編輯:LRST
【新智元導讀】剛剛,一款專為消費級顯卡設計的全新非自回歸掩碼影像建模的文本到影像生成模型——Meissonic釋出,標誌著影像生成即將進入「端側時代」。
最近,YouTube和Reddit上出現了一個引起廣泛討論的影像生成模型,來自日本、南韓、美國、印度、中東和英國的網友們紛紛參與討論。

Youtube熱烈討論
那麽,這到底是怎麽回事呢? 讓我們一起來看看吧。
近年來,大語言模型在自然語言處理領域取得了巨大的突破,以LLaMA和Qwen等為代表的模型展現了強大的語言理解和生成能力。
但是,影像生成技術的突破主要得益於擴散模型,如Stable Diffusion XL在影像品質、細節和概念一致性方面設立了事實標準。
然而,這些擴散模型與自回歸語言模型的工作原理和架構顯著不同,導致在視覺和語言任務上實作統一生成方法面臨挑戰。這種差異不僅使這些模態的整合變得復雜,還凸顯了需要創新的方法來彌合它們之間的差距。
自回歸文本到影像模型(如LlamaGen)透過預測下一個token生成影像,但由於生成的影像token數量龐大,自回歸模型在效率和分辨率上也面臨瓶頸,難以套用到實際場景。於是,一些Masked Image Modeling(MIM)技術,例如MaskGIT和MUSE被提出。這些方法展現了高效影像生成的潛力。
盡管MIM方法具有一定的前景,它們仍面臨兩個關鍵限制:
1. 分辨率限制
當前的MIM方法只能生成最大分辨率為512×512像素的影像。這一限制阻礙了它們的廣泛套用和進一步發展,尤其是在文本生成影像的社群中,1024×1024分辨率逐漸成為標準。
2. 效能差距
現有的MIM技術尚未達到領先擴散模型如SDXL所表現的效能水平,特別是在影像品質、復雜細節和概念表達等關鍵領域表現不佳,而這些對實際套用至關重要。
這些挑戰需要探索新的創新方法,Meissonic的目標是使MIM能夠高效生成高分辨率影像(如1024×1024),同時縮小與頂級擴散模型的差距,並確保其計算效率適合消費級硬體。
Meissonic模型提出了全新的解決方案,基於非自回歸的掩碼影像建模(MIM),為高效、高分辨率的T2I生成設定了新標準。

論文連結: https://arxiv.org/abs/2410.08261
GitHub Code: https://github.com/viiika/Meissonic
Huggingface Model: https://huggingface.co/MeissonFlow/Meissonic
透過架構創新、先進的位置編碼策略和最佳化的采樣方法,Meissonic不僅在生成品質和效率上與領先的擴散模型(如SDXL)相媲美,甚至在某些場景中超越了它們。
此外,Meissonic利用高品質的數據集,並透過基於人類偏好評分的微觀條件進行訓練,同時引入特征壓縮層,顯著提升了影像的保真度與分辨率。

以下是Meissonic在方法上的幾項重要技術改進:
1. 增強型Transformer架構
Meissonic結合了多模態與單模態的Transformer層,旨在捕捉語言與視覺之間的互動資訊。從未池化的文本表示中提取有用訊號,構建兩者之間的橋梁;單模態Transformer層則進一步細化視覺表示,提升生成影像的品質與穩定性。研究表明,這種結構按1:2比例能夠實作最佳效能。
2. 先進的位置編碼與動態采樣條件
為保持高分辨率影像中的細節,Meissonic引入了旋轉位置編碼(RoPE),為queries和keys編碼位置資訊。RoPE有效解決了隨著token數量增加,傳統位置編碼方法導致的上下文關聯遺失問題,尤其在生成512×512及更高分辨率影像時。
此外,Meissonic透過引入掩碼率作為動態采樣條件,使模型自適應不同階段的采樣過程,進一步提升影像細節和整體品質。
3. 高品質訓練數據與微觀條件
Meissonic的訓練依賴於經過精心篩選的高品質數據集。為提升影像生成效果,Meissonic在訓練中加入了影像分辨率、裁剪座標及人類偏好評分等微觀條件,顯著增強了模型在高分辨率生成時的穩定性。
4. 特征壓縮層
為了在保持高分辨率的同時提升生成效率,Meissonic引入了特征壓縮層,使其在生成1024×1024分辨率影像時可以有效降低計算成本。
那麽,Meissonic到底有多強大呢?讓我們來看看它的表現:
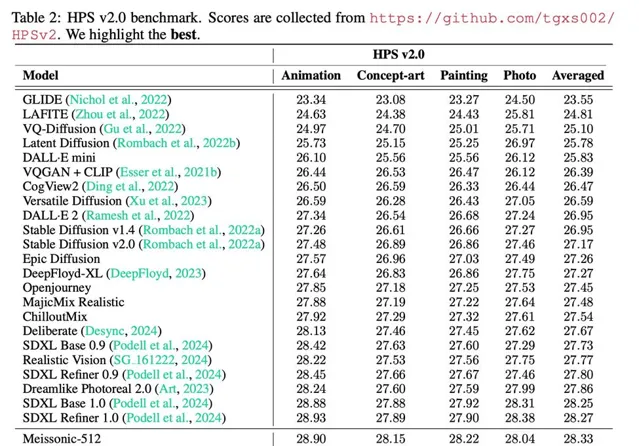
在HPS V2.0基準測試中,Meissonic以平均0.56分的優勢超越了SDXL。
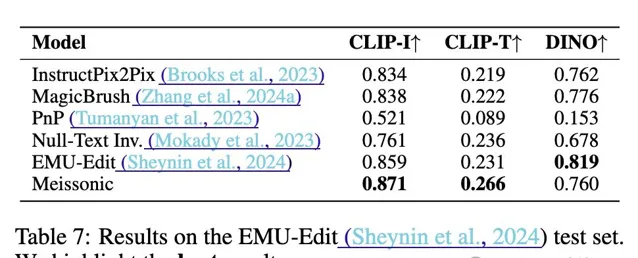
在影像編輯能力評測數據集Emu-Edit上,Meissonic的Zero-shot影像編輯效能甚至超越了經過影像編輯指令微調後的模型。

