編輯:alan
【新智元導讀】 近日,來自微軟的研究人員開源了使用全新方法訓練的MoE大模型,不走尋常路,且編碼和數學表現出色。
繼Phi家族之後,微軟又開源了新的混合專家大模型——GRIN MoE。
與Phi-3.5同樣的個頭(16 * 3.8B),卻采用了截然不同的訓練方法。
這個「不走尋常路」如果寫個太長不看版,那就是兩句話:
1. 使用新一代SparseMixer來精確估計專家路由的梯度,解決傳統方案中利用門控梯度代替路由梯度的問題。
2. 專家並列不要了,訓練中改用數據、pipeline和張量並列,避免了傳統方法丟棄token的問題。

論文地址:https://arxiv.org/abs/2409.12136
當然了,上面兩句話是小編說的,多少有點糙,文中細節,還請諸君繼續閱讀~
這年頭,新來一個LLM,當然要先刷分了——
參數要少,效果要好,所以要在左上角:
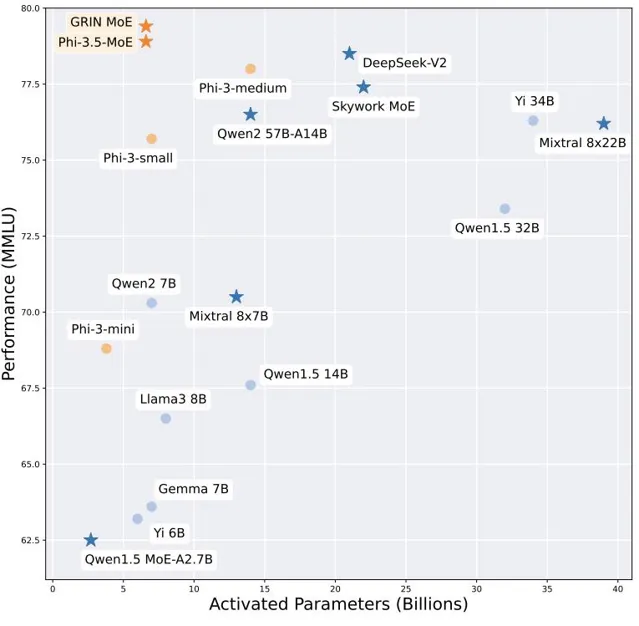
GRIN作為MoE架構,總參數量約42B,推理時啟用的參數為6.6B,打同級別(7B)的非MoE模型是手拿把攥,甚至比14B的Phi-3還要略勝一籌。
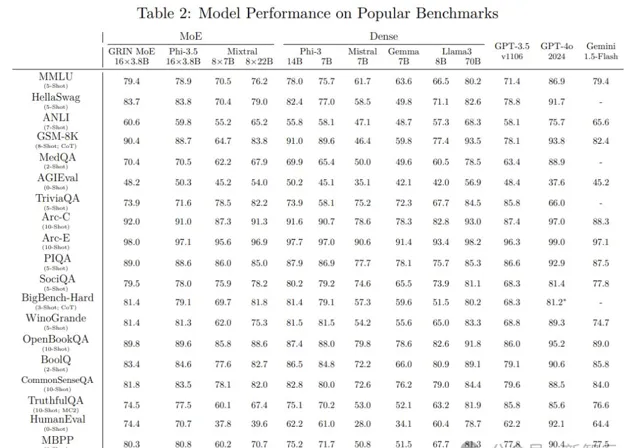
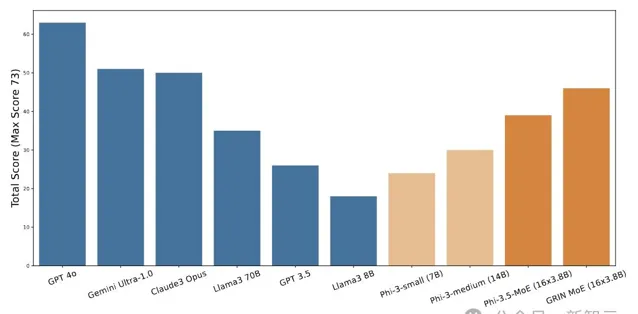
在上面的這份成績單中,GRIN MoE表現優異,尤其是在編碼和數學測試中。
比如,在衡量數學問題解決能力的GSM-8K中,GRIN MoE得分為90.4,而在編碼任務基準HumanEval上拿到了74.4分。
在MMLU(大規模多工語言理解)基準測試中GRIN得分為79.4,超過了同為MoE架構的Mixtral(70.5分),以及自家的Phi-3.5(78.9分)。
如果對比流行的商用模型,GPT-3.5表示感受到時代的力量,默默結束群聊。

