某種程度來說,其實是一樣的,都是SMP(對稱多處理器,Symmetric MultiProcessing),對於作業系統來說,每個核心都是作為單獨的CPU對待的。所以在某個地方省事了,就必須在另外一個地方費勁。
不同的核心執行多個執行緒,總有需要交換數據的時候,根源為不同的核心需要存取同一個記憶體地址的數據——而核心Core0要存取這個地址的數據時,可能已經被核心Core2載入到緩存中並進行了修改。雖然理論上可以讓Core2把緩存數據同步到記憶體後,Core0再從記憶體讀取數據,但記憶體存取的速度比CPU速度慢很多,一般是直接存取Core2的緩存。
因此,不管是單個CPU多核心,還是多個單核心CPU,或者多個多核心CPU,都必須有這樣的數據通道:
- 每個核心都可以存取全部記憶體
- 每個核心都可以存取其它核心的緩存
- 針對現代CPU整合了PCI-E控制器,大部份IO裝置都可以使用DMA方式傳輸數據,可以把每個PCI-E控制器看待為若幹個特殊的核心。
以Intel最新的至強可延伸第二代(Cascade Lake)架構為例,單個多核心CPU的架構是這樣的[1]:
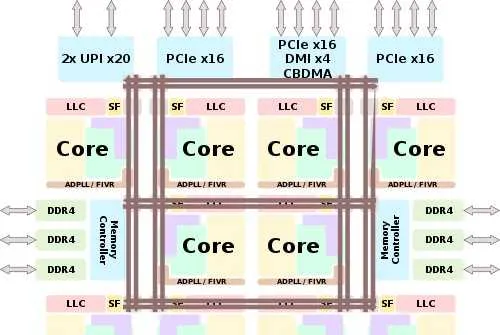
10個核心,以及PCI-E控制器、記憶體控制器透過網狀匯流排互聯。因為Cascade Lake支持多路CPU,因此還有一個UPI匯流排控制器。
現在基本沒有單核心CPU了,兩個多核心CPU互聯是這樣的[1]:
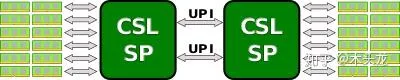
可以想象出來,第一個CPU的某個核心(假設是Core 0-1)要存取第二個CPU的另一個核心(假設是Core 1-3)的緩存,途徑為:
Core 0-1->Mesh匯流排->UPI控制器->UPI匯流排->UPI控制器->Mesh匯流排->Core 1-3
Core 0-1存取第二個CPU的某個記憶體地址:
Core 0-1->Mesh匯流排->UPI控制器->UPI匯流排->UPI控制器->Mesh匯流排->記憶體控制器
很顯然這個流程比單CPU內的多核心互訪麻煩多了,延遲也會更高。此外,CPU需要增加UPI控制器;主機板需要增加第二個CPU插槽以及必須的供電模組、散熱模組;增加第二個CPU的記憶體插槽;兩個插槽之間布線聯通UPI控制器(單個UPI x20控制器需要使用80根線,2x UPI x20就是160根)。體會一下同樣是CSL用的單路主機板和雙路主機板的差異:



而且2x UPI x20的頻寬也比Mesh互聯的頻寬低不少(Mesh互聯的頻寬不好算,也沒找到資料,但Mesh互聯的前身Ring匯流排互聯的頻寬是96GB/s,2x UPI x20頻寬根據工作頻率大概在76.8~83.2 GB/s,但和Ring相比,各種新聞稿都說Mesh平均延遲大幅降低,頻寬大幅提升)。
所以,CPU核心是省事了些,但是CPU封裝以及主機板則是費勁多了,而且通常來說這個效能可能更差一些。當然,兩個CPU會有其它方面的優勢,例如整個平台的記憶體可以大一倍,多一倍的PCI-E通道可以連線更多的PCI-E裝置,總核心數量相同的前提下,單個CPU功耗相近的時候每個核心可分配到的功耗更高,每個核心可以執行在更高的頻率。
在生產方面,CPU只要一次設計好了,生產兩個10核心和生產一個20核心的生產流程、原材料成本幾乎是沒有差別的,也許20核心因為使用更大的晶圓面積良品率低一點,但封裝兩個CPU也會帶來更高的成本。而單路主機板的設計、生產、成本都低的多,換句話說整個平台成本更低更具價格競爭力。
多說一句,AMD的8核銳龍、執行緒撕裂者、EPYC則是把這兩種方式的優勢組合起來,只生產4核心的CCX,每兩個CCX組合成一個Zeppelin模組。然後執行緒撕裂者和EPYC則是多個Zeppelin模組在CPU的基板上透過Infinity Fabric匯流排互聯。CCX的良率更高,配套主機板的生產成本也低不少,只是封裝的成本會有所提高。當然,這樣多個Zeppelin模組在基板上互聯和多個CPU互聯相似,存在不同CCX上的核心互訪延遲高頻寬低的缺點,執行執行緒間需要頻繁交換數據的多執行緒套用時效率比Intel的Core X/至強要低。
[1]:Cascade Lake - Microarchitectures - Intel - WikiChip











