值網路中略有不同。我們可以在13.1.2節介紹AlphaGo的棋盤編碼器的程式碼中看到這個區別。繼續
model
的定義,我們還差一個最終摺積層就能完成強策略網路的定義,如程式碼清單13-2所示。
程式碼清單13-2 在Keras中建立AlphaGo的強策略網路
if is_policy_net:
model.add(
Conv2D(filters=1, kernel_size=1, padding='same',
data_format='channels_first', activation='softmax'))
model.add(Flatten())
return model
可以看到,最後需要添加一個
Flatten
層來展平前面的預測輸出,並確保與第5章至第8章中定義的模型的一致性。
如果想要返回的是AlphaGo的價值網路,可以再添加兩個
Conv2D
層、一個
Flatten
層和兩個
Dense
層,然後將它們連線起來,如程式碼清單13-3所示。
程式碼清單13-3 在Keras中構建AlphaGo的價值網路
else:
model.add(
Conv2D(num_filters, other_kernel_size, padding='same',
data_format='channels_first', activation='relu'))
model.add(
Conv2D(filters=1, kernel_size=1, padding='same',
data_format='channels_first', activation='relu'))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dense(1, activation='tanh'))
return model
這裏我們不具體討論快策略網路的架構。快策略網路的輸入特征定義與網路架構有更多技術細節,但並不能幫助我們加深對AlphaGo系統的理解。所以如果讀者想要進行自己的試驗,完全可以直接采用我們在dlog.networks模組中已經定義好的網路,例如
small
、
medium
或
large
。快策略網路的主要目的是構建一個比強策略網路更小的網路,能夠進行快速評估。接下來我們會深入了解訓練過程的細節。
13.1.2 AlphaGo棋盤編碼器
現在我們已經了解了AlphaGo使用的所有網路,下面討論一下AlphaGo如何對棋盤數據進行編碼。在第6章和第7章中我們已經實作了不少棋盤編碼器,包括
oneplane
、
sevenplane
和
simple
,這些編碼器都存放在dlgo.encoders模組中。AlphaGo所使用的特征平面會比它們更復雜一些,但也是這些已知編碼器的自然延續。
AlphaGo策略網路所用的棋盤編碼器有48個特征平面,而它的價值網路還需要再添加一個平面。這48個平麵包含11種概念,其中一部份是我們已經見過的,其他則是新的,我們會逐一詳細討論。總的來說,與以往的編碼器相比,AlphaGo更多地利用了圍棋專有的定式。最典型的例子就是在特征集合中引入了 征子和引征 概念(參見圖13-3)。
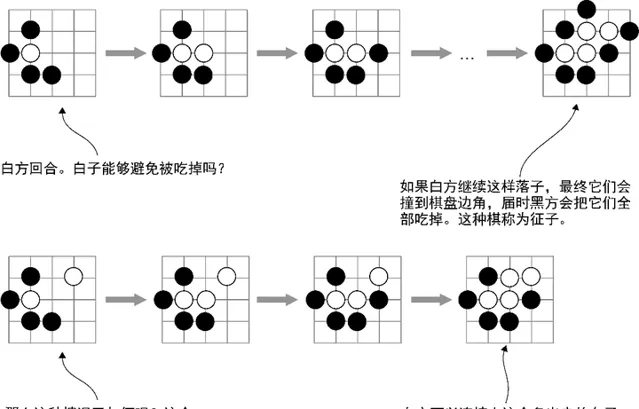
圖13-3 AlphaGo將很多圍棋策略概念直接編碼到特征平面中,包括征子概念。在第一個例子中,白子只剩一口氣了,這意味著黑方可以在下一回合吃掉它。白方可以長出來增加一口氣,但是黑方也可以接著落子將白子的氣減少為一口。這樣一直持續下去,直到碰到棋盤邊線,白子還是會被全部吃掉。而在另一種情況下,如果在征子的路線上已經有一顆白子,白方就有可能逃離被吃子的命運。AlphaGo中有一個特征平面專門用來表示征子是否能成功
我們之前所有的圍棋棋盤編碼器都采用了一個技巧,即 二元特征 ( binary feature ),這個技巧在AlphaGo中也被采用。例如,在捕獲氣的概念(棋盤上相鄰的空白點)時,我們並不只用一個特征平面來表示棋盤上每顆棋子的氣數,而是用3個二元表達的平面來表示一顆棋子是有1口氣、2口氣還是3口氣。在AlphaGo中也可以看到相同的做法,但是它采用了8個特征平面來記錄二元計數。在氣的例子中,這意味著8個平面分別代表每顆棋子是否有1口、2口、3口、4口、5口、6口、7口和至少8口氣。
