編輯:LRST
【新智元導讀】研究人員提出了一種新方法,利用類階層中的最低公共祖先(LCA)距離來評估深度學習模型的泛化能力,這比傳統的準確率指標更有效。此外,透過基於LCA距離的軟標簽訓練,模型在面對分布外數據時的準確率得到了顯著提升,同時不影響其在訓練數據上的效能。
當前許多深度學習分類模型通常在大規模數據中訓練以找到足以區分不同類別的特征。
然而,這種方式不可避免地學到偽相關特征(Spurious Correlation),導致訓練的分類器在分布偏移(Distribution Shift)下往往會失效。因此,如何在衡量一個訓練好的模型的泛化性(Generalization)一直是一個關鍵問題。
現有方法通常利用Accuracy-on-the-Line作為模型泛化性的一個指標,即利用驗證集的top-1 accuracy來衡量模型在分布偏移下的效能,該指標在同類模型中較為有效,但面對不同型別的模型(如視覺模型和視覺語言模型)時,往往無法統一而有效地預測泛化效能。
卡內基梅隆大學等機構的研究人員提出了一種新的泛化性評估方法:利用類階層( class Hierarchy)中的最低公共祖先距離(Lowest Common Ancestor Distance, LCA Distance)來判斷模型是否學到了更「合理」的特征。

論文地址:https://arxiv.org/pdf/2407.16067
計畫地址:https://elvishelvis.github.io/papers/lca/
同時,透過基於LCA距離構建的額外損失函式,可以在OOD測試集上顯著提高模型準確率,最高可達6%,且對分布內效能無負面影響。研究還發現,VLM學習到的特征分布更接近人類的語意定義,為解釋VLM泛化性更好的現象提供了新的視角。
該研究已被ICML 2024接收為Oral Presentation,論文的第一作者史佳現任Google旗下自動駕駛公司Waymo研究工程師,從事基礎模型(Foundation Models)的研究與套用;論文為史佳在卡耐基梅隆大學攻讀電腦視覺碩士期間的研究成果;指導教授孔庶現任澳門大學助理教授。
判別式學習:偽相關特征的陷阱
大多數分類模型只關註訓練數據中區分不同類別的所有元素(例如背景顏色、有無天空等),而不考慮這些元素是否與類別語意定義一致。
導致模型易於依賴訓練數據中的偽相關特征,比如:
相比之下,具備更強泛化性的模型會關註諸如「長腿」和「長頸」等更符合人類對鴕鳥語意定義的特征,而非依賴背景等偽相關資訊。
LCA距離:衡量泛化效能的新視角
研究人員認為,透過語意階層(如WordNet)可更準確衡量模型是否學到語意一致的特征。
LCA距離的思路
LCA距離用於衡量兩個類在給定的語意階層中的距離。例如,類別「鴕鳥」與「火烈鳥」的語意比「鴕鳥」與「獵豹」的語意距離更接近。
當衡量真實類別與預測類別時,更小的LCA距離意味著即使模型預測錯誤,也更傾向於預測與真實類別在語意上更為接近的類別,從而體現模型對更符合語意特征的關註。
LCA距離為何有效?
