OpenAI聖誕季「十二連發」的第三個工作日,迎來了重頭戲——萬眾期待的OpenAI視訊生成模型Sora正式版釋出!
OpenAI官方甚至直言 :「Sora就是我給你們的假期禮物。」
今年2月,Sora首次問世便以其卓越的表現震撼了科技屆。而此次OpenAI釋出更高級的Sora Turbo,在生成視訊的速度和效果上,顯然更快、更強!
01 Sora的創新表現
整體來說,Sora展示的一系列功能,在視訊生成的品質、功能的獨創性、技術的復雜度等方面,超出了目前市場上已有的文生視訊產品。
OpenAI在直播中介紹,Sora支持從480p到1080p的全系列分辨率,單個視訊最長可達20秒。使用者可以透過文本描述(文生視訊)、圖片(圖生視訊)以及現有視訊(視訊生視訊)來生成視訊內容。
特別值得一提的是,Sora上線全新UI界面以及豐富的編輯工具,以便創造者對視訊進行修改、建立、擴充套件、迴圈、混合。
例如,Storyboard(故事板)允許使用者透過時間軸來控制視訊內容,添加分鏡頭,以及調整動作或畫面的持續時長。Re-cut(剪輯)是在故事板上對視訊進行修剪和延展,實作更精確的視訊編輯。Blend(混合)則是將兩個視訊內容進行過渡和融合,創造出新的視覺效果。
02 Sora的技術原理
OpenAI已經給我們展示了Sora的「全能前進演化」。這些獨特的創新功能極大地拓展了創作者的創作空間,讓視訊更接近創作者的自我表達、幫助他們完成一個理想的鏡頭故事。
如此強大的功能背後有哪些黑科技,Sora是怎麽做到的?
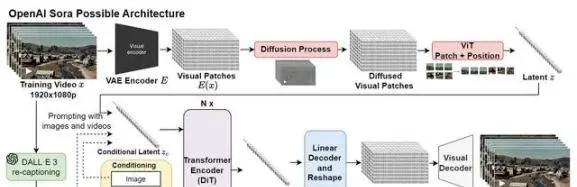
Sora的設計靈感來源於大型語言模型(LLM),透過訓練互聯網規模數據來獲得通用能力。大語言模型使用文本標記,而Sora則使用之前已被證明是用於視覺數據模型的有效表示的視覺「碎片/修補程式」(patches)來達到類似效果。
OpenAI首先透過對視訊進行時間和空間上的壓縮,將其壓縮到一個更低維的潛在空間(可將這個潛在空間看做是時空碎片的集合),然後將原視訊轉化為這些碎片/修補程式(patches)。讓它們充當像轉換器中的標記符號一樣的角色,使Sora模型可以在不同分辨率、持續時間和寬高比的視訊和影像數據集上進行訓練。
然後,Sora利用一種基於Transformer的模型,根據給定的文本提示和已經提取的空間時間修補程式,開始生成最終的視訊內容。在這個過程中,模型會「塗改」初始的雜訊視訊,逐步去除無關資訊,添加必要細節,最終生成與文本指令相匹配的視訊。
此外,訓練從文本到視訊的生成系統,還需要大量帶有對應文本字幕的視訊。為此,OpenAI借鑒了DALL-E 3中提出的re-captioning技術,將其套用到視訊上。首先訓練了一個高度描述性的字幕模型,之後用它為訓練數據集中的所有視訊生成文本字幕,以此來提加文本逼真度以及視訊的整體品質。
03 文生視訊模型背後的數據
總的來說,Sora模型憑借其強大的數據處理能力和深度學習能力,成功地將文字與視訊內容緊密地聯系在一起,為使用者帶來了前所未有的視訊生成體驗。這個模型就像是AI的「大腦」,裏面儲存了海量的視訊和影像資訊。透過不斷學習這些數據,模型得以建立對現實世界中各類場景、情境、運動規律以及人類活動特征的深度理解和精準捕捉。
其中,高品質視訊訓練數據在提升輸入文字與生成內容匹配度方面扮演著至關重要的角色。不僅能夠提升模型的效能,還能夠為使用者提供更加真實、準確和連貫的視訊生成體驗。
標貝科技始終專註於為企業提供高品質的精標數據服務以及豐富的多模態數據資源。針對大模型數據需求,我們精心打磨了多模態大模型數據解決方案,覆蓋從數據采集、預處理、清洗、標註到質檢等系列工程化流程,積累了高品質的多模態大模型訓練數據集,為客戶打造優質的服務體驗。
04 標貝科技多模態大模型訓練數據-視訊caption數據集
視訊caption數據樣例1:生活類
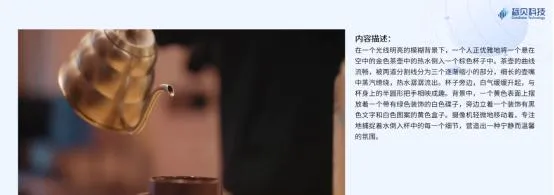
視訊caption數據樣例2:運動類

視訊caption數據樣例3:動物類

視訊caption數據樣例4:其他

歡迎聯系我們了解多模態大模型訓練數據集更多詳情!