開放權重:https://huggingface.co/microsoft/GRIN-MoE
demo:https://github.com/microsoft/GRIN-MoE
MoE全新訓練路徑
GRIN MoE由常規的Transformer塊構成,采用分組查詢註意力(GQA)和滑動視窗註意力來提高計算效率。
采用RoPE進行位置編碼,以便在預訓練後實作長上下文能力。

在MoE架構中,模型透過路由網路為每個輸入token挑選適合的專家模組。對於有n個專家的網路,一個用於推理的MoE模組的輸出為:
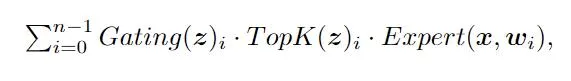
其中z = Router (x,r),本文中Router采用線性網路,Gating是門控函式(通常為softmax),Expert是FNN層。
MoE透過TopK函式進行專家分配,這個專家路由的過程是不可微的,所以 反向傳播 的時候沒法求導。
對此,傳統的MoE訓練將TopK視為常數,僅透過Gating來反向傳播計算路由權重梯度,相當於用門控的梯度代替了路由的梯度。
這多少有點糙。
不可導怎麽辦
恰好,本文一作之前有一篇工作(SparseMixer):

論文地址:https://arxiv.org/pdf/2310.00811
受到直通梯度估計器的啟發,作者擴充套件了前作,提出了SparseMixer-v2。
作者首先將TopK函式替換為模型訓練中離散變量的隨機采樣,然後套用heun’s third order method來近似專家路由梯度,並構建一個改進的反向傳播,為專家路由給出數學上合理的梯度估計。

前作中,SparseMixer的有效性在神經機器轉譯任務和ELECTRA語言模型訓練中得到了證明。
而在GRIN MoE的開發過程中,SparseMixer-v2終於有機會大規模套用於自回歸語言模型訓練。
作者用2.5T token訓練了兩個16×0.9B MoE。其中一個遵循GRIN MoE中使用的相同方案,另一個用傳統的GShard方法替換 SparseMixer-v2。
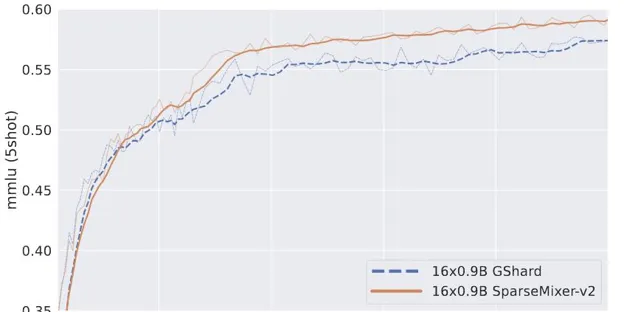
如上圖所示,將SparseMixer-v2的效能提升推廣到16×0.9B尺度的自回歸語言模型訓練。
在前0.5T token上GShard表現更好,但SparseMixer-v2在訓練後期取得了更強的效能。
專家模型不要專家並列
傳統的MoE訓練采用專家並列,簡單理解就是把不同的專家分配到不同的顯卡上。
一個明顯的問題是負載不均衡,有的專家會分到更多的token,有的專家卻很閑。
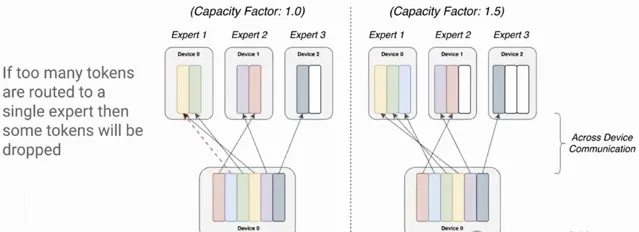
之前的做法是設定一個閾值,比如1000個token分給4個專家,每人應該是250,這時候每張卡就最多只算250個token,超過後直接丟棄(送到下一層)。
而在本文中,作者利用數據並列、pipeline並列和張量並列來訓練GRIN MoE。
此外,對於沒有專家並列性的MoE計算,作者發現 Megablocks 包非常有用,它的grouped_GEMM內核和包裝器的效能更好。
套用這些新的工程化方法避免了專家並列,也就不用丟棄token了。
最終,與具有相同啟用參數的密集模型相比,本文的方法實作了超過80%的訓練效率提升。