LCA距離本質上反映了模型與人類先驗知識的對齊程度(alignment),能展示模型學習的特征是否符合人類語意定義。語意更接近的錯誤預測(即更小的LCA距離)意味著模型學到了更具泛化性的特征。
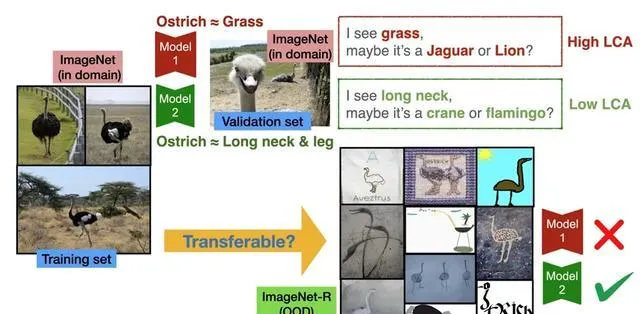
當模型學到與人類語意定義更一致的特征時,即便預測錯誤,也更可能落在語意相近的類別上
傳統「Accuracy-on-the-Line」的局限性
過去,「Accuracy-on-the-Line」假設認為模型在分布內(In-Distribution, ID)測試集上的準確率可用於預測其在分布外(Out-of-Distribution,OOD)測試集上的效能。
對傳統視覺模型(Vision Models,VMs)而言,這種關系在一定程度上成立。然而,引入視覺-語言模型(Vision-Language Models,VLMs)後,情況出現了轉變。
VLMs使用大規模多模態數據和不同的訓練範式(如從互聯網影像與文本中進行訓練)。
結果顯示,VLMs在ID準確率較低的同時展現出更高的OOD準確率,並與VMs形成了兩條截然不同的趨勢線(如下圖左圖所示),破壞了Accuracy-on-the-Line中的線性關系。因此,傳統的ID準確率指標已無法統一衡量這兩類模型的泛化效能。
LCA-on-the-Line:LCA距離是一種更統一的泛化性指標
透過LCA距離分析模型錯誤預測的語意距離,可判斷模型是否依賴於偽相關特征。實驗顯示,分布內測試集上的LCA距離與模型在OOD測試集上的效能之間存在強相關性。
在實驗中,研究物件包括36個VMs和39個VLMs,以ImageNet為分布內測試集(ID dataset),並在包括ImageNet-Sketch、ObjectNet在內的五個分布偏移測試集(OOD datasets)上測試。結果顯示:
- 恢復線性關系:與傳統ID準確率不同,LCA距離在所有OOD測試集上均表現出更強的線性相依性(如下圖右圖所示)。例如,在ObjectNet上,LCA距離與OOD效能的相關性達到0.95,而ID準確率僅為0.52。
- VLMs的優勢:盡管部份VLMs在ID數據上的表現不及VMs,但其LCA距離明顯更低,顯示出在泛化性上的明顯優勢。
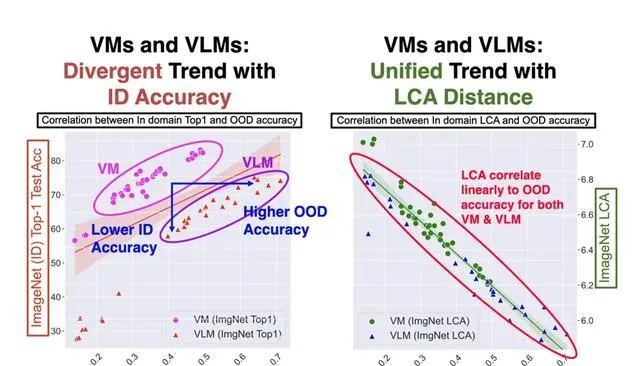
LCA距離是一種更統一的泛化性指標
LCA距離透過軟標簽提升模型泛化效能
傳統分類任務中,模型通常采用 單熱編碼(One-Hot Encoding) 與 交叉熵損失(Cross-Entropy Loss) 訓練。這隱含了一個強假設:真實類別之外的所有類別相互等同,且應賦予相同的低機率。
單熱編碼過度強調類別間的區分,這可能導致模型即使在語意相近的類別(如「貓」和「狗」)之間,也努力最大化分類邊界,從而增加對偽相關特征(如背景)的依賴,而忽略了類別間的共享特征。