在風格多樣性生成方面,Meissonic展現出超越SDXL的表現。
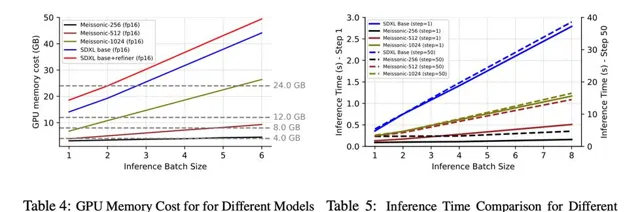
而這一切,都只需SDXL 1/3的推理時間和1/2的視訊記憶體占用。值得註意的是,Meissonic可以在8GB視訊記憶體下執行,讓中低端顯卡的使用者也能受益。
此外,Meissonic還展現了超強的zero-shot影像編輯能力,無需微調即可靈活編輯有mask和無mask的場景,提供了更多創作可能性。


高效推理與訓練的結合
在文本到影像合成領域,Meissonic模型憑借卓越的效率脫穎而出。該模型不僅在推理過程中實作了高效性,同時在訓練階段也顯著提升了效率。Meissonic采用了一套精心設計的四階段訓練流程,逐步提升生成效果。
階段一:理解影像基礎概念
研究表明,原始LAION數據集的文本描述無法充分滿足文本到影像模型的訓練需求,通常需要多模態大型語言模型(MLLM)進行最佳化,但這消耗大量計算資源。
為此,Meissonic在初始階段采用了更加平衡的策略,利用經過篩選的高品質LAION數據學習基礎概念,透過降分辨率的方法提高效率,最終保留約2億張高品質影像,並將初始訓練分辨率設定為256×256。
階段二:實作文本與影像對齊
第二階段的重點在於提升模型對長文本描述的理解能力。團隊篩選了審美分數高於8的影像,構建了120萬對最佳化後的合成圖文對及600萬對內部高品質圖文對。此階段,訓練分辨率提升至512×512,配對數據總量達到約1000萬對,從而顯著提升了Meissonic在處理復雜提示(如多樣風格和虛擬角色)以及抽象概念方面的能力。
階段三:實作高分辨率影像生成
在Masked Image Modeling(MIM)領域,生成高分辨率影像仍然是一個挑戰。Meissonic透過特征壓縮技術高效實作了1024×1024分辨率的影像生成。引入特征壓縮層後,模型能夠在較低計算成本下實作從512×512到1024×1024的平滑過渡,此階段的數據集經過進一步篩選,僅保留約600萬對高分辨率、高品質的圖文配對,以1024分辨率進行訓練。
階段四:精細化美學細節生成
在最後階段,Meissonic透過低學習率微調模型和文本編碼器,並引入人類偏好評分作為訓練條件,進一步提升了生成影像的品質和多樣性。這一階段的訓練數據與第三階段保持一致,但更加註重對高分辨率影像生成的美學細節的打磨。
透過上述四個階段的訓練,Meissonic在訓練數據和計算成本上實作了顯著降低。具體而言,在訓練過程中,Meissonic僅使用210萬張影像,相較於其他主流模型(如SD-1.5和Dall-E 2),訓練數據的使用量顯著減少。
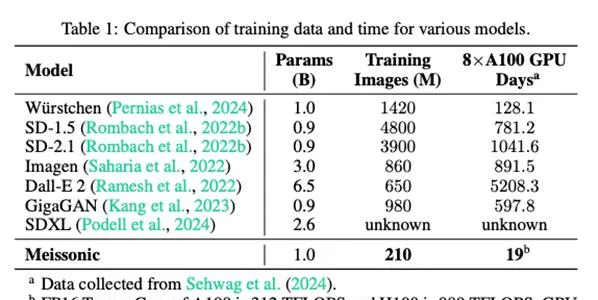
在使用8個A100 GPU進行訓練的情況下,Meissonic的訓練時間僅需19天,顯著低於Würstchen、SD-2.1等模型的訓練時間。
廣泛影響
最近,行動裝置上的端側文本到影像套用如谷歌Pixel 9的Pixel Studio和蘋果iPhone 16的Image Playground相繼推出,反映出提升使用者體驗和保護私密的日益趨勢。作為一種資源高效的文本到影像基座模型,Meissonic在這一領域代表了重要的進展。
此外,來自史丹佛大學的創業團隊Collov Labs在一周內就成功復現出同樣架構的Monetico,生成效果可以與Meissonic相媲美,推理效率更加高效,並榮登huggingface趨勢榜第一名。這也顯示出Meissonic架構在資源高效上的巨大潛力和套用價值。
參考資料:
https://arxiv.org/abs/2410.08261