上表中,作者將兩種不同大小的MoE模型與具有相同啟用參數量的密集模型進行了比較,使用相同的硬體測量了它們的訓練吞吐量。
盡管MoE總的參數量是密集模型的六倍多,但在實驗中達到了超過80%的相對吞吐量,證實了使用GRIN MoE方法的模型具有顯著的計算擴充套件潛力。
(PS:密集模型的吞吐量是在與MoE模型相同的並列度設定下測量的,這裏的比較是為了研究密集啟用網路(非MoE)和稀疏啟用網路(MoE)的GPU內核效率)
此外,在擴大模型大小時,密集模型和MoE模型顯示出相似的減速模式,比如6.6B密集模型的訓練吞吐量大約比1.6B密集模型的訓練吞吐量慢4.19倍(後者的參數少4倍)。同樣,42B MoE模型的訓練吞吐量比10B MoE 模型的訓練吞吐量慢約3.96倍(對應參數少4.2倍)。
並列實驗
在只使用pipeline並列的情況下,透過在GPU之間進一步劃分不同層,可以將最大專家數量從16個擴充套件到32個。但是,如果再增加專家數量,則會導致單個層的參數過多,一個GPU就放不下了。
所以下一個維度采用張量並列。
專家並列在前向和後向計算中有兩個all-to-all通訊開銷,而張量並列在前向和後向計算中有兩個all-reduce通訊開銷。
相比之下all-reduce操作的延遲更高一點,但可以透過精心排布前向和反向的計算來overlap掉一部份開銷。
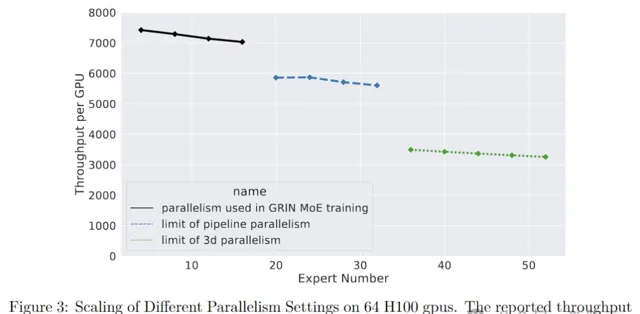
如上圖所示,透過結合pipeline並列和張量並列,系統支持的最大專家數量擴充套件到52個(總共132B參數)。
這個數量是因為實驗只用了64個GPU,最多能將模型劃分為64個階段,如果有更多的GPU,那麽還能繼續向上擴充套件。
不過作者也表示,使用更復雜的並列通常會導致計算吞吐量降低。
負載均衡
如前所述,本文沒有采用專家並列,但是負載不均衡的事實依然存在。
作者在這裏透過調整負載均衡損失來調節全域的負載均衡。常見的負載均衡損失定義為:
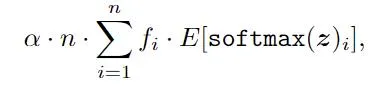
其中α是超參數,n是專家數量,fi是排程給專家的token比例。
傳統方法在本地不同的GPU上計算fi,因此負載均衡損失將調節本地專家負載均衡並緩解token丟棄。
在本文中,作者透過計算全域的fi(比如數據並列過程中組內的all-reduce)來修改負載均衡損失,調節專家負載以達到全域平衡。
盡管這種調整會產生額外的通訊開銷,但類似於張量並列,這些通訊也可以與計算overlap,從而在很大程度上減少額外的延遲。
最後,放一個測試結果來show一下GRIN MoE的數學推理能力:
作者註:我們對新釋出的 GAOKAO (即全國普通大學和學院入學統一考試)的數學問題進行案例研究,這是中國一年一度的全國本科入學考試。
該考試以其嚴格的安全協定而聞名,是評估AI模型回答數學問題的能力的理想測試平台。請註意,GRIN MoE的訓練於太平洋標準時間6月3日結束,2024年GAOKAO於中國標準時間6月7日開始。