為了解決此問題,研究人員基於LCA距離引入 軟標簽(Soft Labels) ,為語意更近的類別賦予更高權重。例如,真實類別為「狗」時,與其語意接近的「貓」可能獲得0.7的權重,而與「飛機」僅有0.1。
這一策略使模型的學習目標得到正則化,引導其關註語意一致的特征,從而減少對偽相關特征的依賴。
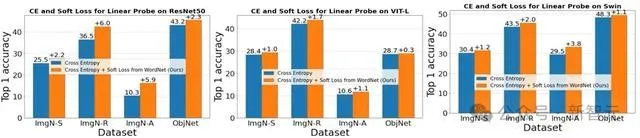
實驗顯示,LCA距離引導的軟標簽可顯著提升模型在OOD測試集上的泛化效能,準確率可提升最多6%,且不影響ID準確率。
泛化到任何數據集:從WordNet到隱式階層
雖然LCA距離最初依賴WordNet等預定義類階層,但並非所有數據集都有現成的階層。對此,本研究論文提出了一種簡單的自動生成隱式階層(Latent Hierarchy)的方法:
- 特征提取:使用預訓練模型提取每個類別的平均特征向量。
- 層次聚類:對這些特征進行分層K-mean聚類,構建類別關系的階層。
- LCA距離計算:基於隱式階層計算類別間的LCA距離。
-
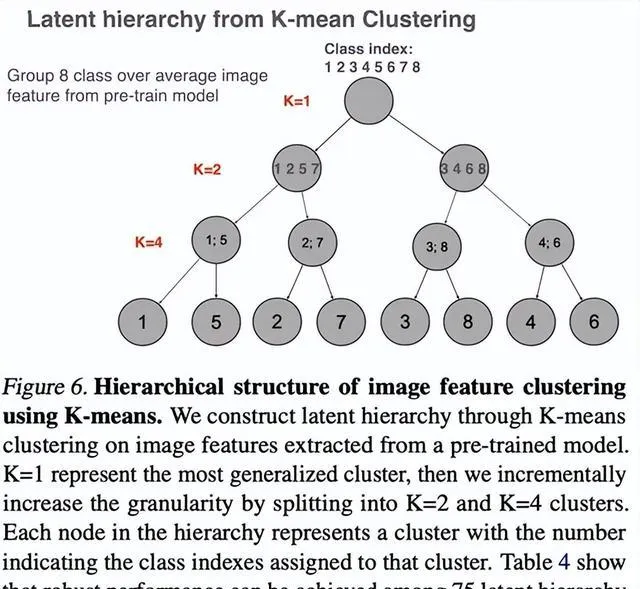
實驗顯示,使用不同預訓練模型生成的隱式階層所計算的LCA距離在OOD泛化效能預測(下圖左圖)與提升(下圖右圖)方面與基於WordNet的階層具有類似效果,說明LCA距離具有普適性,能夠適應無預定義階層的數據集。

為什麽VLM泛化性更好?
此項研究還為解釋VLM泛化效能優勢提供了新的思路:VLM的高層次特征分布更符合人類語意定義。
實驗顯示,使用VLM生成的隱式階層所生成的軟標簽在提升模型泛化效能方面優於VM。
這說明VLM所學習的特征分布更接近人類語意,從而在OOD場景下表現更為出色。

X軸反映了不同的預訓練模型生成的隱式結構提高模型泛化性的程度,由此可見,VLM生成的隱式結構能夠更好的提高模型泛化性。
總結與展望
LCA距離是統一的泛化性指標
只依賴模型預測的類別間LCA距離,不受訓練數據分布、模型結構或temperature等參數的影響。因此,它能夠統一衡量包括VM和VLM在內的多種模型的泛化能力,並且計算高效。
LCA距離可提升泛化效能
基於LCA距離引入軟標簽可以引導模型關註與人類別定義更為語意一致的特征,從而有效減少對偽相關特征的依賴,並有望在few-shot、預訓練(pre-trained)等場景中加速模型收斂。
LCA距離提供了解釋VLM泛化效能的新思路
實驗顯示VLM所學習的特征分布更貼近人類語意定義,幫助解釋為何VLM在OOD測試中表現更優。
LCA距離體現了模型與人類先驗知識的對齊
本文研究中使用的WordNet可替換為任何包含先驗資訊的語意層級或知識圖譜,這一特性有望套用於其他與對齊(alignment)相關的任務。
參考資料:
https://arxiv.org/pdf/2407.16067