AlphaGo與第6章至第8章中介紹的唯一不同點在於,它將棋子的顏色獨立出來,顯式地編碼到另一個單獨的特征平面中。回顧一下第7章的
sevenplane
編碼器,我們的眼平面同時包含黑子平面和白子平面,而AlphaGo只用一個特征集合用來記錄氣的數量,並且所有的特征都是針對下一回合的執子方。例如,在特征集「吃子數」(用來記錄一個動作能吃掉的棋子數目)中,只記錄
當前
執子方能夠吃掉的棋子數量,不論它是黑方還是白方。
表13-1總結了AlphaGo所使用的全部特征平面。前48個平面用於策略網路,最後一個只用於價值網路。
表13-1 AlphaGo所使用的特征平面(略)
這些特征的實作可以在本書的GitHub程式碼庫中的dlgo.encoder模組中找到,檔是alphago.py。雖然每一個特征集的實作都不困難,但和我們將要介紹的AlphaGo其他部份相比,它們並不顯得很有趣。實作「征子提子」平面難度較高,而且要對一個動作從執行時到現在的回合數進行編碼,需要修改圍棋棋盤的定義。因此如果讀者對這些實作有興趣的話,可以參看GitHub上的實作程式碼。
讓我們看看
AlphaGoEncoder
如何初始化,然後把它套用到深度神經網路的訓練中。它需要一個圍棋棋盤尺寸參數,以及一個布爾值參數
use_player_plane
(代表是否包含第49個平面)。程式碼清單13-4展示了它的簽名以及初始化過程。
程式碼清單13-4 AlphaGo棋盤編碼器的簽名以及初始化
class AlphaGoEncoder(Encoder):
def __init__(self, board_size, use_player_plane=False):
self.board_width, self.board_height = board_size
self.use_player_plane = use_player_plane
self.num_planes = 48 + use_player_plane
13.1.3 訓練AlphaGo風格的策略網路
網路架構和輸入特征都準備好之後,我們開始為AlphaGo訓練策略網路。第一步與第7章的流程完全一致:指定一個棋盤編碼器和一個代理,載入棋譜數據,並使用這些數據來訓練代理。圖13-4展示了這個流程。雖然我們使用了更加復雜的特征和網路,但流程還是完全一樣的。
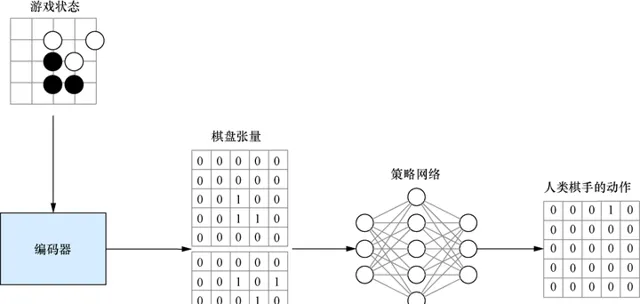
圖13-4 AlphaGo的策略網路監督訓練過程與第6章和第7章中介紹的完全一致。我們對人工棋譜進行復盤,並重新產生一系列遊戲狀態。每個遊戲狀態編碼為一個張量(這個圖展示了一個只有兩個平面的張量,而AlphaGo實際使用了48個平面)。訓練目標是一個與棋盤尺寸相同的向量,並在實際落子點填入1
要初始化並訓練AlphaGo的強策略網路,需要先初始化一個
AlphaGoEncoder
,然後建立兩個圍棋數據生成器,分別用於訓練和測試,如程式碼清單13-5所示。這個步驟與第7章一樣。這一步的程式碼可以在GitHub上的examples/alphago/alphago_policy_sl.py檔中找到。
程式碼清單13-5 為AlphaGo的策略網路的第一步訓練載入數據
from dlgo.data.parallel_processor import GoDataProcessor
from dlgo.encoders.alphago import AlphaGoEncoder
from dlgo.agent.predict import DeepLearningAgent
from dlgo.networks.alphago import alphago_model
from keras.callbacks import ModelCheckpoint
import ppy
rows, cols = 19, 19
num_ classes = rows * cols
num_games = 10000
encoder = AlphaGoEncoder()
processor = GoDataProcessor(encoder=encoder.name())
generator = processor.load_go_data('train', num_games, use_generator=True)
