正好手頭有個demo,這裏盡量用最簡單的思路介紹一下。
說明,這個是給零基礎的同學看的,不需要任何電腦基礎。
同樣,這個處理思路忽略了非常多的細節,只是為了讓大家更好地理解原理而已。
1。首先看下如何提取特征,看這麽多數位,眼睛都花了。
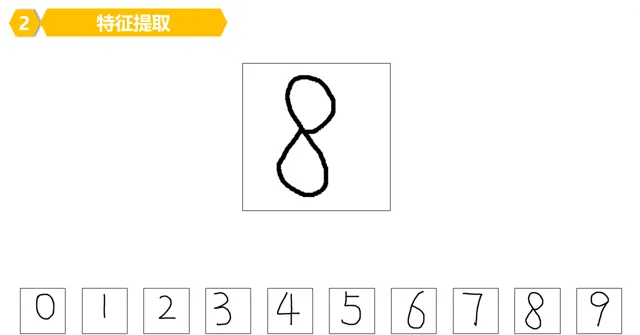
2。簡單說就是把數位劃分成很多很多的小塊,比如下圖這樣:
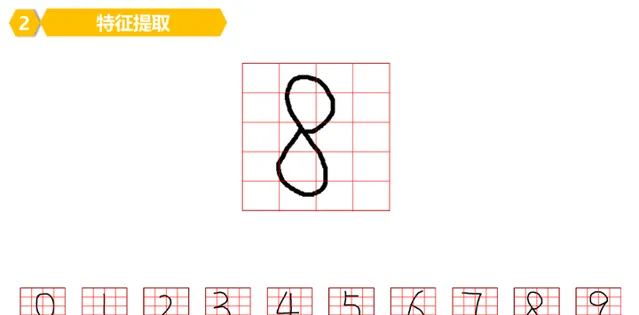
每個數位被劃分成了4*5=20個小塊。
分好了小塊以後,其實我們要知道每個小塊是由很多個像素構成的。
或者這樣理解,每個小塊其實可以劃分為更多的小塊,即每個小塊是由很多個更小的塊構成的。
比如每個小塊可能是100*100個更小的小塊構成的。
為了敘述上的方便,把小塊記為B(Bigger),更小的塊記為S(Smaller)。
因此,比如數位8,是由5行4列共計:5*4=20個小塊B構成。
每個小塊B內其實是由100*100=100000個像素(更小塊S)構成的。
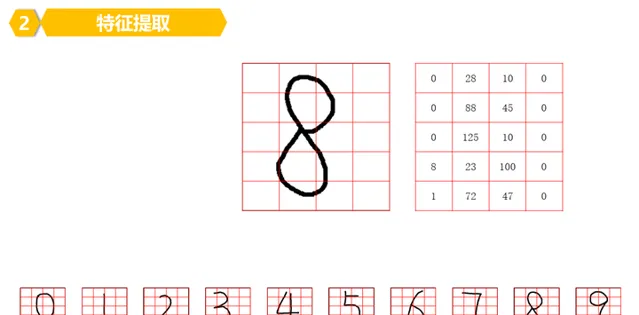
3。數一下每個小塊B內,有多少個黑色的像素。
或者這樣理解,每個小塊B內有多少個更小塊S是黑色的。
比如第一行:
以此類推,可以計算出每一行的每一個小塊B的數位是多少,寫好就好了。
這就是數位的特征,如果仔細觀察,每個數位的特征是不一樣的。
因為他們的每個小塊B內的數位是不一致的。
4。為了方便,我們把得到的特征,排成一排(陣列)就好了。
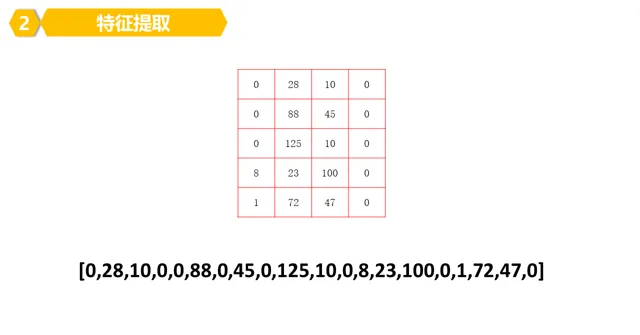
5。所以,我們可以看看數位8的特征,其實就是一堆數位(陣列)構成的。
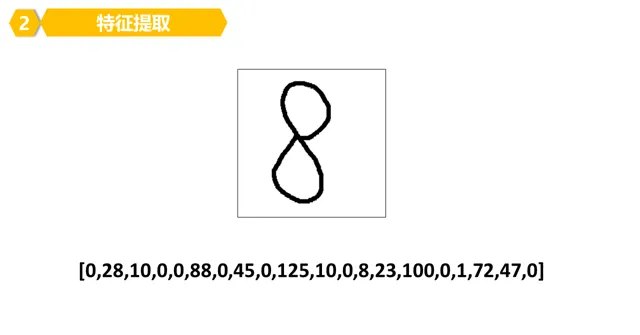
6。照著葫蘆畫瓢,每個數位的特征其實都是一堆數位構成的。
這個數位類似於我們的身份證號碼,一般來說,是獨一無二的。

7。那辨識是怎麽回事呢?
就是比較要辨識的數位特征和步驟6中的哪個數位的特征最接近就好了。
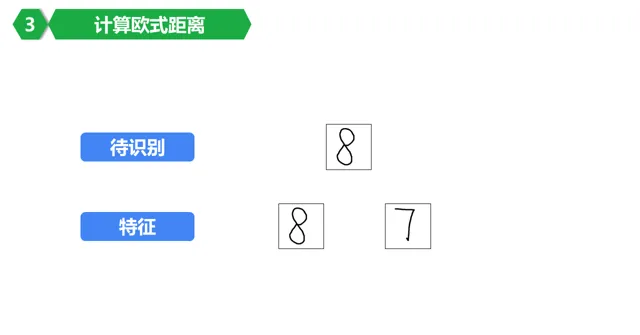
這裏為了方便,假設要辨識數位「8」,然後看看怎麽從一堆(為了方便只有兩個)數位裏面選出來他到底應該是幾?
8。當然,為了方便,特征簡化了,我們假設每個數位只有4個特征值了。
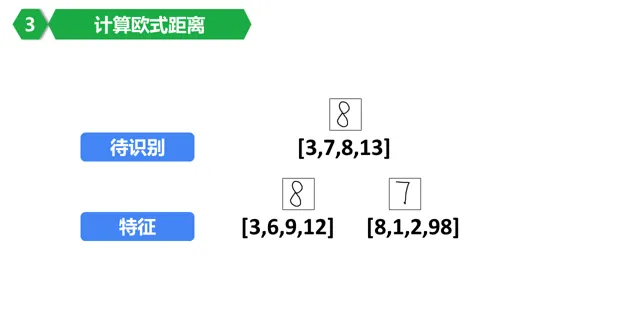
9。這裏要用到一個歐氏距離的概念。
簡單點說,就是有一個罪犯,經過警察叔叔的縝密偵查,發現他的身高 約 是175cm(透過腳印就可以判斷出身高,大家自己百度一下)。
警察過來抓人了,兩個已知嫌疑人,一個A身高176cm,另外一個B身高168厘米。
那我計算一下,取絕對值就好了:
那當然,罪犯就是身高176cm的A了。
當然,由於當前不僅僅有身高,還有體重,那就要綜合計算身高和體重了。
為了更好地計算,就用到公式:
看起來很復雜,簡單說就是把所有的差值取平方和後開根號。
這就是一種計算方法,不理解原理其實也沒有關系,總之就是計算一下,知道怎麽計算就行了。

10。看看罪犯和嫌疑人的相似程度。
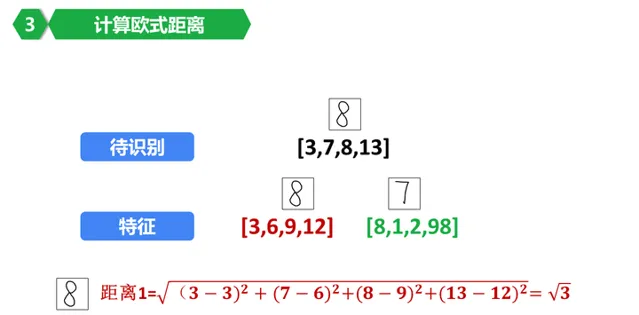
好了,計算一下要辨識的這個影像(圖中待辨識右側的8,這裏我們假裝不認識他)和資料庫裏面保存的數位8的歐式距離吧!

恩,計算就是把每個對應的特征值相減,取平方,計算和,開根號。
得到結果,當前結果是根號3.
11。再次計算罪犯和另外一個嫌疑人的相似程度。
好了,計算要辨識的影像和資料庫裏面的數位7的特征值進行比較。
恩,綠色部份是我們的計算結果,根號7322.
12。辨識
罪犯和嫌疑人的計算差異值,一個是根號3,另外一個是根號7322.
距離小的是辨識結果。
這裏,根號3是辨識結果,所以,要辨識的影像是數位8.
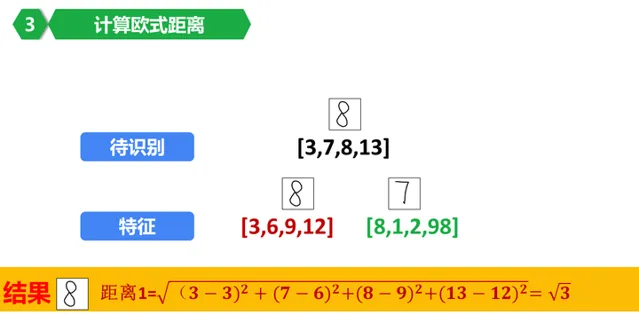
這就是辨識過程了。
可以用圖表示一下:
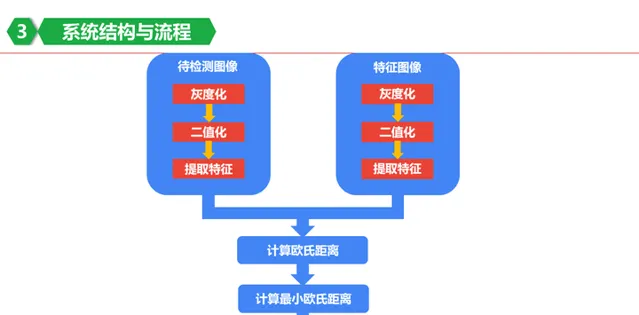
在提取特征前,影像可能是彩色的,就先把他處理為二值的,這樣好方便計算其中黑色小塊的個數。
寫得比較匆忙,歡迎大家對細節提出改進意見。謝謝。
版權所有,轉載請私信聯系。
本文已經寫入【OpenCV輕松入門】(電子工業出版社,2019)、【電腦視覺40例】(電子工業出版社,2022)。