test_generator = processor.load_go_data('test', num_games, use_generator=True)
接下來,我們可以使用本節之前定義的
alphago_model
函式來載入AlphaGo的策略網路,並采用分類交叉熵損失函式和隨機梯度下降法來對這個 Keras 模型進行編譯,如程式碼清單 13-6所示。我們把這個模型稱為
alphago_sl_policy
,以表示它是一個采用監督學習(sl是supervised learning的簡寫)的策略網路。
程式碼清單13-6 用Keras建立一個AlphaGo策略網路
input_shape = (encoder.num_planes, rows, cols)
alphago_sl_policy = alphago_model(input_shape, is_policy_net=True)
alphago_sl_policy.compile('sgd', 'categorical_crossentropy', metrics=['accuracy'])
現在第一階段的訓練只剩下最後一步了。和第7章一樣,使用訓練生成器和測試生成器對這個策略網路呼叫
fit_generator
。除網路更大、編碼器更復雜之外,其他地方都和第6章至第8章完全一樣。
訓練結束後,我們可以從
model
和
encoder
建立一個
DeepLearningAgent
,並把它儲存起來(如程式碼清單13-7所示),以備後面討論的兩個訓練階段使用。
程式碼清單13-7 訓練一個策略網路並持久化儲存
epochs = 200
batch_size = 128
alphago_sl_policy.fit_generator(
generator=generator.generate(batch_size, num_ classes),
epochs=epochs,
steps_per_epoch=generator.get_num_samples() / batch_size,
validation_data=test_generator.generate(batch_size, num_ classes),
validation_steps=test_generator.get_num_samples() / batch_size,
callbacks=[ModelCheckpoint('alphago_sl_policy_{epoch}.p')]
)
alphago_sl_agent = DeepLearningAgent(alphago_sl_policy, encoder)
with ppy.File('alphago_sl_policy.p', 'w') as sl_agent_out:
alphago_sl_agent.serialize(sl_agent_out)
為簡潔起見,在本章中我們並不需要像AlphaGo論文所說的那樣分別訓練強策略網路和快策略網路。我們不另外單獨訓練一個更小更快的策略網路,而是直接使用alphago_sl_agent作為快策略網路。下一節會介紹如何以這個代理為起點進行強化學習,生成一個更強的策略網路。
讀到這裏還想繼續探索,可以閱讀【深度學習與圍棋】

1.本書是一本人工智慧的實踐性入門教程,成功地把AlphaGo這個人工智慧領域中最激動人心的裏程碑之一,轉化為一門優秀的入門課程;
2.采用Keras深度學習框架,用Python來實作程式碼;
3.內容全面,層次劃分細致,基本上將AlphaGo背後所有的理論知識都覆蓋了;
4.提供配套原始碼。
圍棋這個古老的策略遊戲是AI研究的特別適用的案例。2016年,一個基於深度學習的系統戰勝了圍棋世界冠軍,震驚了整個圍棋界。不久之後,這個系統的升級版AlphaGo Zero利用深度強化學習掌握了圍棋技藝,輕松擊敗了其原始版本。讀者可以透過閱讀本書來學習潛藏在它們背後的深度學習技術,並構建屬於自己的圍棋機器人!
本書透過教讀者構建一個圍棋機器人來介紹深度學習技術。隨著閱讀的深入,讀者可以透過Python深度學習庫Keras采用更復雜的訓練方法和策略。讀者可以欣賞自己的機器人掌握圍棋技藝,並找出將學到的深度學習技術套用到其他廣泛的場景中的方法。











